1、概述
- 极大似然估计(Maximum Likelihood Estimation, MLE)
- 极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。
- 通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
- 极大后验估计(Maximum A Posteriori, MAP)
- 最大后验估计是根据经验数据获得对难以观察的量的点估计。
2、不同点
- 思想上的不同
- MLE:求怎样的参数 θ 可以让事件集发生的概率最大。通过不断改变固定的参数 θ 去寻找一个极大值。
- MAP:考量的是事件集 X 已经发生了,那在事件集发生的情况下,哪个 θ 发生的概率最大。
- 学派的不同
- MLE:频率学派
- MAP:贝叶斯学派
- 对参数 θ 的理解
- MLE:将 θ 当作一个确定的值,只是目前我们不知道,需要对其进行估计,这里 θ 是没有概率意义的
- MAP:将 θ 当作一个随机变量,θ 是有概率意义的,θ 有自己的分布,而这个分布函数,需要通过已有的样本集合 X 得到,即最大后验估计需要计算的是 P(θ|X)
- 计算公式
- MLE
- 似然函数
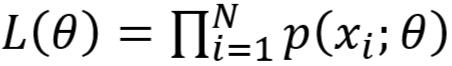
- 极大似然估计
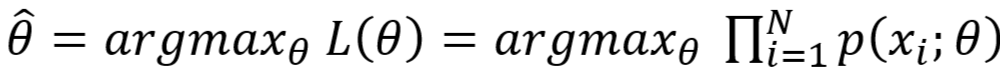
- 似然函数
- MAP
- 贝叶斯理论
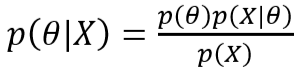
- 极大后验估计

- 上述极大后验估计不考虑贝叶斯公式分母 p(X) 是因为其相对于 θ 是独立的,可用直接忽略
- 贝叶斯理论
- MAP 中的 p(X|θ) 与 MLE 中的 p(X;θ) 是一样的,只是记法不一样
- MAP 和 MLE 的区别是:MAP 是在 MLE 的基础上加上了 p(θ)
- MLE
3、MAP 与 MLE 之间的关联与相互转换
- 详见笔记“MAP与正则化的关系“
