目录
1、 从titles表中获取title并按照title分组
2、从titles表中获取title并按照title分组,重复的emp_no忽略
3 查找employees表
4 统计平均工资
5 获取第二多的薪水
6 获取第二多的薪水不使用order by
7 查找员工的名字和对应的部门名字
8 查找薪水涨幅
9 查找所有员工的薪水涨幅
10 对所有员工薪水排序
11 获取员工其当前的薪水比其manager当前薪水还高的相关信息
12 汇总各个部门当前员工的title类型的分配数目
13 给出每个员工每年薪水涨幅超过5000的员工编号emp_no
1、 从titles表中获取title并按照title分组
题目描述:
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
输出描述:
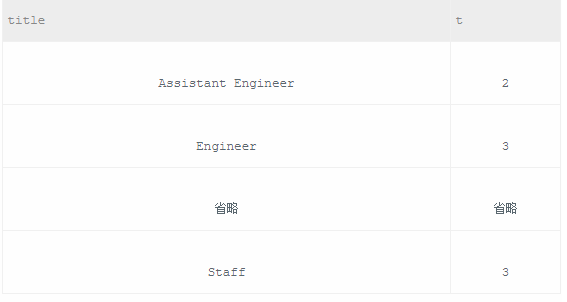
1 /* 2 此题应注意以下三点: 3 1、用COUNT()函数和GROUP BY语句可以统计同一title值的记录条数 4 2、根据题意,输出每个title的个数为t,故用AS语句将COUNT(title)的值转换为t 5 3、由于WHERE后不可跟COUNT()函数,故用HAVING语句来限定t>=2的条件 6 */ 7 8 SELECT title, COUNT(title) AS t FROM titles 9 GROUP BY title HAVING t >= 2
2、从titles表中获取title并按照title分组,重复的emp_no忽略
题目描述:
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。此时忽略同一title下的emp_no。
输出描述:
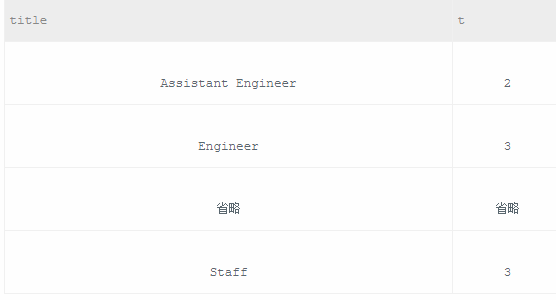
1 /* 2 此题应注意以下三点: 3 1、先用GROUP BY title将表格以title分组,再用COUNT(DISTINCT emp_no)可以统计同一title值且不包含重复emp_no值的记录条数 4 2、根据题意,输出每个title的个数为t,故用AS语句将COUNT(DISTINCT emp_no)的值转换为t 5 3、由于WHERE后不可跟COUNT()函数,故用HAVING语句来限定t>=2的条件 6 */ 7 8 SELECT title, COUNT(DISTINCT emp_no) AS t FROM titles 9 GROUP BY title HAVING t >= 2
3 查找employees表
题目描述:
查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
输出描述:
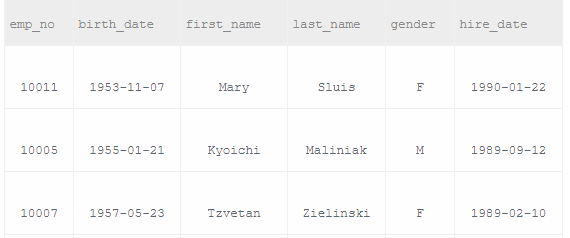
1 /* 2 三点需要注意: 3 1、员工号为奇数,则emp_no取余应为1 4 2、last_name不为Mary,用‘!=’表示也可以用<>表示 5 3.根据hire_date逆序排列,用desc 6 */ 7 8 SELECT * FROM employees 9 WHERE emp_no%2 =1 10 AND last_name <> 'Mary' 11 ORDER BY hire_date DESC;
4 统计平均工资
题目描述:
统计出当前各个title类型对应的员工当前薪水对应的平均工资。结果给出title以及平均工资avg。
输出描述:
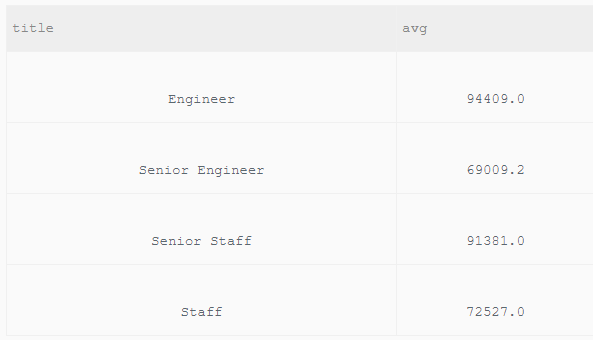
SELECT t.title,AVG(s.salary) FROM salaries AS s INNER JOIN titles AS t ON s.emp_no = t.emp_no AND s.to_date = '9999-01-01' AND t.to_date = '9999-01-01' GROUP BY title
5 获取第二多的薪水
题目描述
获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水salary
输出描述:
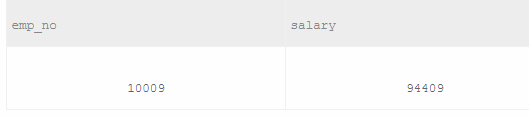
1 select emp_no, salary from salaries 2 where to_date = '9999-01-01' and salary = (select distinct salary from salaries order by salary desc limit 1,1) 3 避免了2个问题: 4 (1) 首先这样可以解决多个人工资相同的问题; 5 (2) 另外,筛选出第二多的工资时要注意distinct salary,否则不能选出第二多的工资。
6 获取第二多的薪水不使用order by
题目描述:
输出描述:
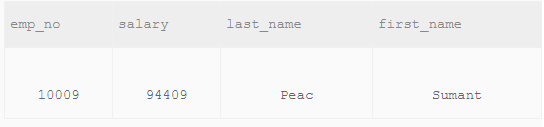
#要求次高的,那么一个思路便是从在去除掉最高的数据中选择最高的即可,有两种实现方法 SELECT s.emp_no,MAX(s.salary) AS salary,e.last_name,e.first_name FROM salaries AS s,employees AS e WHERE s.salary NOT IN(SELECT MAX(salary) FROM salaries) AND e.emp_no = s.emp_no AND s.to_date = '9999-01-01' #第二种方法也是这个思路,不过用的不是NOT IN 而是小于符合 SELECT s.emp_no,MAX(s.salary) AS salary,e.last_name,e.first_name FROM salaries AS s,employees AS e WHERE s.salary < (SELECT MAX(salary) FROM salaries) AND e.emp_no = s.emp_no AND s.to_date = '9999-01-01'
7 查找员工的名字和对应的部门名字
题目描述:
查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
输出描述:
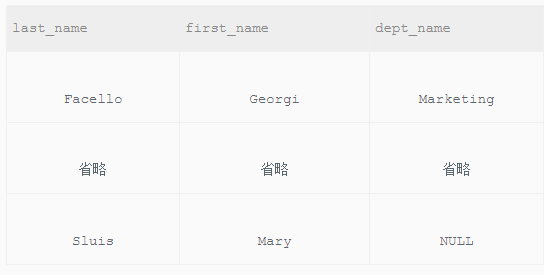
#在这里就涉及到三个表的查询了,employees表提供姓名,部门员工表提供员工对应的部门编号 #部门表则根据部门编号提供部门名称 #根据题目要求要包含还没有分配部门的员工,所以用where进行联结肯定是不行的,所以采取左联或者右联的方式 #在第二次联结的时候,是在第一次员工和部门员工表连接的基础上进行,此时也不能用where SELECT e.last_name,e.first_name,d.dept_name FROM (employees AS e LEFT OUTER JOIN dept_emp AS de ON e.emp_no = de.emp_no) LEFT OUTER JOIN departments AS d ON de.dept_no = d.dept_no
也可以先让后面两张表连在一起:
SELECT e.last_name,e.first_name,d.dept_name FROM employees AS e LEFT OUTER JOIN ( departments AS d INNER JOIN dept_emp AS de ON d.dept_no = de.dept_no) ON e.emp_no = de.emp_no
8 查找薪水涨幅
题目描述:
查找员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth
输出描述:
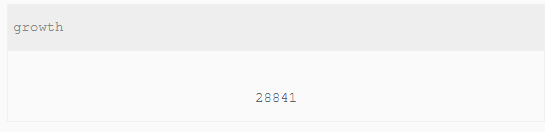
#根据日期选择出日期最大即最新的工资减去最旧的日期即可 SELECT ( (SELECT salary FROM salaries WHERE emp_no = '10001' ORDER BY to_date DESC LIMIT 1) - (SELECT salary FROM salaries WHERE emp_no = '10001' ORDER BY to_date ASC LIMIT 1) ) AS growth
9 查找所有员工的薪水涨幅
题目描述:
查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
输出描述:
#我一直想着分组去处理,因为每一个emp_no有很多条数据,但后来发现这条路走不通,因为分组时要分别对应不同的emp_no计算 #对于这个问题无法解决因此考虑其他方法。观察两张表就可以发现from_date和hire_date之间的联系了,利用这个可以快速定义查询条件 SELECT e.emp_no,s1.salary-s2.salary AS growth FROM employees e INNER JOIN salaries s1 ON s1.to_date="9999-01-01" AND s1.emp_no=e.emp_no INNER JOIN salaries s2 ON s2.from_date=e.hire_date AND s2.emp_no=e.emp_no ORDER BY growth ASC;
10 对所有员工薪水排序
题目要求:
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列。
输出要求:
题目分析:
(1)从两张相同的salaries表(分别为s1与s2)进行对比分析,先将两表限定条件设为to_date = '9999-01-01',挑选出当前所有员工的薪水情况。
(2)本题的精髓在于 s1.salary <= s2.salary,意思是在输出s1.salary的情况下,有多少个s2.salary大于等于s1.salary,比如当s1.salary=94409时,有3个s2.salary(分别为94692,94409,94409)大于等于它,但由于94409重复,利用COUNT(DISTINCT s2.salary)去重可得工资为94409的rank等于2。其余排名以此类推。
(3)千万不要忘了GROUP BY s1.emp_no,否则输出的记录只有一条(可能是第一条或者最后一条,根据不同的数据库而定),因为用了合计函数COUNT(
(4)最后先以 s1.salary 逆序排列,再以 s1.emp_no 顺序排列输出结果
-- 这里用count的计数来实现排序 SELECT s1.emp_no,s1.salary,COUNT(DISTINCT s2.salary) AS rank FROM salaries AS s1,salaries AS s2 -- s2的salary去重后,寻找小于等于的有多少个 WHERE s1.to_date='9999-01-01' AND s2.to_date='9999-01-01' AND s1.salary <= s2.salary -- 使用count一般与group by连用来分组求和 GROUP BY s1.emp_no -- 第一个要求是按照salary降序,当相同时才进行升序排列,所以应该把降序的要求放在首位 ORDER BY s1.salary DESC, s1.emp_no ASC
11 获取员工其当前的薪水比其manager当前薪水还高的相关信息
题目描述:
获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',结果第一列给出员工的emp_no,第二列给出其manager的manager_no,第三列给出该员工当前的薪水emp_salary,第四列给该员工对应的manager当前的薪水manager_salary
输出描述:
题解思路:
SELECT sem.emp_no AS emp_no, sdm.emp_no AS manager_no, sem.salary AS emp_salary, sdm.salary AS manager_salary FROM (SELECT s.salary, s.emp_no, de.dept_no FROM salaries s INNER JOIN dept_emp de ON s.emp_no = de.emp_no AND s.to_date = '9999-01-01' ) AS sem, (SELECT s.salary, s.emp_no, dm.dept_no FROM salaries s INNER JOIN dept_manager dm ON s.emp_no = dm.emp_no AND s.to_date = '9999-01-01' ) AS sdm WHERE sem.dept_no = sdm.dept_no AND sem.salary > sdm.salary
12 汇总各个部门当前员工的title类型的分配数目
题目描述:
汇总各个部门当前员工的title类型的分配数目,结果给出部门编号dept_no、dept_name、其当前员工所有的title以及该类型title对应的数目count
题解思路:
(1)先用 INNER JOIN 连接 dept_emp 与 salaries,根据测试数据添加限定条件 de.to_date = '9999-01-01' AND t.to_date = '9999-01-01',即当前员工的当前头衔
(2)再用 INNER JOIN 连接departments,限定条件为 de.dept_no = dp.dept_no,即部门编号相同
(3)最后用 GROUP BY 同时对 de.dept_no 和 t.title 进行分组,用 COUNT(t.title) 统计相同部门下相同头衔的员工个数
SELECT de.dept_no, dp.dept_name, t.title, COUNT(t.title) AS `count` FROM titles AS t INNER JOIN dept_emp AS de ON t.emp_no = de.emp_no AND de.to_date = '9999-01-01' AND t.to_date = '9999-01-01' INNER JOIN departments AS dp ON de.dept_no = dp.dept_no GROUP BY de.dept_no, t.title
对于为什么要有两个分组:
如果只按dept_no分组,那么每个dept_no只会出现一条记录,则不能体现同一dept_no中的不同title。GROUP BY de.dept_no, t.title 的作用是同时将de.dept_no和t.title分组,即要两者都相同才能判别为相同的分组,只要一个不同就算不同的分组。
13 给出每个员工每年薪水涨幅超过5000的员工编号emp_no
题目描述:
给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
提示:在sqlite中获取datetime时间对应的年份函数为strftime('%Y', to_date)
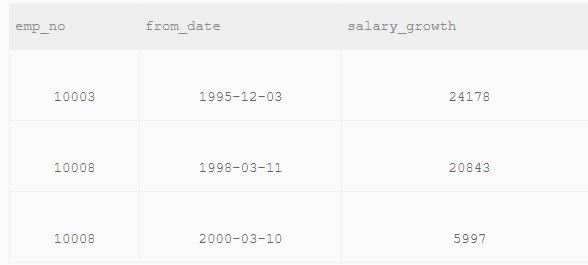
题目思路:
(1)假设s1是涨薪水前的表,s2是涨薪水后的表,因为每个员工涨薪水的时间不全固定,有可能一年涨两次,有可能两年涨一次,所以每年薪水的涨幅,应该理解为两条薪水记录的from_date相同或to_date相同。如果只限定to_date相同则可能会造成数据丢失。
SELECT s2.emp_no, s2.from_date, (s2.salary - s1.salary) AS salary_growth FROM salaries AS s1, salaries AS s2 WHERE s1.emp_no = s2.emp_no AND salary_growth > 5000 AND (strftime("%Y",s2.to_date) - strftime("%Y",s1.to_date) = 1 OR strftime("%Y",s2.from_date) - strftime("%Y",s1.from_date) = 1 ) ORDER BY salary_growth DESC