郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
Full version of a paper at the 8-th International Conference on Applications and Techniques in Information Security (ATIS 2017) [24].

Abstract
我们建立了一个隐私保护的深度学习系统,在这个系统中,许多学习参与者对组合后的数据集执行基于神经网络的深度学习,而实际上没有向中央服务器透露参与者的本地数据。为此,我们重新回顾了Shokri和Shmatikov(ACM CCS 2015)之前的工作,并指出本地数据信息实际上可能泄漏给诚实但好奇的服务器。然后,我们通过构建一个具有以下特性的增强系统来解决这个问题:(1)没有向服务器泄漏任何信息;(2)与普通的深度学习系统相比,在合并的数据集上,精度保持不变。
我们的系统是深度学习和密码学之间的桥梁:我们将异步随机梯度下降结合加法同态加密应用于神经网络。我们表明,加密的使用给普通的深度学习系统增加的开销是可容忍的。
1 Introduction
1.1 Background
近年来,深度学习(又称深度机器学习)在学术界和工业界都取得了令人振奋的成果,深度学习系统正在接近甚至超过人类水平的精确性。这要归功于算法上的突破和在处理海量数据时应用于神经网络的物理并行硬件。
大量的数据收集,虽然对深度学习至关重要,但也引发了隐私问题。单独而言,收集的照片可以永久保存在公司的服务器上,不受照片所有者的控制。在法律上,隐私和保密方面的担忧可能会妨碍医院和研究中心共享其医疗数据集,使他们无法享受到大规模深度学习联合数据集的优势。
作为一项直接相关的工作,Shokri和Shmatikov(ACM CCS 2015)[26]提出了一个隐私保护的深度学习系统,允许多个参与者保留本地数据集,而参与者可以通过联合数据集学习神经网络模型。为了达到这个结果,在[26]中的系统需要如下:每个学习参与者,使用本地数据,首先计算神经网络的梯度;然后,这些梯度的一部分(例如1%~10%)必须发送到参数云服务器。服务器是诚实但好奇的:在提取个人数据时,它被假定是好奇的;然而,在操作中,它被假定是诚实的。
为了保护隐私,Shokri和Shmatikov的系统允许了一个准确性/隐私权衡(见表1):不共享本地梯度会导致完美的隐私,但不会带来理想的准确性;另一方面,共享所有本地梯度会违反隐私,但会导致很好的准确性。为了妥协,在[26]中共享本地梯度的一部分是保持尽可能少的精度下降的主要解决方案。

1.2 Our contributions
我们证明,在Shokri和Shmatikov系统[26]中,即使是存储在云服务器上的一小部分梯度也可以被利用:即可以勉强地从这些梯度中提取本地数据。举例来说,我们在第3节中展示了一些关于一小部分梯度如何泄漏有用的数据信息的样例。
然后,我们提出了一个新的深度学习系统,使用额外的同态加密来保护诚实但好奇的云服务器上的梯度。所有梯度都被加密并存储在云服务器上。加法同态属性允许对梯度进行计算。我们的系统如第4节所述,如图4所示,在安全性和准确性方面具有以下特点:
Security. 我们的系统不会向诚实但好奇的参数(云)服务器泄露参与者的信息。
Accuracy. 我们的系统达到与所有参与者联合数据集上训练的相应深度学习系统(异步随机梯度下降,见下文)相同的精度。
简言之,我们的系统在这两个方面都享有最好的优势:安全性如密码学,精确性如深度学习。见第4节中的定理1和定理2。
Our tradeoff. 针对云服务器保护梯度会增加学习参与者与云服务器之间的通信成本。我们在表2中表明,增长因子并不大:对于具体数据集MNIST[5]和SVHN[22],小于3。例如,在MNIST的情况下,如果每个学习参与者需要在每次上传或下载时向服务器传递0.56MB的明文梯度;那么在我们的基于LWE的加密系统中,每次上传或下载时相应的通信成本将变为
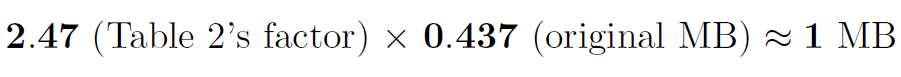
它需要大约8毫秒才能通过1 Gbps信道传输。技术细节见第5节和第6节。
在计算方面,我们估计使用神经网络的系统在对MNIST数据集进行训练和测试时,大约在2.25小时内完成,以获得约97%的准确度,这与[2]中给出的相同类型神经网络的结果一致。
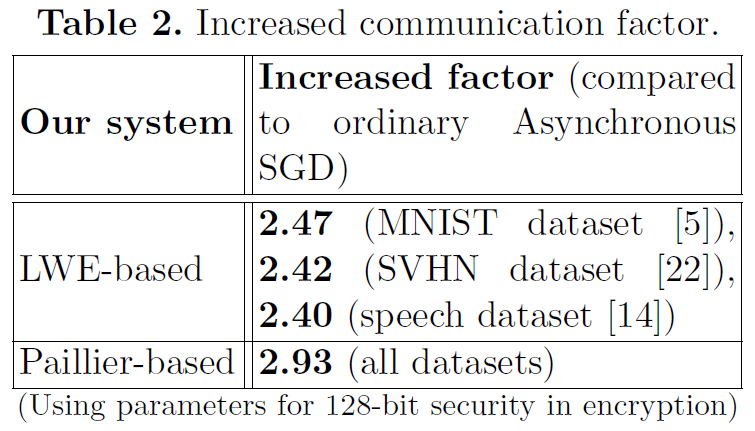
Discussion on the tradeoffs. 由于我们的系统对好奇的服务器使用了额外的同态加密,我们表明[26]中的准确性/隐私之间的权衡可以转移到我们的效率/隐私中。与普通的深度学习相比,[26]的准确性/隐私权衡可能会使隐私保护的深度学习不那么具有吸引力,因为准确性是该领域的主要吸引力。如果使用更多的处理单元和更专用的编程代码,我们可以解决效率/隐私权衡,保持普通的深度学习准确性不变。
1.3 Technical overviews
简单的比较见表1。下面我们将介绍基本的技术特性。
Asynchronous SGD (ASGD) [14, 25], no privacy protection. 我们的系统和[26]的系统都依赖这样一个事实,即神经网络可以通过一个称为异步SGD[14,25]的SGD变体进行训练,该变体具有数据并行性和模型并行性。具体来说,首先对神经网络的全局权重向量Wglobal进行随机初始化。然后,在每次迭代时,在本地数据集(数据并行性)上运行神经网络的副本,并将相应的本地梯度向量Glocal发送到云服务器。对于每个Glocal,云服务器随后更新全局参数,如下所示:
![]()
其中α是学习率。更新后的全局参数Wglobal将广播到所有副本,然后由这些副本替换旧的权重参数。更新和广播Wglobal的过程被重复,直到达到预先定义的成本函数(基于交叉熵或平方误差)所需的最小值。对于模型并行,通过向量Wglobal和Glocal的分量并行计算(1)处的更新。
Shokri-Shmatikov systems. [26][第5节]中的系统可以通过以下原因称为梯度选择性ASGD。在[26][第5节]中,(1)处的更新规则修改如下:
![]() 其中,向量
其中,向量![]() 包含选择性(即1%~10%)的梯度Glocal。使用(2)进行的更新允许每个参与者选择要在全局共享的梯度,以降低将参与者本地数据集上的敏感信息泄漏到云服务器的风险。但是,如第3节所示,即使一小部分梯度也会向服务器泄漏信息。
包含选择性(即1%~10%)的梯度Glocal。使用(2)进行的更新允许每个参与者选择要在全局共享的梯度,以降低将参与者本地数据集上的敏感信息泄漏到云服务器的风险。但是,如第3节所示,即使一小部分梯度也会向服务器泄漏信息。
在[26][第7节],Shokri-Shmatikov展示了一种使用差异隐私来对抗梯度间接泄漏的附加技术。他们的策略是将拉普拉斯噪声添加到(2)中的![]() 。由于噪声的存在,该方法降低了学习精度,那是深度学习的主要吸引力。
。由于噪声的存在,该方法降低了学习精度,那是深度学习的主要吸引力。
Our system. 我们设计的系统可以被称为梯度加密ASGD,原因如下。在第4节的系统中,我们使用以下更新公式
![]()
其中E是同态加密,支持密文上的加法。解密密钥只有参与者知道,而云服务器不知道。因此,诚实但好奇的云服务器对每个Glocal一无所知,无法获取有关每个本地参与者数据集的信息。尽管如此,作为
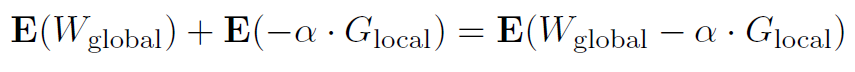
通过E的加法同态属性,每个参与者将通过解密得到正确更新的Wglobal。此外,当(1)处的原始更新在向量Wglobal和Glocal的部分中并行时,我们的系统会相应地对每个部分应用同态加密。
此外,为了确保同态密文的完整性,每个客户端都将使用一个安全的通道,如TLS/SSL(彼此不同)来与服务器进行同态密文通信。
Extension of our system. 我们使用(3)中的加密更新规则的想法可以扩展到其他基于SGD的机器学习方法。例如,我们的系统可以很容易地与逻辑回归一起使用,分布式学习参与者每个人都拥有一个本地数据集。在这种情况下,唯一的变化是每个参与者将运行基于SGD的逻辑回归而不是深度学习的神经网络。
1.4 More related works
Gilad Bacharch等人[16]提出了一种称为CryptoNets的系统,它允许同态加密的数据对一个已经训练过的神经网络进行前馈。由于CryptoNets假定神经网络中的权值事先经过训练,因此该系统的目标是对单个数据项进行预测。
本文和[26]的目标与[16]的目标不同,因为我们的系统和Shokri-Shmatikov的目标是利用多个数据源训练权重,而CryptoNets[16]则没有。
我们认为云服务器是本文的对手,而学习参与者被视为诚实的实体。这是因为在我们的场景中,学习参与者被视为金融机构或医院等组织,依法承担责任。我们的场景和对手模型与Hitaj等人[18]不同,调查不诚实的学习参与者。
Mohassel和Zhang[21]研究了在两个假设不勾结的服务器上训练线性回归、逻辑回归和神经网络的隐私保护方法。这个模型和我们的不同。
在[7,8,10]中提出了仅使用加法同态加密的隐私保护线性/逻辑回归系统。
1.5 Differences with the conference version
本文的初步版本见[24]。这个完整的版本概括了主系统,在诚实但好奇的服务器上处理多个处理单元,并允许学习参与者上传/下载部分加密的梯度。此外,还给出了计算成本。
2 Preliminaries
2.1 On additively homomorphic encryption
Definition 1. (Homomorphic encryption) 公钥加法同态加密(PHE)方案由以下(可能是概率的)多项式时间算法组成。
- ParamGen(1λ) 一> pp:λ是安全参数,公共参数pp在下面的算法中是隐式输入的。
- KeyGen(1λ) 一> (pk, sk):pk是公钥,sk是密钥。
- Enc(pk, m) 一> c:概率加密算法产生c,即信息m的密文。
- Dec(sk, c) 一> m:解密算法返回c的明文信息m。
- Add(c, c'): 对于密文c和c‘,输出是明文和cadd的密文。
- DecA(sk, cadd):解密cadd以获得明文和。
密文对所选明文攻击的不可区分性[17](以下简称CPA Security)确保了密文不会泄漏任何信息。
2.2 On deep machine learning
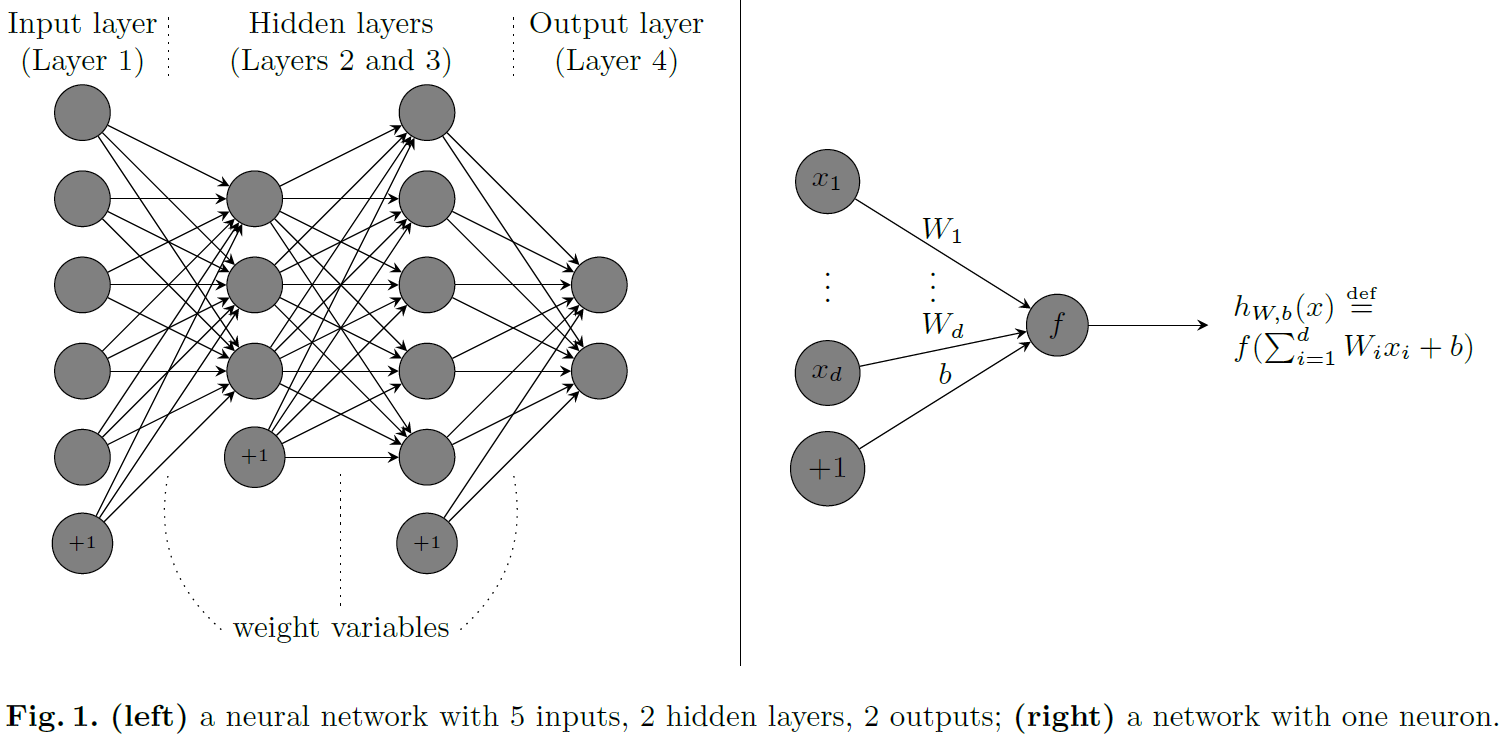
Some concepts and notations. 深度机器学习可以看作是一套应用于神经网络的技术。图1是一个神经网络,有5个输入、2个隐层和2个输出。带+1的节点表示偏置项。神经元节点通过权重变量连接。在神经网络的深度学习结构中,可以有多个层,每层有数千个神经元。
每个神经元节点(除了偏置节点)都与激活函数f相关。深度学习中的函数样例为f(z) = max{0, z}(线性整流),f(z) = (ez - e-z) / (ez + e-z)(双曲正切),以及f(z) = (1 + e-z)-1(sigmoid)。第l+1层的输出,表示为a(l+1),计算为a(l+1) = f(W(l)a(l) + b(l)),其中连接第l与l+1层的权重为(W(l), b(l)),a(l)是第l层的输出。
在给定训练数据集的情况下,学习任务是确定这些权重变量,以最小化预先定义的成本函数,如交叉熵或平方误差成本函数[3]。成本函数可以在训练数据集中的所有数据项上计算,也可以在训练数据集中t个元素的子集(称为小批量)上计算。将后一种情况下的成本函数表示为J|batch|=t。在t=1的极端情况下,对应于最大随机性,J|batch|=1是定义在单个数据项上的成本函数。
Stochastic gradient descent (SGD). 设W为包含所有权重变量的扁平化向量,即取神经网络中的所有权重,连续排列,形成向量W。


Asynchronous (aka. Downpour) SGD [14, 25]. 通过(4)和(5),只要可以计算梯度G,就可以更新权重W。因此,计算G时使用的数据可以是分布式的(即数据并行)。此外,可以通过考虑向量的单独部分(即模型并行性)来并行更新过程。
具体来说,异步SGD使用神经网络的多个副本。在每次执行之前,每个副本都将从参数服务器下载最新的权重;并且每个副本都在一个数据碎片上运行,该碎片是训练数据集的一个子集。为了在服务器具有多个处理单元![]() 时使用并行计算的能力,异步SGD将其权重向量W和梯度G拆分为npu个部分,即
时使用并行计算的能力,异步SGD将其权重向量W和梯度G拆分为npu个部分,即![]() 和
和![]() ,因此在(5)上的梯度规则变为:
,因此在(5)上的梯度规则变为:
![]()
其中公式在处理单元PUi上计算。由于处理单元![]() 可以并行运行,异步SGD显著提高了深度网络训练的规模和速度,如实验所示[14]。
可以并行运行,异步SGD显著提高了深度网络训练的规模和速度,如实验所示[14]。 
3 Gradients leak information
本节展示了小部分梯度可能会泄露本地数据的信息。


- 注意到ηk / η = xk。因此,如果ηk和η被共享到云服务器,xk将完全泄漏。例如,如果按照[26]中的建议随机选择1%的本地梯度,共享给服务器,那么ηk和η共享的概率是(1/100)x(1/100)= 1/104,这是不可忽略的。
- 注意到梯度ηk与输入xk成正比(对所有的1 ≤ i ≤ d)。因此,当x =(x1,…,xd)是一张图像时,可以使用梯度生成相关的“成比例”图像,然后通过猜测获得真实值y。


4 Our system:privacy-preserving deep learning without accuracy decline
我们的系统如图4所示,由一个公共云服务器和N个(e.g.=10x)学习参与者组成。
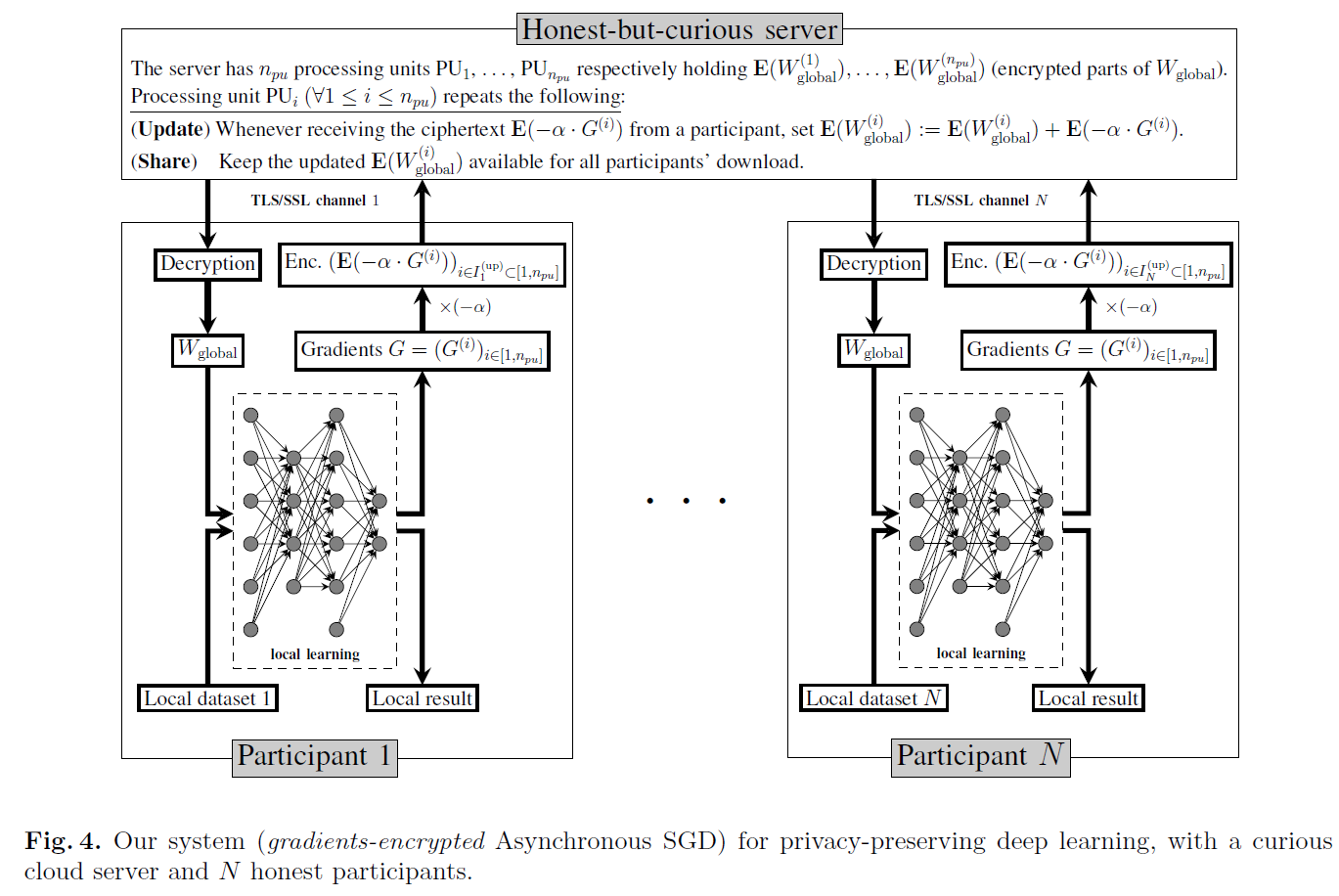
Learning Participants. 参与者共同设置公钥pk和密钥sk,以实现加法同态加密方案。密钥sk对云服务器保密,但所有学习参与者都知道。每个参与者将建立一个彼此不同的TLS/SSL安全通道,以通信和保护同态密文的完整性。
然后,参与者在本地保存他们的数据集,运行一个基于深度学习的神经网络副本。运行本地深度学习的初始(随机)权重Wglobal由参与者1初始化,参与者最初也向服务器发送![]() ,其中
,其中![]() 也是构成Wglobal第i部分的向量。将神经网络每次执行后得到的梯度向量G分解为npu个部分,即
也是构成Wglobal第i部分的向量。将神经网络每次执行后得到的梯度向量G分解为npu个部分,即![]() ,然后与学习率α相乘,最后使用公钥pk进行加密。来自每个学习参与者的加密结果
,然后与学习率α相乘,最后使用公钥pk进行加密。来自每个学习参与者的加密结果![]() 被发送到服务器的处理单元PUi。同样值得注意的是,学习率α可以根据[14]中的描述在每个学习参与者进行本地的自适应变化。
被发送到服务器的处理单元PUi。同样值得注意的是,学习率α可以根据[14]中的描述在每个学习参与者进行本地的自适应变化。
如图4所示,每个参与者1 ≤ k ≤ n将执行以下步骤:
- 下载服务器处理单元PUj中存储的所有密文
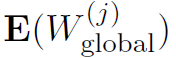 (所有的
(所有的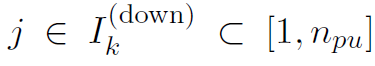 )。通常
)。通常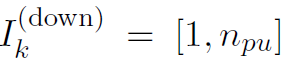 ,即参与者将下载全局权重的所有加密部分,但如果学习参与者的下载带宽受限,则有可能出现
,即参与者将下载全局权重的所有加密部分,但如果学习参与者的下载带宽受限,则有可能出现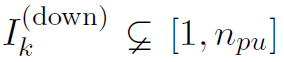 。
。 - 使用密钥sk解密上述密文,以获取
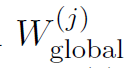 (所有的
(所有的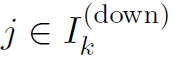 ),并将这些值替换到
),并将这些值替换到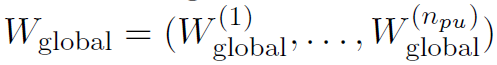 的相应位置。
的相应位置。 - 从本地数据集中获取一小批数据。
- 使用步骤2和3中的Wglobal值和数据项,计算相对于变量Wglobal的梯度
 。
。 - 加密并发送密文
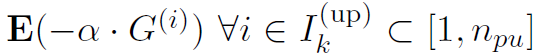 回服务器的相应处理单元PUi。上传的子集
回服务器的相应处理单元PUi。上传的子集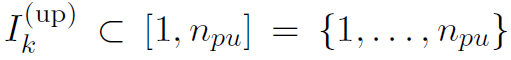 取决于参与者k的选择。对于完全上传,所有加密的梯度
取决于参与者k的选择。对于完全上传,所有加密的梯度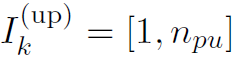 都将上传到服务器。
都将上传到服务器。
Wglobal加密部分的下载和上传可以在两个方面异步进行:参与者彼此独立;处理单元也相互独立。
Cloud Server. 云服务器是递归更新加密权重参数的常用地方。特别是,服务器上的每个处理单元PUi在接收到任何加密E(α·G(i))后,计算
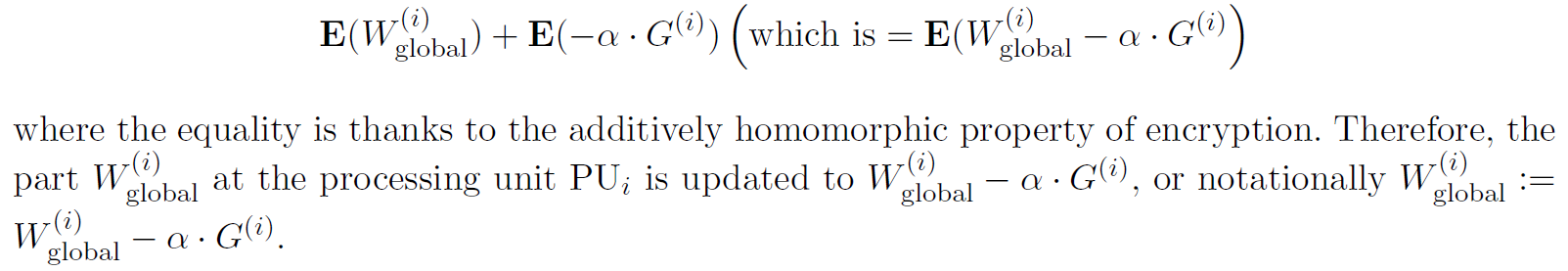
Theorem 1 (Security against the cloud server). 图4中的系统没有向诚实但好奇的云服务器泄露学习参与者的信息,前提是同态加密方案是CPA安全的。
Proof. 参与者只向云服务器发送加密的梯度。因此,如果加密方案是CPA安全的,那么参与者的数据就不会泄露任何信息。

5 Instantiations of our system
在本节中,我们使用加法同态加密方案来实例化第4节中的系统。我们使用以下方案来显示我们系统的两个实例:基于LWE的加密(modern, potentially post-quantum)和Paillier加密(classical,smaller key sizes,not post-quantum)。
5.1 Using an LWE-based encryption
注:
1、![]() 是长度为q,以0为中心的整数集;
是长度为q,以0为中心的整数集;
2、通常p << q;
3、![]() ;
;
4、![]() 意味着“随机均匀采样”;
意味着“随机均匀采样”;
5、ngd:用prec位表示的梯度数量;ngradupd:云服务器每个处理单元更新的梯度数目;npu:云服务器处理单元的数目。










Environments. 我们的同态加密代码是在C++中,基准是在一台Xeon CPU E5-2660 v3@ 2.60GHz服务器之上。为了估计每个学习参与者和服务器之间的通信速度,我们假设一个1 Gbps的网络。为了测量多层感知机(MLP)的运行时间,我们在Cuda-8.0和GPU Telsa K40m上使用了TensorFlow 1.1.0库[4]。
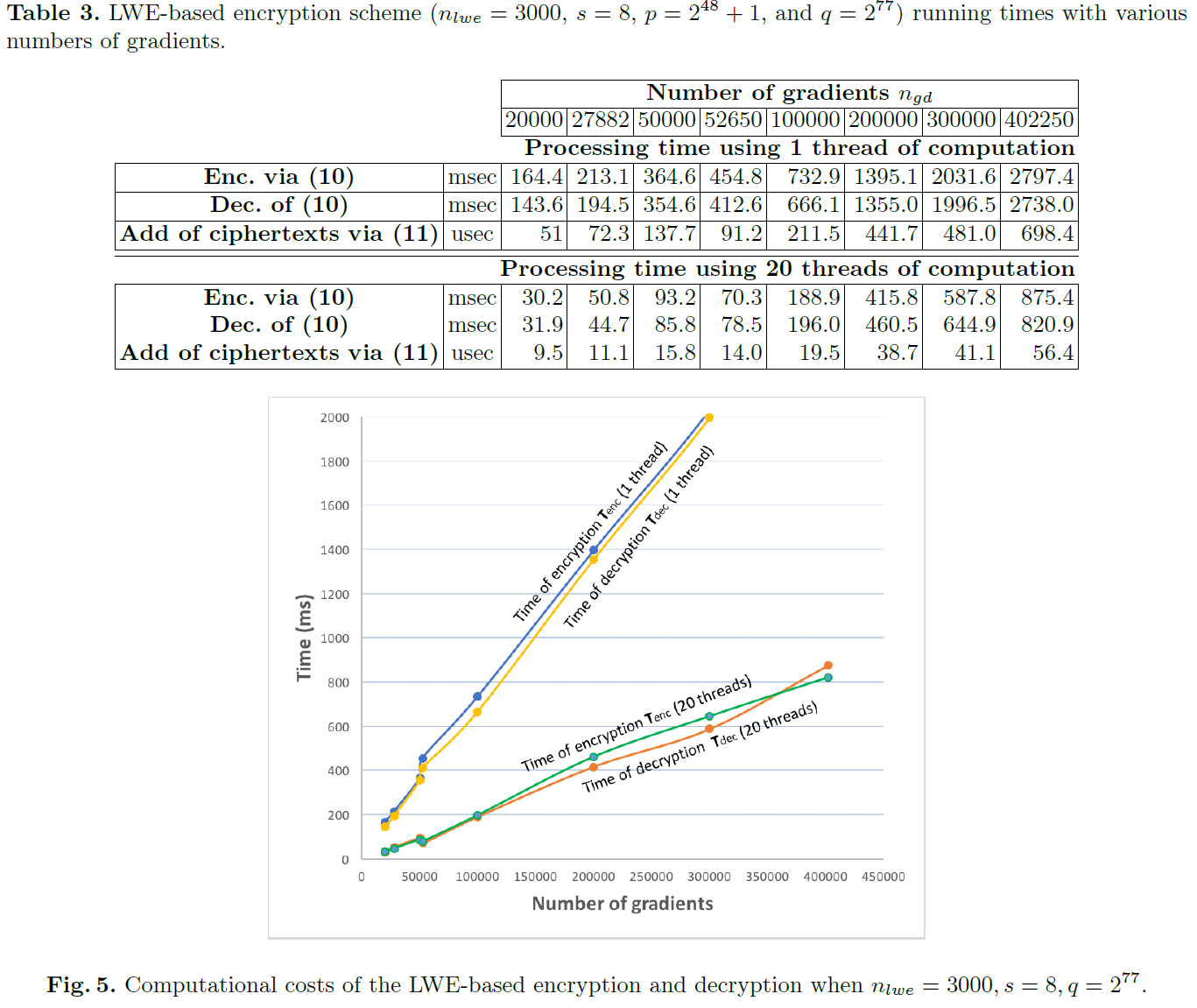
Time of encryption, decryption and addition. 表3给出了加密、解密和加法的时间,取决于梯度ngd的数量,使用nlwe=3000,s=8,p=248+1和q=277。图5分别描述了使用1个线程和20个计算线程进行加密和解密的时间。
Multilayer Perceptron (MLP). 考虑采用784(输入)— 128(隐层)— 64(隐层)— 10(输出)形式的MLP。这个网络的梯度数是(784+1)*128+(128+1)*64+(64+1)*10 = 109386。对于32位精度,这些梯度在明文中大约为109386*32/(8*106) ≈ 0.437 MB。根据第6.1节计算,这些梯度的密文为0.437*2.47 ≈ 1.0 MB,可通过1 Gbps通信信道在0.008秒(= 8 ms)内发送。此MLP在一批数据大小为50(MNIST图片)上的原始运行时间为![]() ≈ 4.6(ms)。因此,
≈ 4.6(ms)。因此, 
如定理2所示,我们的系统精度可以与异步SGD的精度相同。因此,本文提出了一种基于MNIST的异步SGD的精度估计方法,该方法包括随机抽取的6*104张训练图像和104张测试图像。如上所述,批大小为50。初始权重从均值为0,标准差为0.1的正态分布中随机选取(通过Tensorflow中的random_normal函数)。激活函数是Tensorflow中的relu函数。Adam优化器(AdamOptimizer)用于输入学习率为10-4的训练,且没有随机失活。经过2分钟的2*104次迭代后,我们的Tensorflow代码在测试集中的精确度达到了97%左右。
7 Conclusion
我们表明,即使在参数云服务器上部分共享梯度(如[26]所示),也可能泄漏数据信息。然后,我们提出了一个新的系统,该系统利用加法同态加密来保护梯度免受好奇服务器的攻击。除了隐私保护,我们的系统还具有不降低深度学习准确性的特点。
References
1. Machine Learning Coursera's course. https://www.coursera.org/learn/machine-learning.
2. MNIST results. http://yann.lecun.com/exdb/mnist/.
3. Stanford Deep Learning Tutorial. http://deeplearning.stanford.edu.
4. Tensorflow. https://www.tensorflow.org.
5. The MNIST dataset. http://yann.lecun.com/exdb/mnist/.
6. Y. Aono, X. Boyen, L. T. Phong, and L. Wang. Key-private proxy re-encryption under LWE. In G. Paul and S. Vaudenay, editors, Progress in Cryptology - INDOCRYPT 2013. Proceedings, volume 8250 of Lecture Notes in Computer Science, pages 1-18. Springer, 2013.
7. Y. Aono, T. Hayashi, L. T. Phong, and L. Wang. Privacy-preserving logistic regression with distributed data sources via homomorphic encryption. IEICE Transactions, 99-D(8):2079-2089, 2016.
8. Y. Aono, T. Hayashi, L. T. Phong, and L. Wang. Scalable and secure logistic regression via homomorphic encryption. In Proceedings of the Sixth ACM on Conference on Data and Application Security and Privacy,CODASPY, pages 142-144, 2016.
9. Y. Aono, T. Hayashi, L. T. Phong, and L. Wang. Efficient key-rotatable and security-updatable homomorphic encryption. In Proceedings of the Fifth ACM International Workshop on Security in Cloud Computing, SCC@AsiaCCS 2017, pages 35-42, 2017.
10. Y. Aono, T. Hayashi, L. T. Phong, and L. Wang. Input and output privacy-preserving linear regression. IEICE Transactions, 100-D(10), 2017.
11. W. Banaszczyk. New bounds in some transference theorems in the geometry of numbers. Mathematische Annalen, 296(1):625-635, 1993.
12. W. Banaszczyk. Inequalities for convex bodies and polar reciprocal lattices in Rn. Discrete & Computational Geometry, 13(1):217-231, 1995.
13. I. Chillotti, N. Gama, M. Georgieva, and M. Izabachene. Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds. In Advances in Cryptology - ASIACRYPT 2016 - 22nd International Conference on the Theory and Application of Cryptology and Information Security, Proceedings, Part I, pages 3-33, 2016.
14. J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. V. Le, M. Z. Mao, M. Ranzato, A. W. Senior, P. A. Tucker, K. Yang, and A. Y. Ng. Large scale distributed deep networks. In P. L. Bartlett, F. C. N. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, 26th Annual Conference on Neural Information Processing Systems 2012., pages 1232-1240, 2012.
15. J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res., 12:2121-2159, July 2011.
16. R. Gilad-Bachrach, N. Dowlin, K. Laine, K. E. Lauter, M. Naehrig, and J. Wernsing. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In M. Balcan and K. Q. Weinberger, editors, Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 of JMLR Workshop and Conference Proceedings, pages 201-210. JMLR.org, 2016.
17. O. Goldreich. The Foundations of Cryptography - Volume 2, Basic Applications. Cambridge University Press, 2004.
18. B. Hitaj, G. Ateniese, and F. Pérez-Cruz. Deep models under the GAN: information leakage from collaborative deep learning. CoRR, abs/1702.07464, 2017.
19. R. Lindner and C. Peikert. Better key sizes (and attacks) for LWE-based encryption. In A. Kiayias, editor, Topics in Cryptology - CT-RSA 2011, volume 6558 of Lecture Notes in Computer Science, pages 319-339. Springer, 2011.
20. M. Liu and P. Q. Nguyen. Solving BDD by enumeration: An update. In E. Dawson, editor, Topics in Cryptology - CT-RSA 2013. Proceedings, volume 7779 of Lecture Notes in Computer Science, pages 293{309. Springer, 2013.
21. P. Mohassel and Y. Zhang. Secureml: A system for scalable privacy-preserving machine learning. In 2017 IEEE Symposium on Security and Privacy, pages 19-38, 2017.
22. Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, 2011.
23. P. Paillier. Public-key cryptosystems based on composite degree residuosity classes. In J. Stern, editor, Advances in Cryptology - EUROCRYPT '99, Proceeding, volume 1592 of Lecture Notes in Computer Science, pages 223-238. Springer, 1999.
24. L. T. Phong, Y. Aono, T. Hayashi, L. Wang, and S. Moriai. Privacy-preserving deep learning: Revisited and enhanced. In Applications and Techniques in Information Security - 8th International Conference, ATIS 2017, Proceedings, pages 100{110, 2017.
25. B. Recht, C. Ré, S. J. Wright, and F. Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett, F. C. N. Pereira, and K. Q. Weinberger, editors, NIPS 2011, pages 693-701, 2011.
26. R. Shokri and V. Shmatikov. Privacy-preserving deep learning. In I. Ray, N. Li, and C. Kruegel, editors, Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, 2015, pages 1310-1321. ACM, 2015.
A CPA security of the LWE-based homomorphic encryption scheme


B Proof of Lemma 1

