本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822
中文词频统计:
1. 下载一长篇中文小说。
2. 从文件读取待分析文本。
def get_text(file): fp=open(file,'r',encoding='utf-8').read() stop_words=open('笑傲江湖.txt','r',encoding='utf-8').read()
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
jieba.lcut(text)
4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word('天罡北斗阵') #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
参考词库下载地址:https://pinyin.sogou.com/dict/
转换代码:scel_to_text
#更新词库 jieba.load_userdict('scel_to_text.txt') words_list = jieba.lcut(fp)
5. 生成词频统计
#生成词频统计 word_dict = {} words_set = set(tokens) for w in words_set: if len(w)>1: word_dict[w] = tokens.count(w)
6. 排序
#排序 words_sort = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
7. 排除语法型词汇,代词、冠词、连词等停用词。
stops
tokens=[token for token in wordsls if token not in stops]
#排除语法型词汇,代词、冠词、连词等停用词 stop_words = stop_words.split(' ') tokens = [token for token in words_list if token not in stop_words]
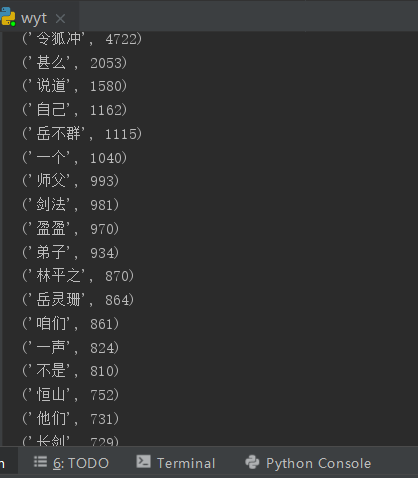
8. 输出词频最大TOP20,把结果存放到文件里。
#输出词频TOP20 words_sort1 = words_sort[:20] for i in range(20): print(words_sort1[i]) pd.DataFrame(data=words_sort).to_csv('order.csv', encoding='utf-8')
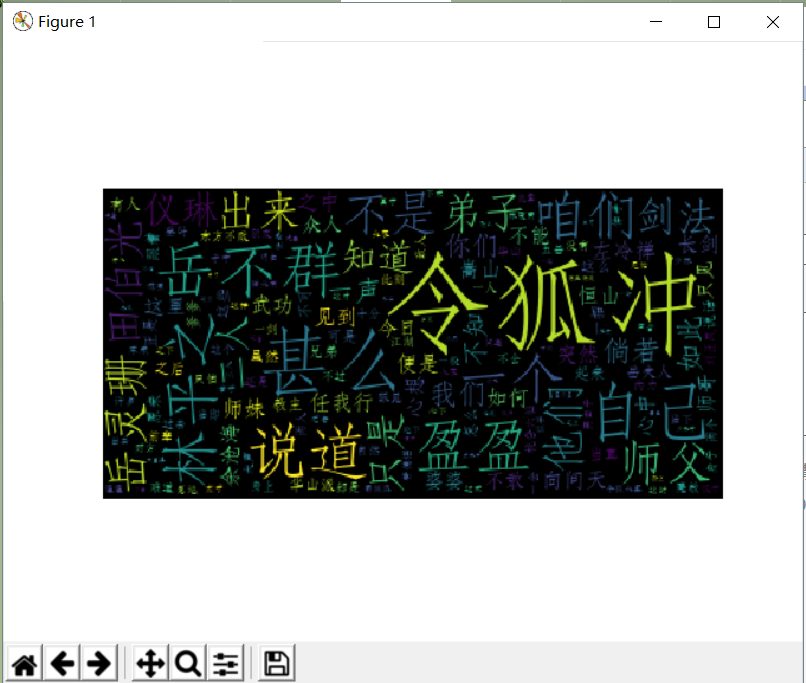
9. 生成词云。
#显示词云 plt.imshow(mywc1) plt.axis('off') plt.show() return words_sort1
完整代码:
import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt import pandas as pd def get_text(file): fp=open(file,'r',encoding='utf-8').read() stop_words=open('笑傲江湖.txt','r',encoding='utf-8').read() #更新词库 jieba.load_userdict('scel_to_text.txt') words_list = jieba.lcut(fp) #排除语法型词汇,代词、冠词、连词等停用词 stop_words = stop_words.split(' ') tokens = [token for token in words_list if token not in stop_words] # 用空格分隔词语 tokenstr = ' '.join(tokens) mywc1 = WordCloud().generate(tokenstr) #生成词频统计 word_dict = {} words_set = set(tokens) for w in words_set: if len(w)>1: word_dict[w] = tokens.count(w) #排序 words_sort = sorted(word_dict.items(), key=lambda x: x[1], reverse=True) #输出词频TOP20 words_sort1 = words_sort[:20] for i in range(20): print(words_sort1[i]) #显示词云 plt.imshow(mywc1) plt.axis('off') plt.show() return words_sort1 if __name__ == '__main__': words_sort = fp = get_text(r'笑傲江湖.txt') pd.DataFrame(data=words_sort).to_csv('order.csv',encoding='utf-8')