本次作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
一.把爬取的内容保存到数据库sqlite3
1. 用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:wytgzccnews.csv')
2.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con=db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('select * from gzccnews',con=db)
df2
3.保存到MySQL数据库
import pandas as pd import pymysql from sqlalchemy import create_engine conInfo = "mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8" engine = create_engine(conInfo,encoding='utf-8') df = pd.DataFrame(allnews) df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)

二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
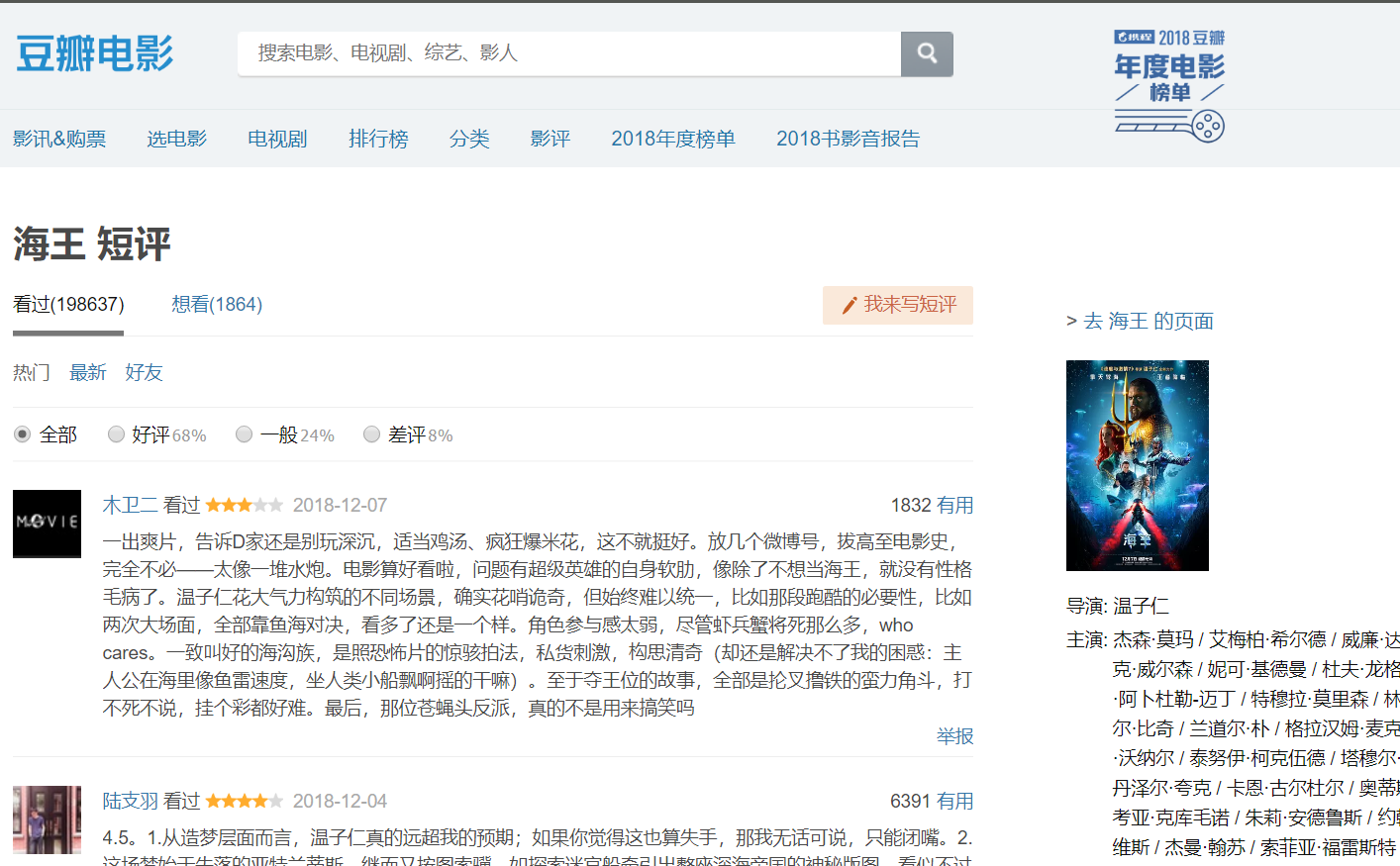
1.这次爬取对象为《海王》的豆瓣短评,希望通过这次爬取到评论来让更多人来了解DC巨作《海王》。
《海王》是由美国华纳兄弟影片公司出品的动作奇幻电影,由温子仁执导,杰森·莫玛、艾梅柏·希尔德、帕特里克·威尔森联合主演。该片于2018年12月7日在中国内地上映,2018年12月21日在美国上映。
《海王》根据DC漫画改编,讲述了亚瑟·库瑞认识到他家族血脉的真谛的过程,以及和湄拉一同对抗对人类怀有更深敌意的同母异父的兄弟——海洋领主奥姆的故事。2018年12月,《海王》在《福布斯》2018年最佳超级英雄电影排行榜中排名第9。2019年1月,该片获得美国服装设计工会奖最佳科幻/幻想电影服装设计提名。
2.数据爬取:
import requests
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
uas = [
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10'
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'
]
# 随机选取用户代理
def get_ua():
au = random.choice(uas)
return au
# 抓取解析网页
def get_soup(url):
# 伪装浏览器发送请求
headers = {
'User-Agent': get_ua(),
'Host': 'movie.douban.com',
'Connection': 'keep-alive',
'Cookie': 'll="118281"; bid=PDfyRYzWZUA; __utmz=30149280.1557146179.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); '
'gr_user_id=64e50650-eaac-439c-bf07-4845beda01f4; _vwo_uuid_v2=DCC7E0177B98EF36F009D20E376BAFAF0|af1541df8cba612ae9400c9868c99729; viewed="1291199";'
' __yadk_uid=NZF4B0V65mFYDKwVEtBIqD7IzCfqBuCo; trc_cookie_storage=taboola%2520global%253Auser-id%3D1b6006bb-7d65-4a3d-9ef8-0bd85ef174e3-tuct363a7b2;'
' __gads=ID=aa3da2d975e4bc28:T=1557291874:S=ALNI_Mb5dM0i_lKo5qiVEALC5SbsE4zAeg;'
' __utmz=223695111.1557291909.3.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; _'
'pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1557365604%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fq%3D%25E6%2597%25A0%25E9%2597%25AE%25E8%25A5%25BF%25E4%25B8%259C%22%5D;'
' _pk_ses.100001.4cf6=*; __utma=30149280.574526707.1557146179.1557305660.1557365604.7; __utmc=30149280; __utma=223695111.1592700349.1557228376.1557305660.1557365604.6;'
' __utmc=223695111; ap_v=0,6.0; __utmb=30149280.4.9.1557368405684; dbcl2="196202536:5ThcQT2Qzr0";'
' ck=EL1Z; push_noty_num=0; push_doumail_num=0; ct=y; __utmt=1; _pk_id.100001.4cf6=627ae57bc2f4ade6.1557228376.6.1557369194.1557306413.; __utmb=223695111.19.10.1557365604'
}
res = requests.get(url, headers=headers)
time.sleep(random.random()*5) #设置时间间隔,防止太快被封
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
return soup
# 获取一页用户的评论
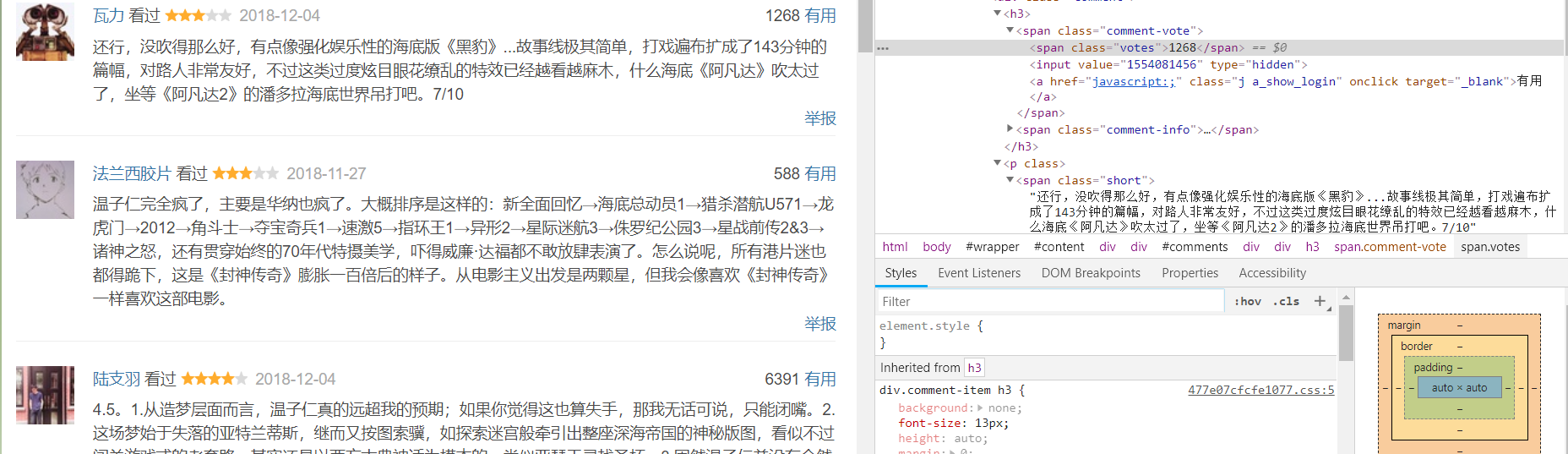
def getText(soup):
comment_list = []
for p in soup.select('.comment-item'):
comment = {}
username = p.select('.comment-info')[0]('a')[0].text
watch = p.select('.comment-info')[0]('span')[0].text
intro = p.select('.comment-info')[0]('span')[1]['title']
cTime = p.select('.comment-time ')[0]['title']
pNum = p.select('.votes')[0].text
short = p.select('.short')[0].text
text=short.replace('
', ' ')
comment['用户名']=username
comment['观看情况']=watch
comment['评分推荐']=intro
comment['评论时间']=cTime
comment['短评内容']=text
comment['赞同该评论次数']=pNum
comment_list.append(comment)
return comment_list
url = 'https://movie.douban.com/subject/3878007/comments?start={}&limit=20&sort=new_score&status=P'
comments = []
for i in range(1,50):
soup = get_soup(url.format(i * 20)) # 每一页20条评论需乘20来拼凑网页
comments.extend(getText(soup))
time.sleep(random.random() * 5)
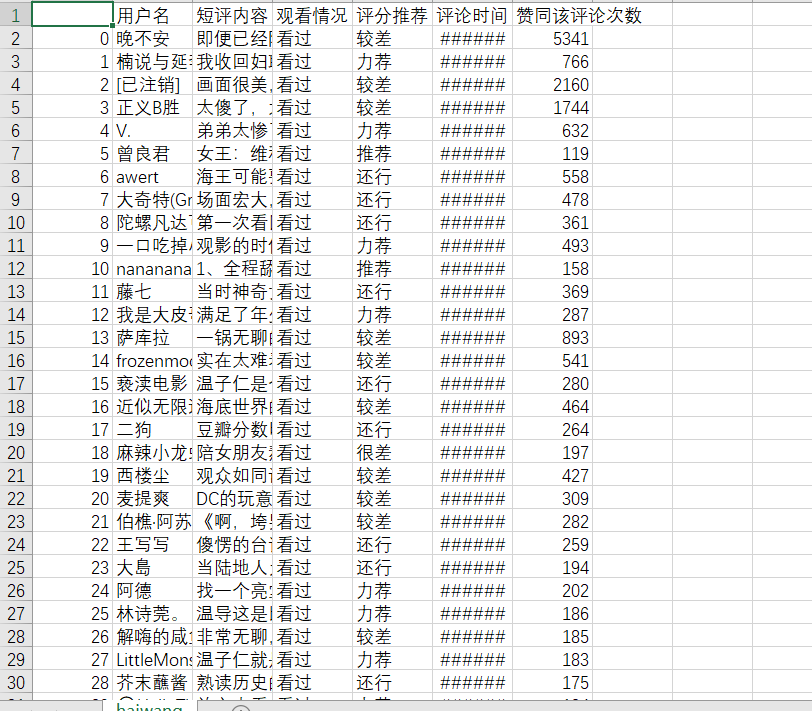
# 保存到本地haiwang。csv文件
commentFile = pd.DataFrame(comments)
commentFile.to_csv(r'F:wythaiwang.csv', encoding='utf_8_sig')
生成的csv文件:
3. 处理数据;
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
def get_text(file):
fp=open(file,'r',encoding='utf-8').read()
stop_words=open(r'F:wythaiwang.csv','r',encoding='utf-8').read()
#更新词库
jieba.load_userdict('scel_to_text.txt')
words_list = jieba.lcut(fp)
#排除语法型词汇,代词、冠词、连词等停用词
stop_words = stop_words.split('
')
tokens = [token for token in words_list if token not in stop_words]
# 用空格分隔词语
tokenstr = ' '.join(tokens)
mywc1 = WordCloud().generate(tokenstr)
#生成词频统计
word_dict = {}
words_set = set(tokens)
for w in words_set:
if len(w)>1:
word_dict[w] = tokens.count(w)
#排序
words_sort = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
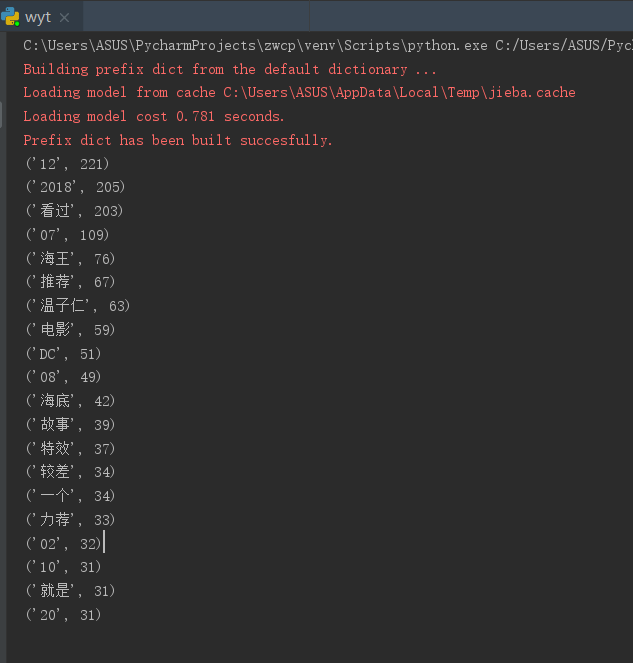
#输出词频TOP20
words_sort1 = words_sort[:20]
for i in range(20):
print(words_sort1[i])
#显示词云
plt.imshow(mywc1)
plt.axis('off')
plt.show()
return words_sort1
if __name__ == '__main__':
words_sort = fp = get_text(r'F:wythaiwang.csv')
pd.DataFrame(data=words_sort).to_csv('order1.csv',encoding='utf-8')
3.1 输出词频top20;
3.2 生成词云;
