CNN
第一周:
title: edge detection example
卷积核在边缘检测中的应用,可解释,卷积核的设计可以找到像素列突变的位置
把人为选择的卷积核参数,改为学习参数,可以学到更多的特征
title: padding
n * n图片,k*k卷积核,输出图片是( n - k + 1) * ( n - k + 1)
n-k+1可以理解
padding补零,保持图像尺寸,理解,padding的0的个数就是k -1,也就是上面的式子损失的维度
title: Strided Convolutions
步长可调
信号处理的卷积,要先把卷积核沿两个轴反转,神经网络里面所称的卷积没有这一步,实际上是卷积核和信号的互相关,
反转使卷积运算保持了结合律的特性
title: Convolutions Over Volume
对于三维的信号,卷积核也要三维
三维的在对应位置相乘
存在多个卷积核的时候,就把结果叠在一起(假如维度一样,同一层应该是必须一样的
6*6*3(hwc)图片,3*3*3的卷积核,输出4*4*1
就是每一步下,各个通道的卷积做好了相加起来,con(1)+con(2) + con(3)变成4*4*1里面的一个值
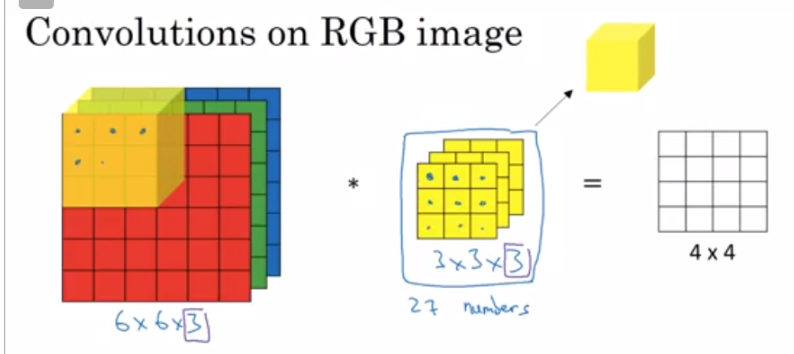
多个卷积核的情况下,需要把每个4*4再stack到一起变成4*4*卷积核数 的张量
n*n*nc的图片,f * f * nc的单个卷积核,nc就是channel, 输出是 (n-f+1) * (n-f+1) * nc', nc'是卷积核的数量,也代表下一层的nc
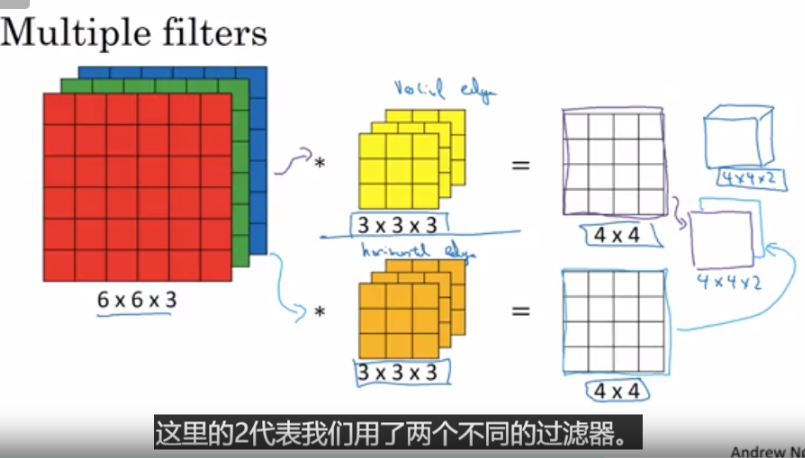
title:One Layer of a Convolutional Network
可以加bias,加非线性函数relu之类的
cnn的参数个数和卷积核的大小以及数量有关,但是和图像大小无关,能控制参数的多少
title:Simple Convolutional Network Example
注意到一层的输出的深度,和这层的卷积核的数量有关,卷积核越多,深度越大,最后如果没有padding,我们的图像在长宽会变小,在深度(厚度)会很深
在cnn层之后会有池化层,全连接层,如果是分类问题
title: Pooling Layers
max pooling, 用区域里的最大值,代表这块区域,相当于把矩阵的尺寸压缩了,有参数f,所划分的最小块区域的大小,stride,移动步长
pooling的解释还挺强行的吧,算了算了
pooling有超参数,没有学习参数
average pooling, 区域里的平均值
一般卷积层后面都跟着池化层

title: why cnn
cnn的优势:参数少
参数共享,一个卷积核里的参数应用到了所有的像素(信号)上
稀疏性,输出的一个格子只由前面的t个格子所决定,不像全连接是所有格子决定的,所以涉及到的参数少
第二周 case study
title:Classic Networks
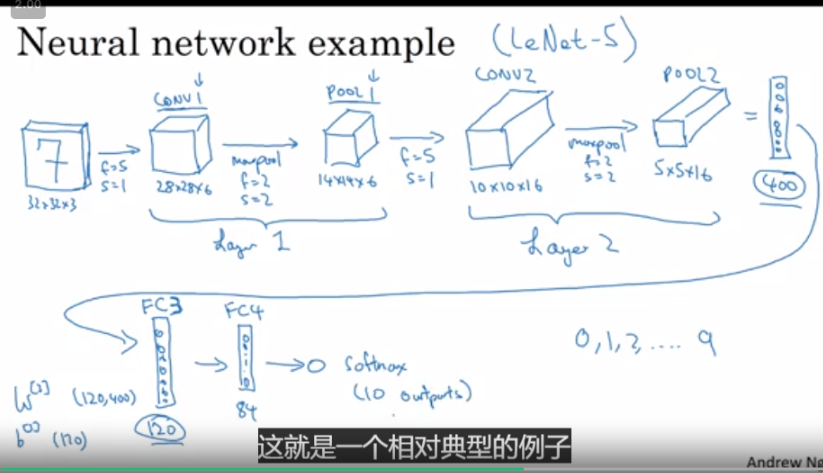
1. LeNet-5:没有啥特点,就和我经常见到的cnn一样,卷积-池化-卷积-池化-全连接
2.AlexNet: 和LeNet结构非常像,就是层数更多了,参数更多了,然后使用了relu
3.VGG-16:还是一样的阿
这三种网络基本上,k * 卷积层----池化层----t * 卷积层-----池化层 -----全连接。。。。
title: ResNet
残差网络,上一层的输入加了一条short path,直接输入当前层神经网络的激活函数里
本身应该走的路还是要走的,但是多了一条路直接保存了上一层的输入信息
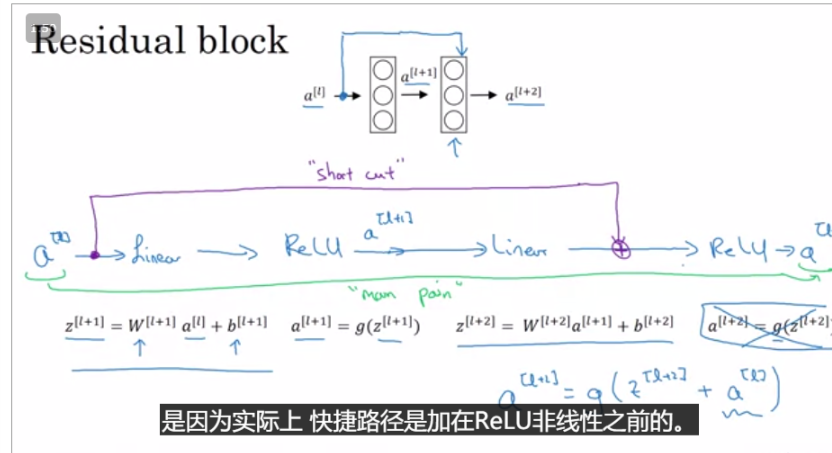
ResNet的主要优点是,实验显示就算层数加深了,他的loss也不会随着迭代的增加而反弹,如果没有ResNet的结构,就有可能会反弹
这个解释呢,是因为residual block非常容易学习恒等函数,让某一层的输出等于前面某一层的输入,如果没有学习到恒等函数,那么有可能学习到一些对我们有用的东西。
就算都学到恒等函数,对整个网络的表现影响也不大。
title: 1* 1卷积层
可以减少channel 数量,某种程度上相当于全连接
可以减少运算量,作为中间层,bottleneck layer
title: Inception Network Motivation
在一层里使用多个卷积核,甚至是池化,然后把结果堆叠在一起