1、L2正则化
- 由最小二乘法得到的损失函数为
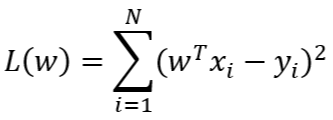
- 对于 L2 正则化,损失函数为

2、线性回归的极大后验估计(MAP)
- 假设
- 映射函数为 f(w)=wTx
- 真实标签与预测值之间的关系为:y=f(w)+ε=wTx+ε
- 其中 ε~N(0,σ2)
- 权重参数 w~N(0,σ02)
- 后验概率 p(w|y)=p(y|w)p(w)/p(y)
- 计算 w 的极大后验估计值

- 由假设可得
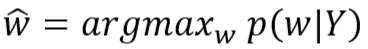

- 由假设可得
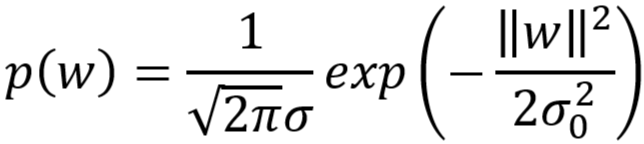
3、如上式推导结果,可得
- w 的极大后验 MAP 的估计值为
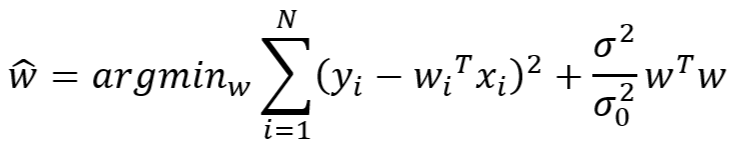
- w 的最小二乘法 MLE 的 L2 正则化后的估计值为
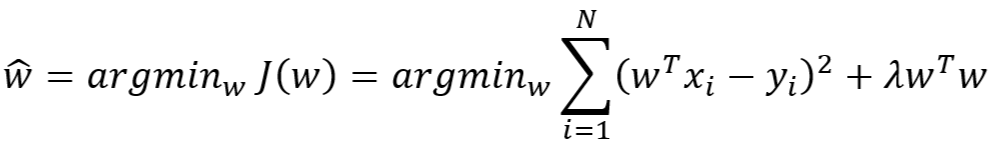
- 由上可知,在对权重参数 w 作概率分布假设 w~N(0,σ02) 的前提下,w 的 MAP 的估计值与 MLE 的 L2 正则化后的估计值形式相同
- 即,MAP 相当于添加了 L2 正则化后的MLE