1 深拷贝浅拷贝
1.1 a==b与a is b的区别
- a == b 比较两个对象的内容是否相等(可以是不同内存空间)
- a is b 比较a与b是否指向同一个内存地址,也就是a与b的id是否相同
1 >>> a = 1 2 >>> b = 1 3 >>> a == b 4 True 5 >>> a is b 6 True 7 >>> a = 257 8 >>> b = 257 9 >>> a is b 10 False
出于对性能的考虑,Python内部做了很多的优化工作,对于整数对象,Python把一些频繁使用的整数对象缓存起来,保存到一个叫small_ints的链表中,在Python的整个生命周期内,任何需要引用这些整数对象的地方,都不再重新创建新的对象,而是直接引用缓存中的对象。Python把这些可能频繁使用的整数对象规定在范围[-5, 256]之间的小对象放在small_ints中,但凡是需要用些小整数时,就从这里面取,不再去临时创建新的对象。因为257不再小整数范围内,因此尽管a和b的值是一样,但是他们在Python内部却是以两个独立的对象存在的,各自为政,互不干扰。
1 >>> c = 257 2 >>> def foo(): 3 ... a = 257 4 ... b = 257 5 ... print a is b 6 ... print a is c 7 ... 8 >>> foo() 9 True 10 False
Python程序由代码块构成,代码块作为程序的一个最小基本单位来执行。一个模块文件、一个函数体、一个类、交互式命令中的单行代码都叫做一个代码块。在上面这段代码中,由两个代码块构成,c = 257作为一个代码块,函数foo作为另外一个代码块。Python内部为了将性能进一步的提高,凡是在一个代码块中创建的整数对象,如果存在一个值与其相同的对象于该代码块中了,那么就直接引用,否则创建一个新的对象出来。Python出于对性能的考虑,但凡是不可变对象,在同一个代码块中的对象,只有是值相同的对象,就不会重复创建,而是直接引用已经存在的对象。因此,不仅是整数对象,还有字符串对象也遵循同样的原则。所以 a is b就理所当然的返回True了,而c和a不在同一个代码块中,因此在Python内部创建了两个值都是257的对象。
- l2 = l1,相当于l2也指向与l1的内存地址,修改l1的值,l2也会跟着改变
1 l1 = [1,1,1,1,2,3,4,5] 2 l2 = l1 #浅拷贝, l1和l2指向同一个内存地址 3 print(id(l1)) #查看内存地址 4 print(id(l2)) 5 for i in l2: 6 if i%2!=0: 7 l1.remove(i) #删除奇数 8 print(l1) #循环删list的时候,会导致下标错位,结果是不对的
运行结果如下:
42001160
42001160
[1, 1, 2, 4]
1.2 浅拷贝
import copy
l1 = [1,1,1,1,2,3,4,5]
l2 = l1 #浅拷贝, l和l2实际指向同一个内存地址
l3 = l1.copy() #浅拷贝
print(id(l1), id(l2), id(l3))
ll1 = [[1,2,3],[4,5,6]]
ll2 = ll1 #浅拷贝, l和l2实际指向同一个内存地址
ll3 = ll1.copy() #浅拷贝
print(id(ll1), id(ll2), id(ll3))
运行结果如下:
36164360 36164360 36164552
36165704 36165704 36165640
- 解析
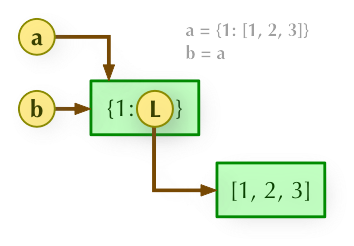
1、b = a: 赋值引用,a 和 b 都指向同一个对象
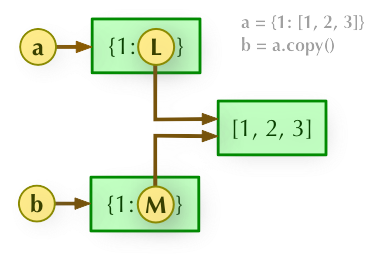
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
1 import copy 2 a = [1, 2, 3] 3 b = [4, 5, 6] 4 c = [a, b] 5 d = copy.copy(c) 6 print(id(c)) 7 print(id(d))
42500296 42500232
1 import copy 2 a = [1, 2, 3] 3 b = [4, 5, 6] 4 c = (a, b) 5 d = copy.copy(c) 6 print(id(c)) 7 print(id(d))
35510088 35510088
- 浅拷贝可变类型(比如列表),第一层的列表也会拷贝
- 浅拷贝不可变类型(比如元祖),d指向c的内存地址
1.3 深拷贝
1 import copy 2 l = [1,1,1,2,3,4,5] 3 l2 = copy.deepcopy(l)# 深拷贝
- 解析
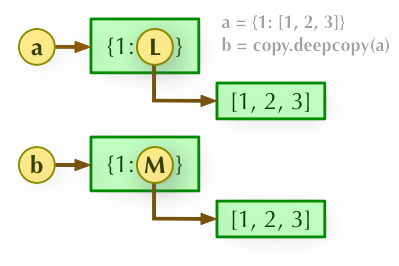
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
2 函数
2.1 函数定义
1 def db_connect(ip,port=3306): #1.位置参数,必填;2.默认值参数 2 print(ip,port) #函数体
1 def my3(): 2 a = 1 3 b = 2 4 c = 3 5 return a,b,c 6 7 b,c,d = my3() 8 s = my3() 9 print(b,c,d) 10 print(s)
运行结果:
1 2 3
(1, 2, 3)
2.2 return作用
1、结束函数,只要函数里面遇到return,函数立即结束运行
2、返回函数处理的结果
- 例:判断一个字符串是否是小数(含正小数和负小数)
1 def check_float(s): 2 ''' 3 这个函数的作用就是判断传入的字符串是否是合法的小数 4 :param s: 传入一个字符串 5 :return: True/false 6 ''' 7 s = str(s) 8 if s.count('.')==1: 9 s_split = s.split('.') 10 left,right = s_split 11 if left.isdigit() and right.isdigit(): 12 return True 13 elif left.startswith('-') and left[1:].isdigit() 14 and right.isdigit(): 15 return True 16 return False #上面的几个条件未满足,则会走到这一步 17 18 print(check_float(1.3)) 19 print(check_float(-1.3)) 20 print(check_float('01.3')) 21 print(check_float('-1.3')) 22 print(check_float('-a.3')) 23 print(check_float('a.3')) 24 print(check_float('1.3a3')) 25 print(check_float('---.3a3'))
2.3 可变参数
1 def send_sms(*args): #可变参数,参数组 2 #1、不是必传的 3 #2、它把传入的元素全部都放到了一个元组里面 4 #3、不限制参数个数 5 #4、它用在参数比较多的情况下 6 for p in args: 7 print(p) 8 9 send_sms() 10 print('-----------------------------') 11 send_sms(1861231231) 12 print('-----------------------------') 13 send_sms(1861231231,1232342,42342342)
运行结果:
-----------------------------
1861231231
-----------------------------
1861231231
1232342
42342342
2.4 关键字参数
1 def send_sms2(**kwargs): 2 #1、不是必传的 3 #2、不限制参数个数 4 print(kwargs) 5 6 send_sms2() 7 send_sms2(name='xiaohei',sex='nan') 8 send_sms2(addr='北京',country='中国',c='abc',f='kkk')
运行结果:
{}
{'name': 'xiaohei', 'sex': 'nan'}
{'addr': '北京', 'country': '中国', 'c': 'abc', 'f': 'kkk'}
2.5 参数顺序
1 def my(name,country='China',*args,**kwargs): 2 #1、位置参数 2、默认值参数 3、可变参数 4、关键字 3 print(name) 4 print(country) 5 print(args) 6 print(kwargs) 7 my('xiaojun','Japan','beijing','天通苑',color='红色', 8 age=32)
运行结果:
xiaojun
Japan
('beijing', '天通苑')
{'color': '红色', 'age': 32}
2.6 全局变量
1 name = 'wangcan'#全局变量 2 names = [] 3 def get_name(): 4 names.append('hahaha') 5 name = 'hailong' 6 print('1、函数里面的name',name) 7 8 def get_name2(): 9 global name #声明name是全局变量 10 print('2、get_name2',name) 11 12 get_name2() 13 get_name() 14 print(names) 15 print('3、函数外面的name',name)
#运行结果: 2、get_name2 wangcan 1、函数里面的name hailong ['hahaha'] 3、函数外面的name wangcan
1 name = 'wangcan'#全局变量 2 def get_name3(): 3 name = '我是谁' #不会对全局变量产生作用 4 print(name) 5 get_name3() 6 print(name)
#运行结果: 我是谁 wangcan
2.7 函数调用
1 def db_connect(ip, user, password, db, port): 2 print(ip) 3 print(user) 4 print(password) 5 print(db) 6 print(port) 7 8 db_connect(user = 'abc', port= 3306, db = 1, ip = '234234', password = '123456') #记不住顺序可以这样调用 9 db_connect('192','root', db = 2, password = '234', port = 45)#这样也行, 混搭, 但'192','root'必须按顺序写在前面
3 递归
函数自己调用自己
递归最多999次
效率没有循环高
1 #阶乘 1 × 2 × 3 × ... × n 2 def fact(n): 3 if n==1: 4 return 1 5 return n * fact(n - 1)
4 集合
1、天生可以去重
2、集合是无序
- 集合定义
1 jihe = set()
- 集合例子
1 l=[1,1,2,2,3,3] 2 res = set(l) 3 print(res)
#运行结果:集合
{1, 2, 3}
4.1 交集、并集、差集、对称差集
1 xingneng =['tanailing','杨帆','liurongxin','小黑'] 2 zdh = ['tanailing','杨帆','liurongxin','小军','海龙'] 3 xingneng = set(xingneng) 4 zdh = set(zdh) 5 #取交集 6 res1 = xingneng.intersection(zdh)#取交集 7 res2 = xingneng & zdh #取交集 8 #取并集 9 res3 = xingneng.union(zdh) #取并集,把2个集合合并到一起,然后去重 10 res4 = xingneng | zdh 11 #取差集 12 res5 = xingneng.difference(zdh) #取差集,在a里面有,在b里面没有的 13 res6 = xingneng - zdh #取差集 14 #取对称差集 15 res7 =xingneng.symmetric_difference(zdh)#两个里不重复的值 16 res8 = xingneng ^ zdh 17 18 print(res1) 19 print(res2) 20 print(res3) 21 print(res4) 22 print(res5) 23 print(res6) 24 print(res7) 25 print(res8)
#运行结果
{'liurongxin', '杨帆', 'tanailing'}
{'liurongxin', '杨帆', 'tanailing'}
{'tanailing', 'liurongxin', '小军', '海龙', '杨帆', '小黑'}
{'tanailing', 'liurongxin', '小军', '海龙', '杨帆', '小黑'}
{'小黑'}
{'小黑'}
{'海龙', '小军', '小黑'}
{'海龙', '小军', '小黑'}
4.2 其他方法
1 import string 2 l1 = set(string.ascii_lowercase) 3 l2 = {'a','b','c'} 4 print(l2.issubset(l1)) #子集 5 print(l1.issuperset(l2)) #父集 6 print(l1.isdisjoint(l2)) #有交集,返回False, 没有交集,返回True
#运行结果 True True False
1 l2 = {'a','b','c'} 2 l2.add('s') #增 3 print(l2) 4 5 l2.remove('a') #删 6 print(l2) 7 8 l2.pop()#随机删 9 print(l2)
#运行结果:
{'c', 'a', 'b', 's'}
{'c', 'b', 's'}
{'b', 's'}