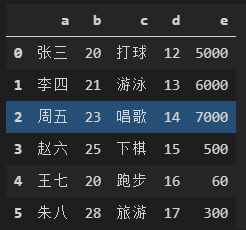
Excel表格数据,如下图:

--------------------------------------------------------------------------------------------------------------------
import numpy as np
import pandas as pd
file_name = r'E: mp mp.xlsx'
data = pd.read_excel(file_name)
data

--------------------------------------------------------------------------------------------------------------------
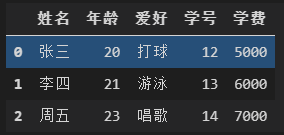
打印前3行数据
data.head(3)
--------------------------------------------------------------------------------------------------------------------
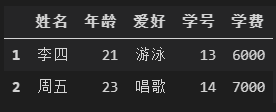
打印1-3行数据
data[1:3]
--------------------------------------------------------------------------------------------------------------------
根据列名打印某列
data['姓名']

--------------------------------------------------------------------------------------------------------------------
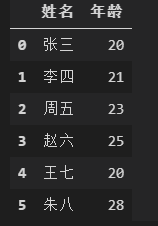
打印多个列,要用双层[[]]
data[['姓名','年龄']]
--------------------------------------------------------------------------------------------------------------------
查看所有字段
field = data.columns.tolist()
field

--------------------------------------------------------------------------------------------------------------------
只显示第4行
data.loc[4]
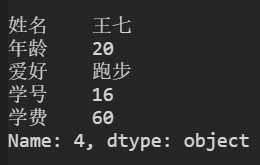
data.loc[4].values

--------------------------------------------------------------------------------------------------------------------
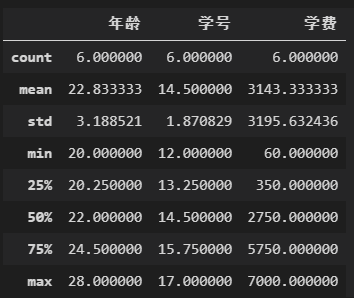
查看统计数据,只针对数值型
data.describe()
--------------------------------------------------------------------------------------------------------------------
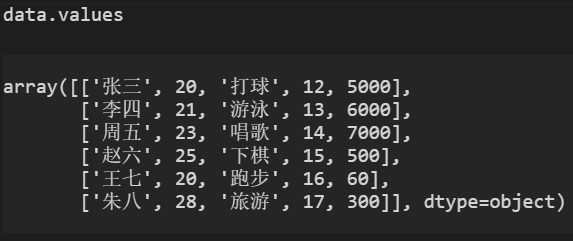
不读取Excel标题
data2 = pd.read_excel(file_name,header=None)
data2


-------------------------------------------------------------------------------------------------------------------------
pandas.read_excel参数说明:
pandas.read_excel(io,
sheet_name=0,
header=0,
skiprows=None,
skip_footer=0,
index_col=None,
names=None,
usecols=None,
parse_dates=False,
date_parser=None,
na_values=None,
thousands=None,
convert_float=True,
converters=None,
dtype=None,
true_values=None,
false_values=None,
engine=None,
squeeze=False,
**kwds)
1.io :excel 路径。
2.sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
3.header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None。
4.skiprows:省略指定行数的数据。
5.skipfooter:省略从尾部数的行数据
6.index_col :指定列为索引列,也可以使用 u’string’。
7.names:指定列的名字,传入一个list数据。
data3 = pd.read_excel(file_name, sheet_name=0, names=['a', 'b', 'c', 'd', 'e']) data3