对正则的理解
一、1.正则的懒惰性:
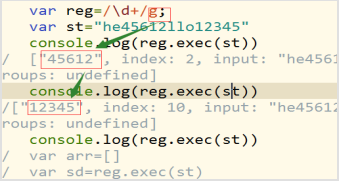
概念:每一次在exec()中捕获的时候,只捕获第一次匹配的内容,而不往下捕获了,我们把这叫正则的懒惰性,每一次捕获的开始位置都是从0开始。

解决正则的懒惰性:用修饰符g
正则的实例对象reg上有一个lastIndex属性 它是正则捕获的起始位置
2.正则的贪婪性:
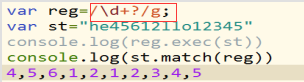
每一次匹配都是按照最长的出结果,我们把这种功能叫正则的贪婪性。

解决正则的贪婪性:在元字符后面加?
二、分组捕获 正则带() 在数分组的个数时从左往右。
var reg=/(a)(b)/就相当于大正则里面带了两个小正则 第一组是(a),第二组是(b)
1.分组捕获的作用:
(1)改变优先级;
(2)分组引用; 1 2
2代表和第二个分组出现一模一样的内容,1代表和第一个分组出现一模一样的内容
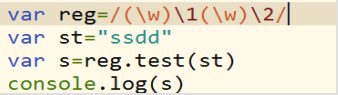
reg中的规则是第一个是一个分组,且是一个单词字符 第二个是个分组 引用要求和第一组一模一样,第三个是第二个分组且是一个一个单词字符,第四个是一个分组引用,要求和第二组一模一样。
(3)分组捕获;
分组捕获的前提是正则存在分组,不仅把大正则的内容捕获到,把小正则的内容也捕获到。

怎样解除分组中分组捕获呢,如果不想捕获某一个分组中的内容,在这个分组的前面加上?:就可以了。
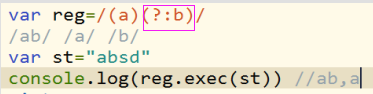
三、1.var reg=/./ var reg=/./
区别:前者代表任意一个字符 而后者代表这个字符串中得有一个“.”。
2.?的使用:
如果单独的一个字符后面带? var reg=/d?/ /n?/ 代表一个或者0个这个字符的出现
如果是量词+和*,{2,}后面带? 是取消正则的贪婪性(在捕获阶段)
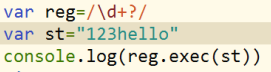
3.捕获:
(1)普通捕获 exec() match()
普通捕获有懒惰性,给正则添加一个修饰符g可以解决,match()是将所有捕获的内容放在一个数组中并返回,Match()就是对exec的一个简单封装。
(2)分组捕获 捕获的方法还是exec()和match()
正则在结构上发生了变化,加()
var reg=/(a)(b)/
exec()和match()在非全局下分组捕获是相同的,在捕获的过程中既捕获大正则里的内容也捕获分组中的内容并都返回。

exec()和match()在全局下分组捕获是不一样的,exec()不变。但是match()只捕获大正则里的内容。’

(3)分组捕获的优势
a.可以提升优先级;
b.可以捕获引用;
1代表分组1里面的内容 2代表分组2里面的内容
前提是分组必须在引用之前,如果2在分组的前面代表普通的表达式???
分组的结果存在正则类RegExp的$number属性下。
1和RegExp.$1二者都是分组引用;
1只能使用在正则表达式里面,而RegExp.1可以外面使用。都是在捕获完成的条件下。
(4)在捕获的过程中怎样取消捕获分组中的内
在分组前面加上?:就OK了
?:和?=的区别
?:取消捕获分组中的内容
?= a(?=b)

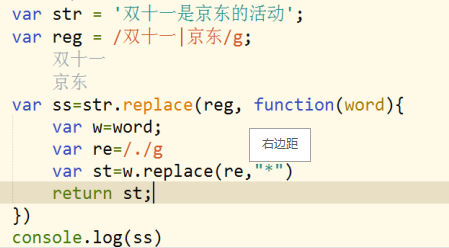
4.replace()细说
replace()是字符串的一个方法,他有两个参数,用后者将前者替换掉,并返回一个新的字符串,但没有改变原来的字符串。
(1)如果第一个参数是字符串,只改变一次;
(2)如果第一个参数是正则‘捕获一次改变一次’
(3)如果第二个参数是匿名函数,每捕获一次这个匿名函数就会执行一次,return的是什么,那就替换成什么。这个匿名函数的arguments有三个元素。