1、torch.nn.state_dict():
返回一个字典,保存着module的所有状态(state)。
parameters和persistent_buffers都会包含在字典中,字典的key就是parameter和buffer的names。
例子:
import torch
from torch.autograd import Variable
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv2 = nn.Linear(1, 2)
self.vari = Variable(torch.rand([1]))
self.par = nn.Parameter(torch.rand([1]))
self.register_buffer("buffer", torch.randn([2,3]))
model = Model()
print(model.state_dict().keys())
odict_keys(['par', 'buffer', 'conv2.weight', 'conv2.bias'])
字典迭代形式{<class 'str'>:<class 'torch.Tensor'>, ... }
2、@与*的区别
@表示用tensor进行矩阵相乘;
*表示用tensor进行矩阵逐元素相乘;
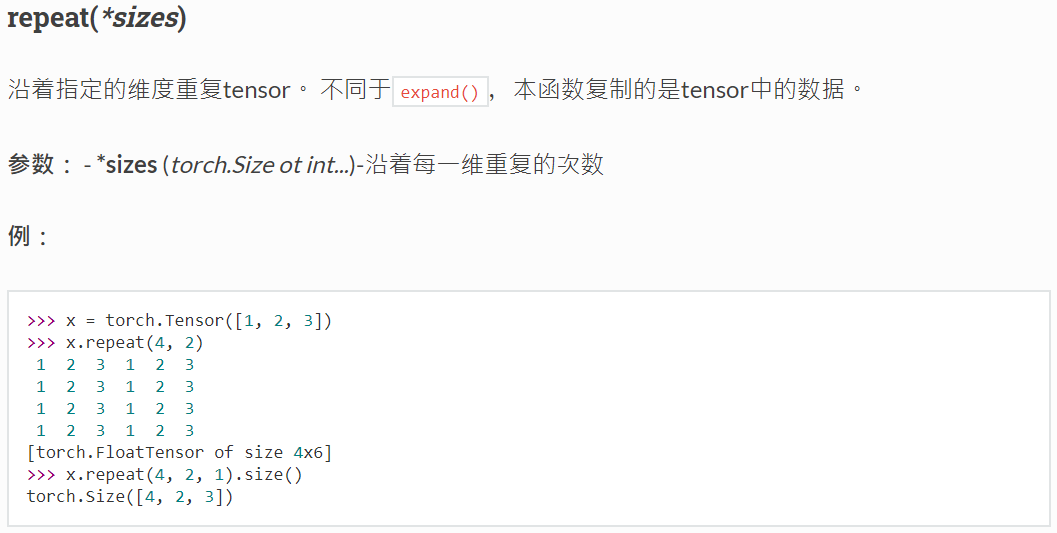
3、沿着指定的维度重复tensor
4、交叉熵
CrossEntropyLoss()是softmax和负对数损失的结合;
如果用 nn.BCELoss()计算二进制交叉熵, 需要先将logit经sigmoid()层激活再送入nn.BCELoss()计算损失。
5、pytorch: can't optimize a non-leaf Tensor
需要先把Tensor放入到GPU中,然后再设置Tensor.requires_grad=True。
6. 类别标签转换one-hot编码
# one_hot = torch.zeros(batch_size, class_num).scatter_(1, label.long().view(batch_size, 1), 1.)
one_hot = torch.nn.functional.one_hot(label, class_num)
7. RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
简单来说,需要将x += 1 这种改成 x = x+1;
原因:x+=1的值会直接在原值上面做更新,是inplace=True的情况,而后一种是先让x+1然后赋值给x,属于inplace=False。
8. Pytorch: Trying to backward through the graph a second time, but the buffers have already been freed
loss.backward()改成loss.backward(retain_graph=True)