1-1.数据压缩的一个基本问题是“我们要压缩什么”,对此你是怎样理解的?
答:数据压缩,就是指不丢失有用信息的前提下,以最少的数码表示信号源所发的信号,减少容纳给定消息集合或数据采样集合的信号空间。
所谓的信号空间就是我们压缩的对象,即
1) 物理空间,如存储器和U盘等数据存储介质。
2) 时间空间,如传输给定消息集合所需的时间。
3)频带空间,如传输给定消息所要求的宽带等。
而衡量一种数据压缩技术的好坏有三个重要的指标:
-
压缩比要大。
-
恢复效果要好,要尽可能地恢复原始数据。
-
实现压缩的算法要简单,压缩、解压速度快,尽可能地做到实时压缩、解压。
1-1.数据压缩的另一个基本问题是“为什么进行”,对此你又是怎样理解的?
答:因为多媒体技术所处理的对象包括图像、视频和声音等多种媒体。它们的数据量非常大。
如果不进行数据压缩传输和存储都难以实用化。而经过数据压缩可以将一些占用内存比较大多媒体数据,
压缩成可以缩小的文件内存,这样可以方便传递。
以多媒体数据为例:一般,原声的多媒体数据都比较大,在传播的时候比较麻烦;而如果经过一定的有损压缩/无损压缩,
会在不影响观赏的情况下,方便信息的交流;举个实例就是现在高清视频的一般都是没经过压缩或者压缩较小的,观赏清楚,
但是文件都很大,而一般的格式的视频,较小,方便传播,但是清晰度没有高清的清晰了。
1-6.数据压缩技术如何分类?
数据压缩,通俗地说,就是用最少的数码来表示信号。 其作用是:能较快地传输各种信号,如传真、Modem通信等; 分为有损压缩和无损压缩。
1:无损压缩
所谓无损压缩格式,是利用数据的统计冗余进行压缩,可完全回复原始数据而不引起任何失真,但压缩率是受到数据统计冗余度的理论限制,一般为2:1到5:1.这类方法广泛用于文本数据,程序和特殊应用场合的图像数据(如指纹图像,医学图像等)的压缩。由于压缩比的限制,仅使用无损压缩方法是不可能解决图像和数字视频的存储和传输的所有问题.经常使用的无损压缩方法有 Shannon-Fano 编码,Huffman 编码,游程(Run-length)编码,LZW(Lempel-Ziv-Welch)编码和算术编码等。
所谓无损压缩格式,顾名思义,就是毫无损失地将声音信号进行压缩的音频格式。常见的像MP3、WMA等格式都是有损压缩格式,相比于作为源的WAV文件,它们都有相当大程度的信号丢失,这也是它们能达到10%的压缩率的根本原因。而无损压缩格式,就好比用Zip或RAR这样的压缩软件去压缩音频信号,得到的压缩格式还原成WAV文件,和作为源的WAV文件是一模一样的!但是如果用Zip或RAR来压缩WAV文件的话,必须将压缩包解压后才能播放。而无损压缩格式则能直接通过播放软件实现实时播放,使用起来和MP3等有损格式一模一样。总而言之,无损压缩格式就是能在不牺牲任何音频信号的前提下,减少WAV文件体积的格式。
2:有损压缩
所谓有损压缩是利用了人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息;虽然不能完全回复原始数据,但是所损失的部分对理解原始图像的影响缩小,却换来了大得多的压缩比。有损压缩广泛应用于语音,图像和视频数据的压缩。
常见的声音、图像、视频压缩基本都是有损的。
在多媒体应用中,常见的压缩方法有:PCM(脉冲编码调制),预测编码,变换编码,插值和外推法,统计编码,矢量量化和子带编码等,混合编码是近年来广泛采用的方法。
参考书《数据压缩导论》
1.4 项目与试题
1.用你的计算机上的压缩工具来压缩不同文件。研究原文件的大小的类型对于压缩文件与源文件大小之比的影响。
答:这个跟压缩算法有关。
一般字符文件的压缩比较高。可以达到50%左右。
视频,音频,图像文件,压缩比一般80%左右。
2.从一种通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如,在“This is a dog that belongs to my friend”中,删除 is、the、that和to之后,仍然能传递相同的意思。用被删除的单词数与原文本的总单词数之比来衡量文本中的冗余度,用一本技术期刊中的文字来重复这一试验。对于摘自不同来源的文字,我们是否就其冗余度做出定量论述?
答:不能,因为不同文件的内容不一样,它们的文本中的冗余度也不一样,所以对于摘自不同来源的文字,不能就其冗余度做出定量论述。
三、参考书《数据压缩导论(第4版)》Page 30
3、给定符号集A={a1,a2,a3,a4},求一下条件下的一阶熵:
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4
(b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8
(c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/4 , P(a4)=0.12
答:(a)一阶熵为:
-1/4*4*log21/4
=-log22-2
=2(bit)
(b)一阶熵为:
-1/2log21/2-1/4*log21/4-2*1/8*log21/8
=1/2+1/2+3/4
=7/4
=1.75(bit)
(c)一阶熵为:
-0.505*log20.505-1/4*log21/4-1/4*log21/4-0.12*log20.12
=-0.505*log20.505+1/2+1/2-0.12*log20.12
=0.2967+1-0.12*log20.12
=1.2967-0.12*log20.12(bit)
5、考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
(a)根据此序列估计各概率值,并计算这一序列的一阶、二阶、三阶和四阶熵。
(b)根据这些熵,能否推断此序列具有什么样的结构?
答:首先总的字母有84个,其中字母A出现21次,字母T出现23次,字母G出现16次,字母C出现24次。
则P(A)=21/84=1/4;P(T)=23/84;P(G)=16/84=4/21;P(C)=24/84=2/7.
(a)各字母的概率值如下:
P(A)=21/84=1/4;P(T)=23/84;P(G)=16/84=4/21;P(C)=24/84=2/7.
则这一序列的一阶熵为:
-21*1/4*log2(1/4)-23*23/84*log2(23/84)-16*4/21*log2(4/21)-24*2/7*log2(2/7)=
7、做一个实验,看看一个模型能够多么准确地描述一个信源。
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
int main()
{
int x,y,z;
char m[100][100];
srand(time(NULL));
for(y=0;y<100;y++)
{
for(z=0;z<4;z++)
{
x=rand()%26;
m[y][z]=x+'a';
}
m[y][4]='�';
printf("%d: %s ",y+1,m[y]);
}
return 0;
}
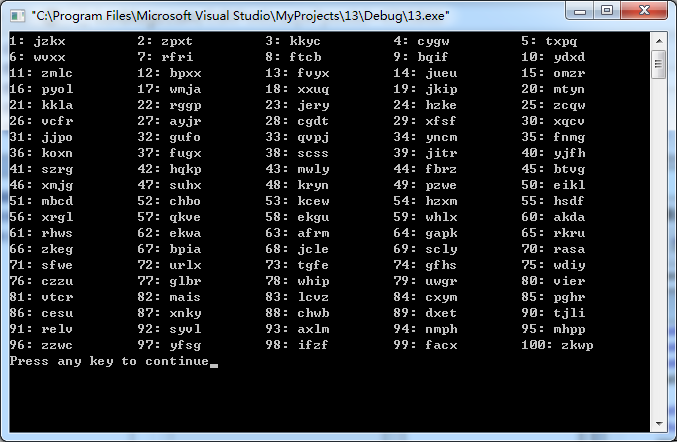
只发现第78个单词有意义,意思为“鞭打”。