一 子查询
子查询是一个完整的查询语句之中,嵌套若干个不同功能的小查询,从而一起完成查询。
复杂查询 = 限定查询 +多表查询 + 统计查询 + 子查询
子查询可以返回的数据类型一共分为四种:
子查询可以返回的数据类型一共分为四种: 单行单列:返回的是一个具体列的内容,可以理解为一个单值数据 单行多列:返回一行数据中多个列的内容 多行单列:返回多行记录之中同一列的内容,相当于给出了一个操作范围 多行多列:查询返回的结果是一张临时表
#WHERE子句: 此时子查询返回的结果一般都是单行单列,单行多列,多行多列 #HAVING子句: 此时子查询返回的都是单行单列数据,同时为了使用统计函数操作 #FROM子句: 此时子查询返回的结果一般都是多行多列,可以按照一张数据表(临时表)的形式操作
1. 查询公司之中工资最低的雇员的完整信息
SELECT * FROM emp WHERE sal=(select min(sal) from emp);
二 在WHERE子句中使用子查询
A.返回单行单列
1. 查询基本工资比“二宝”低的全部雇员信息


SELECT * FROM emp WHERE sal<(select sal from emp where ename='二宝');
2. 查询基本工资高于公司平均薪金的全部雇员信息
SELECT * FROM emp WHERE sal>(select avg(sal) from emp);
3.查询出与‘’李四‘’从事同一份工作,并且基本工资高于雇员7521(不包括李四)的全部雇员信息
SELECT * FROM emp WHERE job=(select job from emp where ename='李四') AND sal>(select sal from emp where empno=7521) AND ename<>'李四';
B. 返回单行多列
1. 查询与‘风清扬’从事同一份工作且工资相同的雇员信息(不包括风清扬)
SELECT * FROM emp WHERE (job,sal)=(select job,sal from emp where ename='风清扬') AND ename<>'风清扬';
2. 查询与雇员7749从事同一工作且领导相同的全部信息
SELECT * FROM emp WHERE (job,mgr)=(SELECT job,mgr FROM emp WHERE empno=7749);
3. 查询与‘’李四‘从事同一工作且在同一年雇佣的全部雇员信息’(包括李四)
SELECT * FROM emp WHERE (job,TO_CHAR(hiredate,'yyyy'))=( SELECT job,TO_CHAR(hiredate,'yyyy') FROM emp WHERE ename='李四');
C. 返回多行单列数据
主要使用 IN,ANY,ALL
## IN
1.查询出与每个部门中最低工资的全部信息
SELECT * FROM emp WHERE sal IN (select min(sal) from emp group by did);
注意:关于null的问题,如果在IN之中子查询返回的数据有null,那么不会有影响。如果在 NOT IN 之中子查询返回的数据有null,那么就不会有任何数据返回。
select * from emp where empno not in ( select mgr from emp );

## ANY

1.操作准备:首先找出每个部门经理的最低工资(考虑一个部门可能有多个经理)
SELECT min(sal) FROM emp WHERE job='MANAGER' group by did;
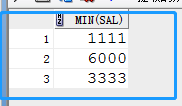
1.1. 然后:
SELECT sal FROM emp WHERE sal=ANY( select min(sal) from emp where job='MANAGER' group by did );

1.2. 发现1,1.1的结果,一样
2. >ANY操作(最小的是 1111)
SELECT * FROM emp WHERE sal>ANY(select min(sal) from emp where job='MANAGER' group by did);
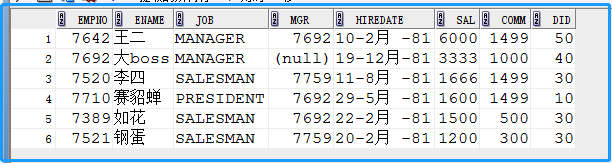
D. exists结构
空数据判断,在SQL之中,提供了 exists结构用于判断子查询是否有数据返回。如果子查询有数据返回,则exists结构返回 true,否则为 false
1.
SELECT * FROM emp WHERE exists ( select * from emp where empno=9999 );

#由于不存在 9999 编号的雇员,所以在这里 exists()判断返回就是false,就不会有结果返回
2.使用 not
select * from emp where not exists( select * from emp where empno=9999 );
三 在HAVING子句中使用子查询
HAVING 一定是结合GROUP BY 子句一起使用的,其主要的目的是进行分组后数据再次过滤,而且与WHERE子句不同的是,HAVING是在分组后,可以使用统计函数。
1.查询部门编号,雇员人数,平均工资,并且要求部门的平均工资高于公司平均工资
SELECT did,count(empno),avg(sal) FROM emp GROUP BY did HAVING avg(sal)>(select avg(sal) from emp);
2. 查询出每个部门平均工资最高的部门名称及平均工资
select d.dname,round(avg(e.sal),2) from emp e,dept d where e.did=d.did group by d.dname having avg(sal)=(select max(avg(sal)) from emp group by did);
四 在FROM子句中使用子查询
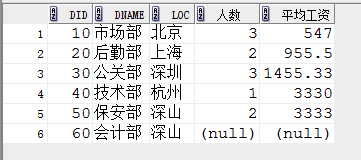
1. 要求查询出每个部门的编号,名称,位置,部门人数,平均工资
SELECT d.did,d.dname,d.loc,temp.人数 ,temp.平均工资 FROM dept d,(select did di,COUNT(empno) 人数,ROUND(avg(sal),2) 平均工资 FROM emp GROUP BY did) temp WHERE d.did=temp.di(+);
2. 查询出所有在 '公关部 '部门工作的员工的编号,姓名,基本工资,奖金,职位,雇佣日期,部门的最高和最低工资
select e.empno,e.ename,e.sal,e.comm,e.job,e.hiredate,temp.max,temp.min from emp e,(select did dd,MAX(sal) max,MIN(sal) min from emp GROUP BY did) temp WHERE e.did=(select did from dept where dname='公关部') AND e.did=temp.dd;

#提示:(select did dd,MAX(sal) max,MIN(sal) min from emp GROUP BY did) temp ---> 子查询负责统计信息,使用temp表示临时的统计结果
3. 查询出所有薪金高于公司平均薪金的员工编号,姓名,基本工资,职位,雇佣日期,所在部门名称,位置,上级领导名称,公司的工资等级,部门人数,平均工资,平均服务年限
SELECT e.empno,e.ename,e.sal,e.job,e.hiredate,d.loc,m.ename FROM emp e,dept d,emp m,salgrade s,(select did dd,count(empno) count, round(avg(months_between(sysdate,hiredate)/12),1) avgyear from emp group by did) temp WHERE e.sal>(select avg(sal) from emp) AND e.did=d.did AND e.mgr=m.empno(+) AND e.sal BETWEEN s.losal AND s.hisal AND e.did=temp.dd;
4. 查询薪金比 ‘张三’ 或 ‘如花’ 多的所有员工的编号,姓名,基本工资,部门名称,其领导姓名,部门人数
SELECT e.empno,e.ename,e.sal,d.dname,m.ename 领导姓名,temp.count FROM emp e,dept d,emp m,(select did dd,count(empno) count from emp group by did) temp WHERE e.sal>ANY(select sal from emp where ename in('张三','如花')) AND e.did=d.did AND e.mgr=m.empno(+) AND temp.dd=d.did AND e.ename NOT IN('张三','如花');
5. 列出公司各个部门的经理(假设每个部门只有一个经理,job为 “MANAGER”)的姓名,薪金,部门名称,部门人数,部门平均工资
SELECT e.ename,e.sal,d.dname,temp.count,temp.avg FROM emp e,dept d,(select did dd,count(empno) count,round(avg(sal),2) avg from emp group by did) temp WHERE job='MANAGER' AND e.did=d.did AND e.did=temp.dd;
五 在SELECT子句中使用子查询(了解)
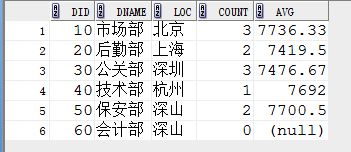
1.查询出公司每个部门的编号,名称,位置,部门人数,平均工资
SELECT did,dname,loc, (select count(empno) from emp where did=d.did group by did) count, (select round(avg(empno),2) from emp where did=d.did group by did) avg FROM dept d;
2.不分组也可以
SELECT did,dname,loc, (select count(empno) from emp where did=d.did ) count, (select round(avg(empno),2) from emp where did=d.did ) avg FROM dept d;
六 WITH子句
临时表实际上就是一个查询结果,如果一个查询结果返回的是多行多列。那么就可以将其定义在FROM字句之中,表示为一张临时表。除了在FROM子句之中出现临时表之外,也可以利用WITH子句直接定义临时表,就可以绕开了FROM子句。
1.使用WITH子句将emp表中的数据定义为临时表
WITH e AS(select * from emp) SELECT * FROM e;
2.查询每个部门的编号,名称,位置,部门平均工资,人数
WITH e AS (select did dd,round(avg(sal),2) avg,count(sal) count from emp group by did) SELECT d.did,d.dname,d.loc,e.count,e.avg FROM e,dept d WHERE e.dd(+)=d.did;
3.查询每个部门工资最高的雇员编号,姓名,职位,雇用日期,工资,部门编号,部门名称,显示的结果按照部门编号进行排序
WITH e AS (select did dd,max(sal) max from emp group by did) SELECT em.empno,em.ename,em.job,em.hiredate,em.sal,d.did,d.dname FROM e,emp em,dept d WHERE e.dd=em.did AND em.sal=e.max AND e.dd=d.did ORDER BY d.did;