作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
一. 安装Linux,MySql
1. 安装Oracle VM VirtualBox虚拟机,创建并配置Ubuntu(64 bit) ,安装配置参考http://dblab.xmu.edu.cn/blog/337-2/
2.安装Linux系统(Ubuntu)
2.1 点击安装Ubuntu Kylin

2.2 设置用户名、密码

2.3 正在安装

2.4 安装成功
2.5 重启登录

3.安装MySql
3.1 更新软件源

3.2 安装MySQL

3.3 设置MySQL密码

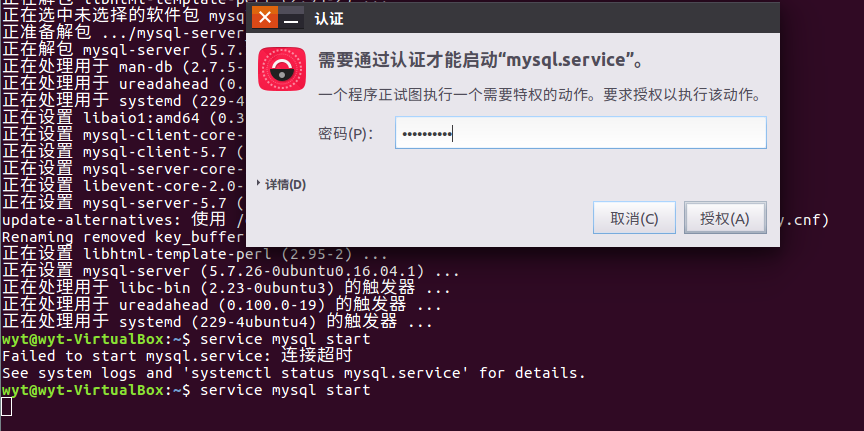
3.4 授权认证
3.5 MySQL是否启动成功,LISTEN状态表示成功启动

3.6 进入MySQL Shell界面

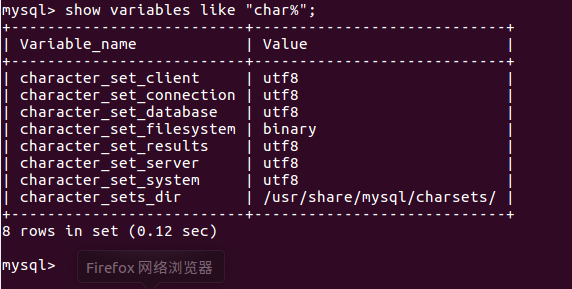
3.7 显示数据库
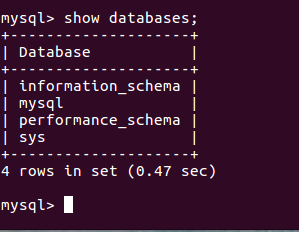
3.8 打开库,显示库中的表
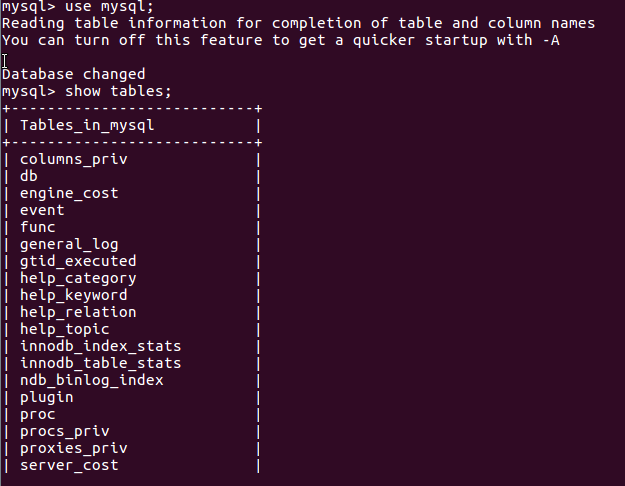
3.9 修改查看数据库的编码(vim编辑器或gedit文本编辑器添加行character_set_server=utf8)
二. windows 与 虚拟机互传文件
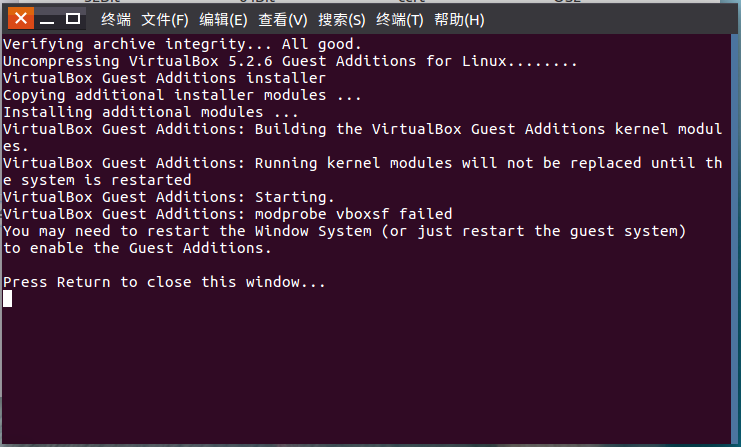
1.安装VirtualBox增强功能包(VBoxGuestAdditions),通过验证
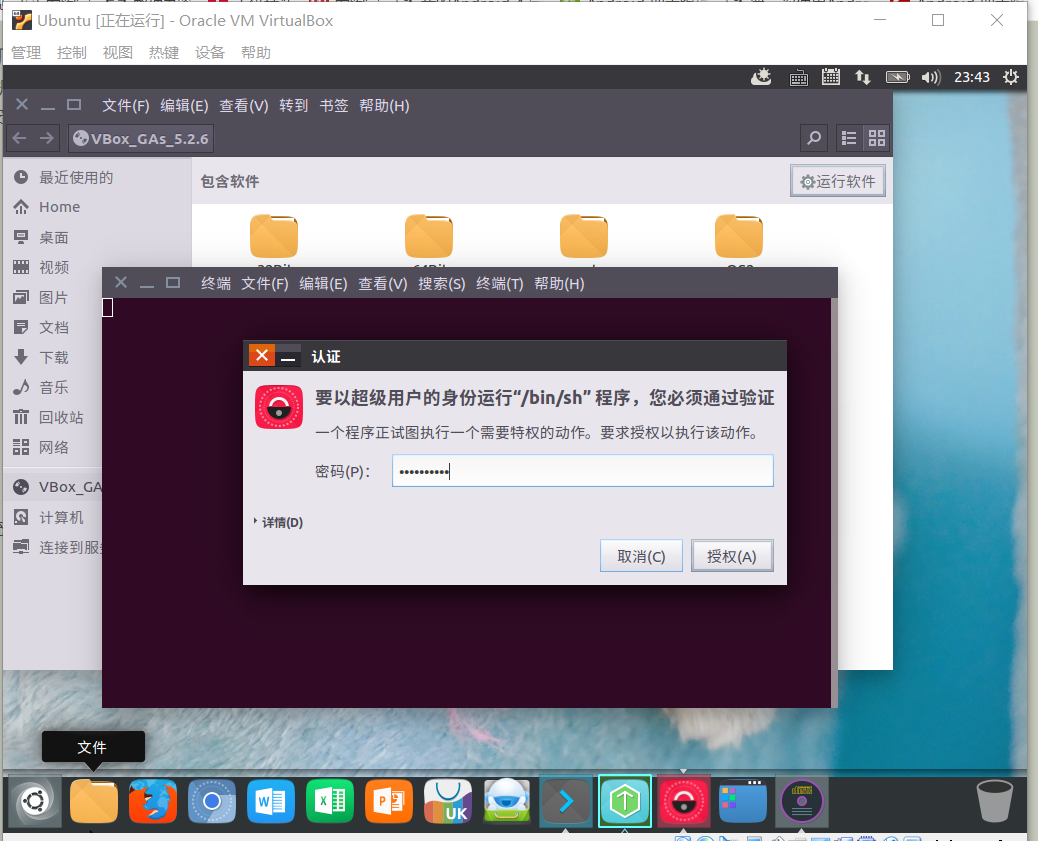
2.点击运行后,系统会自动安装,安装完成后要求重启系统
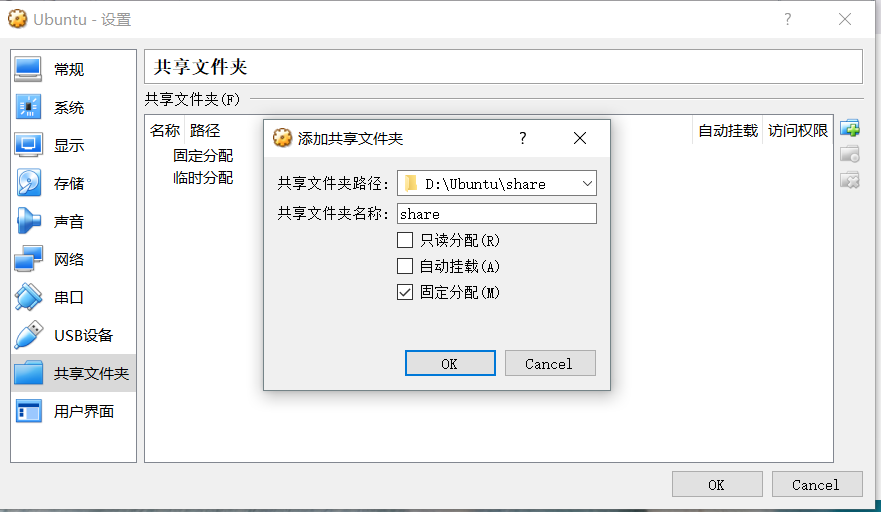
3.设置共享文件夹,我选择本机位置 D:Ubuntushare
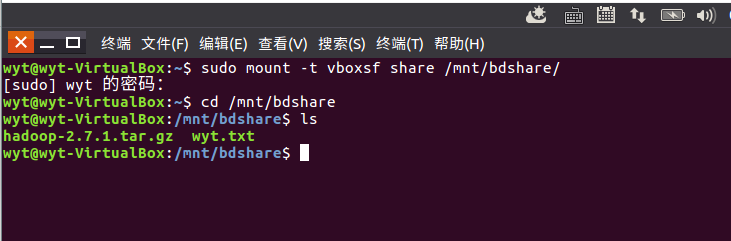
4.完成共享文件夹的设置后,实现共享
三. 安装Hadoop
1. 创建Hadoop用户
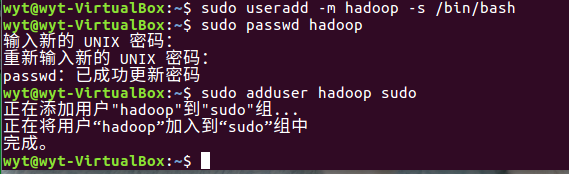
1.1 创建Hadoop用户、设置密码并为Hadoop用户添加管理员权限
1.2 切换至Hadoop登录
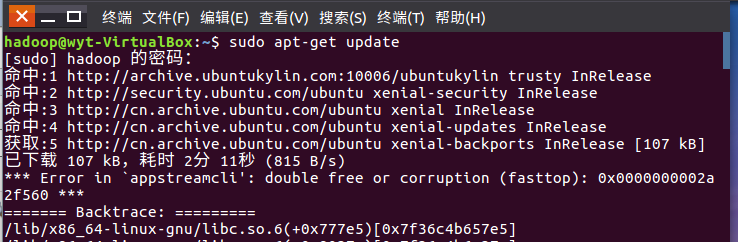
1.3 登录后更新apt
1.4 将Hadoop安装到/usr/local/, (sudo tar -zxf /mnt/bdshare/hadoop-2.7.1.tar.gz -C /usr/local),
并改名为hadoop(sudo mv hadoop-2.7.1 hadoop)
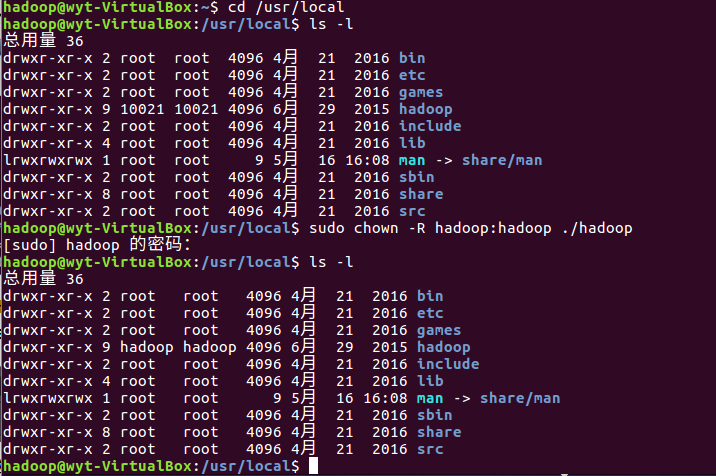
1.5 修改文件夹权限
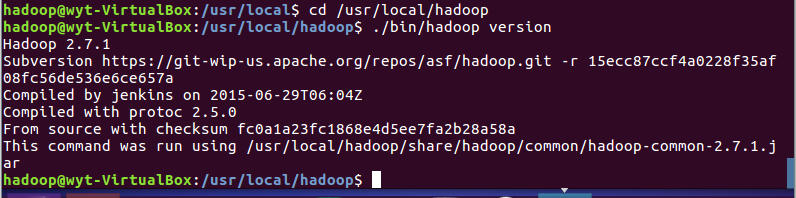
1.6 检查是否hadoop是否可用
2. SSH登录权限设置
2.1 安装SSH,Ubuntu默认已经安装SSH client,需要另外安装SSH server

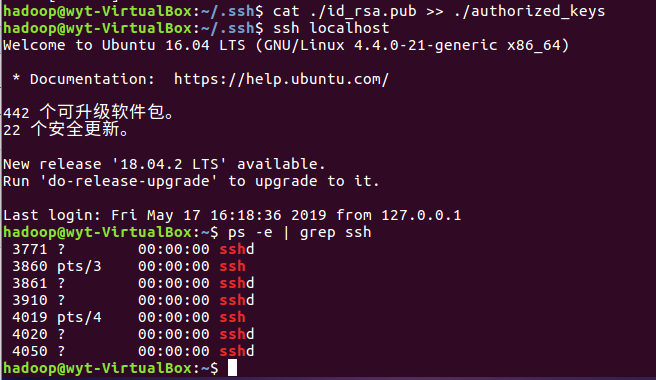
2.2 安装后可用ssh localhost命令登录,但需要密码

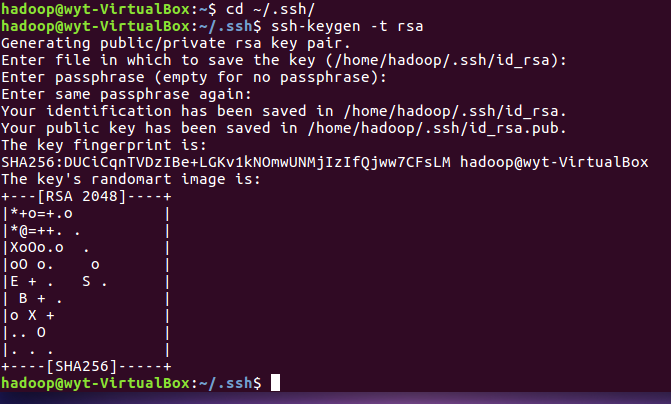
2.3 设置SSH无密钥登录
2.4 SSH无密钥设置完成
3. 安装Java环境
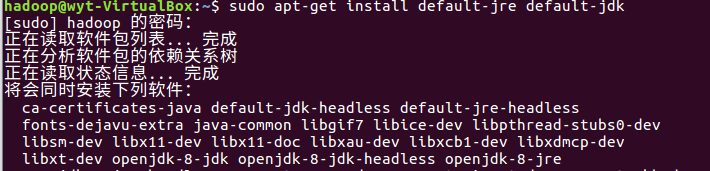
3.1 安装jdk
3.2 修改~/.bashrc文件,添加行export JAVA_HOME=/usr/lib/jvm/default-java
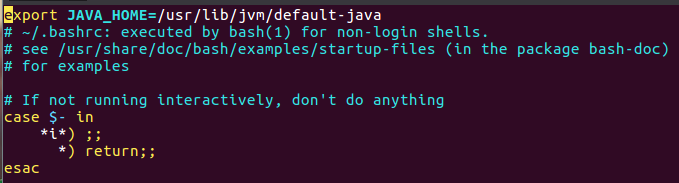
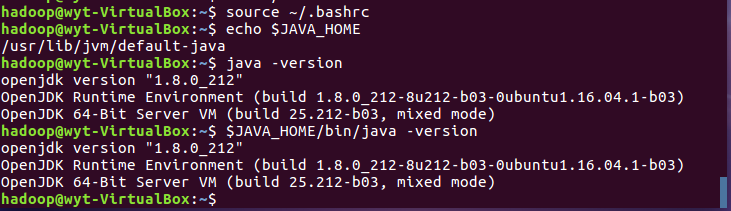
3.3 使环境变量生效,检验变量值,Java环境安装成功
4. 单机Hadoop安装配置
4.1运行grep例子
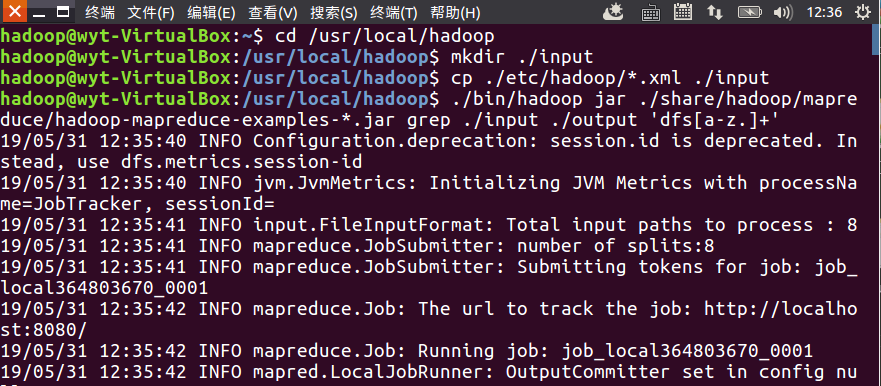
4.2 程序执行成功输出信息和程序执行结果

5. 伪分布式Hadoop安装配置
5.1 修改配置文件 core-site.xml

5.2 修改配置文件 hdfs-site.xml
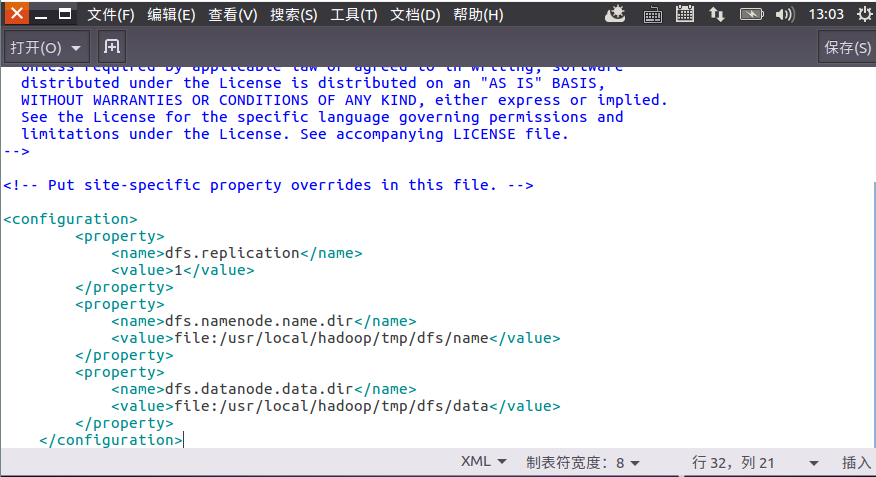
5.3 文件配置完成后,执行NameNode格式化
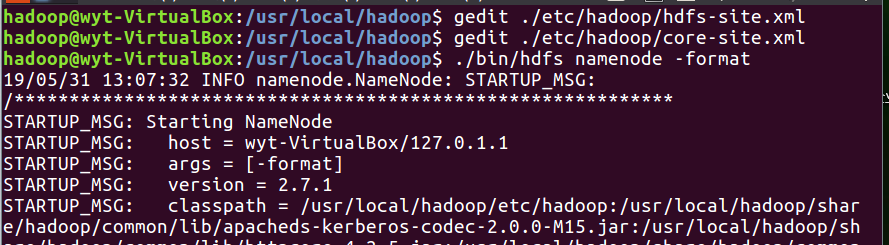
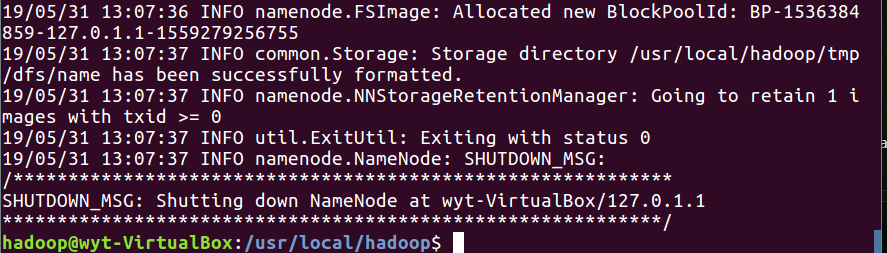
5.4 成功会有以下提示
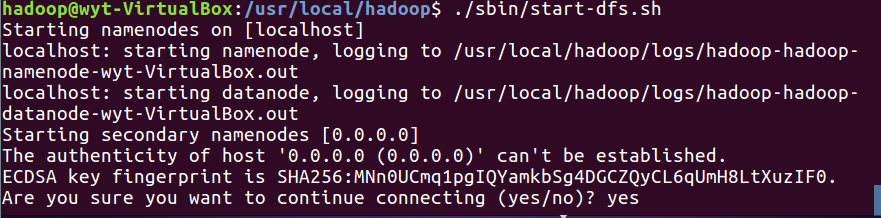
5.5 开启NameNode和DataNode的守护进程,若出现SSH提示,输入yes即可
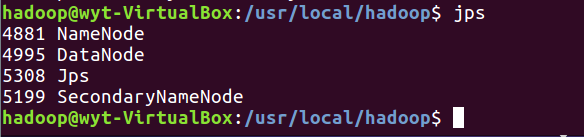
5.6 通过jps命令来判断是否启动成功(若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”)
5.7 运行Hadoop伪分布式实例


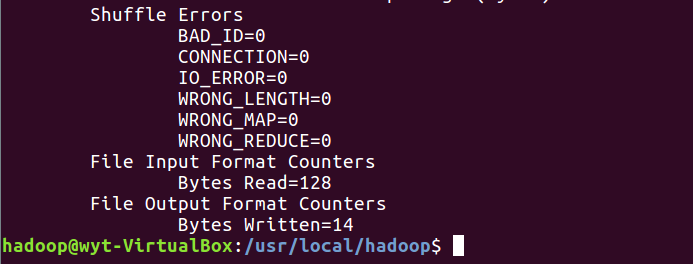
5.8查看结果

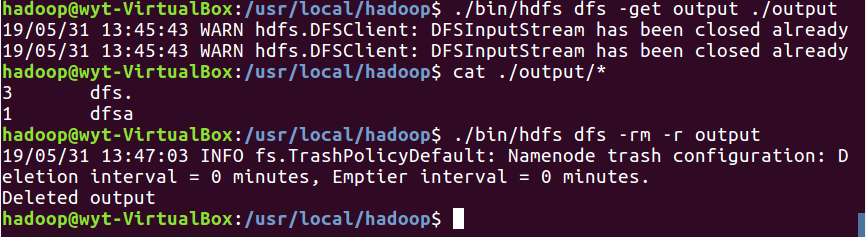
5.9 将结果取回本地
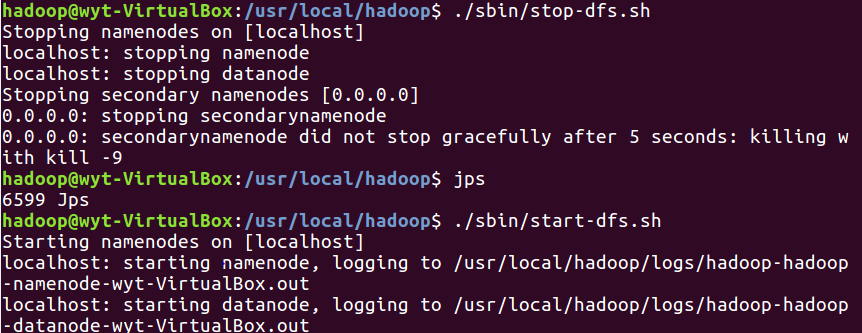
5.10 关闭Hadoop,再次启动Hadoop时,无需再对NameNode进行初始化,只要运行 ./sbin/start-dfs.sh
开启 NameNode 和 DataNode 守护进程即可