首先 先把你虚拟机和本机网络链接弄通 (详情看上一篇) 一些关于mapreduce 和hadoop的配置都在上一篇
安装eclipse 的hadoop Map/Reduce插件详情 看其他博客园.........
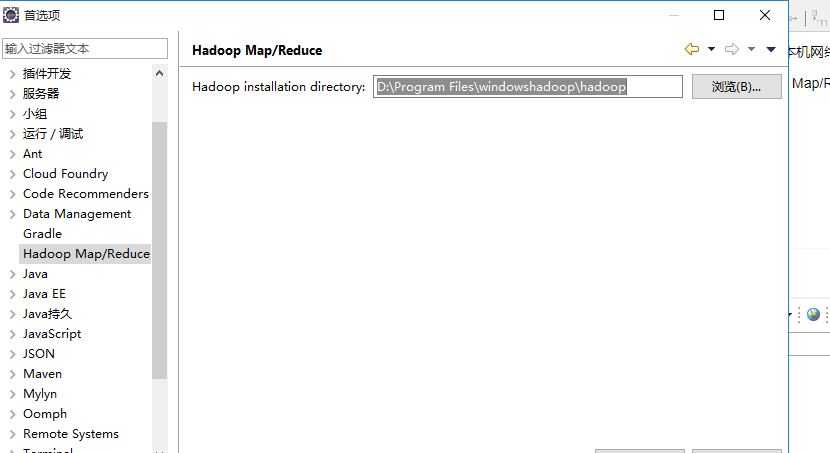
这里里面配置的是你windows下的hadoop 高版本貌似兼容低版本 下载请参考网上
我这里有hadoop-2.6.4的链接大家参考下载 https://www.lanzous.com/i2h1e2b
一般都会报winutils.exe 找不到呀各种错误 需要吧 你hadoop bin下的 hadoop.dll 文件放在你windows下system32文件夹下 就会解决
代码不贴了自己玩吧
忘了 你写的代码main函数或者函数中要包括
System.setProperty("hadoop.home.dir", "D:\Program Files\windowshadoop\hadoop-2.6.4");
这个不弄会写不出文件到虚拟机里的 后面路径是你windows系统下的hadoop路径 网上的有的要改什么配置 修改什么xml还有环境变量都是不存在的 不用弄就能访问
还有 你windows下访问虚拟机hdfs文件权限问题 你可能无法直接删除 你可以设置一下文件路径权限为所有用户共有 hdfs dfs -chmod 777 /+你的路径 举个例子 hdfs dfs -chmod 777 /mymapreduce1/in 修改 mymapreduce1/in 下的目录权限
一个wordcount代码 别copy运行了我没给你文件格式大致看一下
package mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount{ public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{ private final static IntWritable one = new IntWritable(1); private static String word = new String(); public void map(Object key, Text value, Context context) throws IOException,InterruptedException{ StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()){ word=itr.nextToken(); System.out.println(word); String id=word.substring(0,word.indexOf(" ")); Text word2=new Text(); word2.set(id); context.write(word2,one); } } } public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key,result); } } public static void main(String[] args) throws Exception{ System.setProperty("hadoop.home.dir", "D:\Program Files\windowshadoop\hadoop-2.6.4"); Job job = Job.getInstance(); job.setJobName("WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://hadoop:9000/mymapreduce1/in/buyer_favorite1") ; Path out = new Path("hdfs://hadoop:9000/mymapreduce1/newout") ; FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true)?0:1); } }
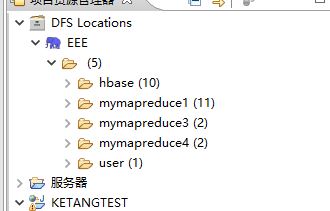
这个DFSLOCATION 自己配吧注意端口号要和你虚拟机hadoop上的端口号相同我这里是9000