今天主要学习内容是安装配置spark,次要学习内容是整理一下Hadoop,Hbase,hive。
因为今天试着启动了一遍进程,发现hbase的进程HMaster总是掉线,紧跟着HRegionServer也同时掉线了。无奈只好检查了一遍logs,发现报Permission denied的问题,那不用说,直接找到拒绝访问的文件夹,简单粗暴的来一个chmod 777,一般问题就全解决了(毕竟自己的电脑,权限管理不用太过严格)。然后再次启动,发现依旧掉线,删掉以前的log文件,再启动一次生成新的log文件,打开发现如下报错
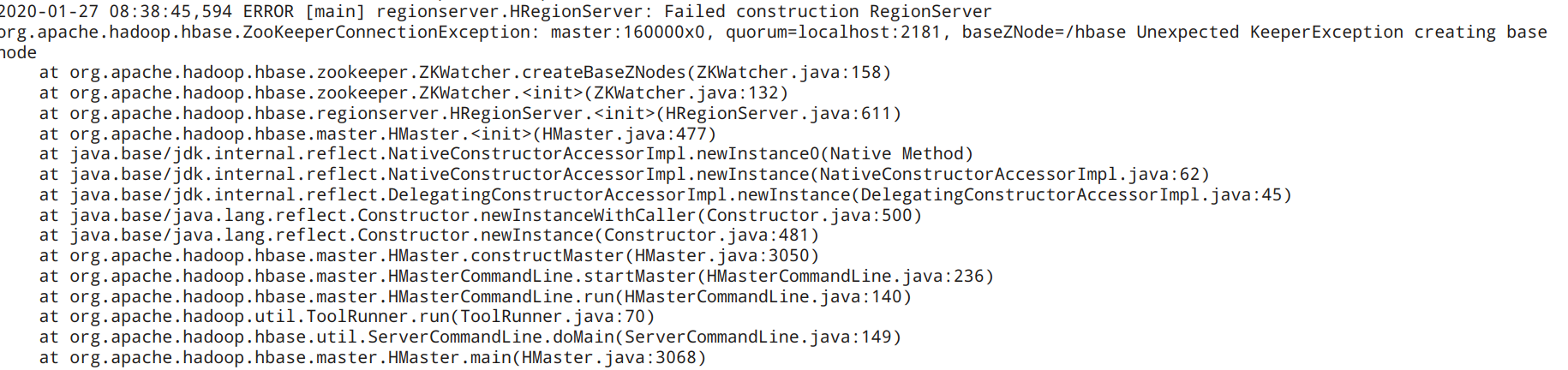
直接找到ERROR处,然后对照着错误突然想到由于当时hbsse自带的zookeeper总是出问题,于是我就自己下载了一个单独的zookeeper,把自带的zookeeper禁了,但自己下载的zookeeper没打开,所以出现了这样的错误。打开了zookeeper,hbase就可以正常启动了。
然后开始下载scala和spark,按照林子雨老师的教程(http://dblab.xmu.edu.cn/blog/1307-2/)结合上网搜索的一些适配表信息(https://blog.csdn.net/weixin_44033089/article/details/86588595),我下载了最新版的Scala和2.0.0的spark。Scala一切正常,使用没有任何问题。但spark配置完成后,运行林子雨老师的教程测试PI没有问题,却在运行spark-shell上报错了
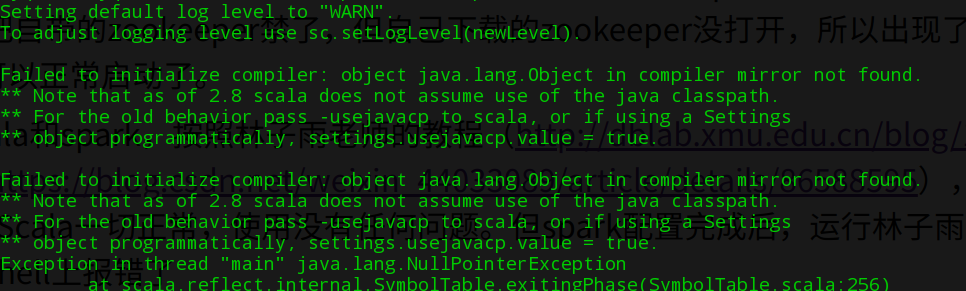
上网搜索,大部分的都是说jdk不匹配的原因,解决方案就是删除现有的jdk,安装一个低版本的jdk。删除是不可能删除的,毕竟系统上所有要用到jdk的地方都配置的是现有的jdk。突然我想起在安装系统时,系统有着自带的OpenJDK,而且我也没有删除。将jdk路径重新配置成了系统自带的OpenJDK,运行一下,成功!
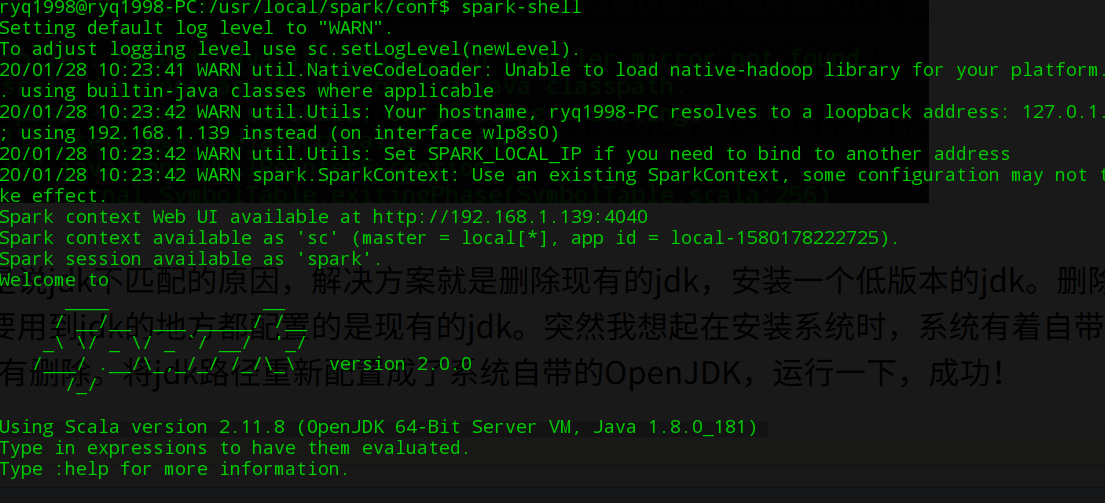
总结:遇到错误不要慌,看看log帮你忙。若是log不帮忙,百度大神一大帮。