最优化理论与方法学习笔记
一、引论
1、范数
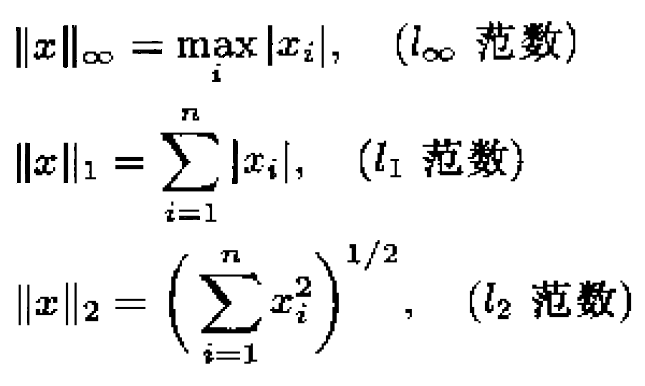

Frobenius范数:
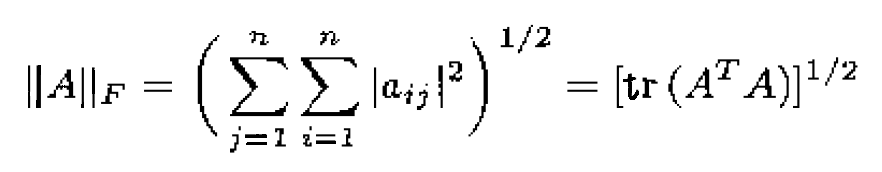
加权Frobenius范数和加权l2范数(其中M是n x n的对称正定矩阵):
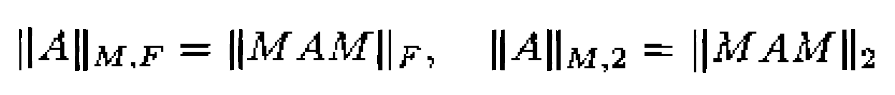
椭圆向量范数:
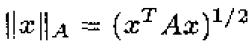
特别,我们有
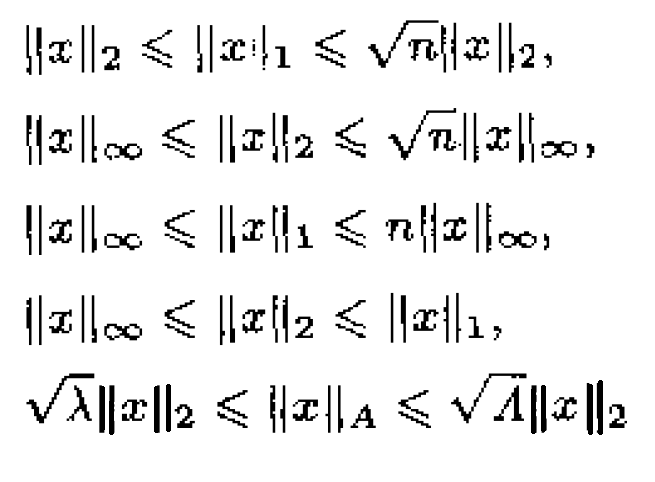
![]()
关于范数的几个重要不等式是:


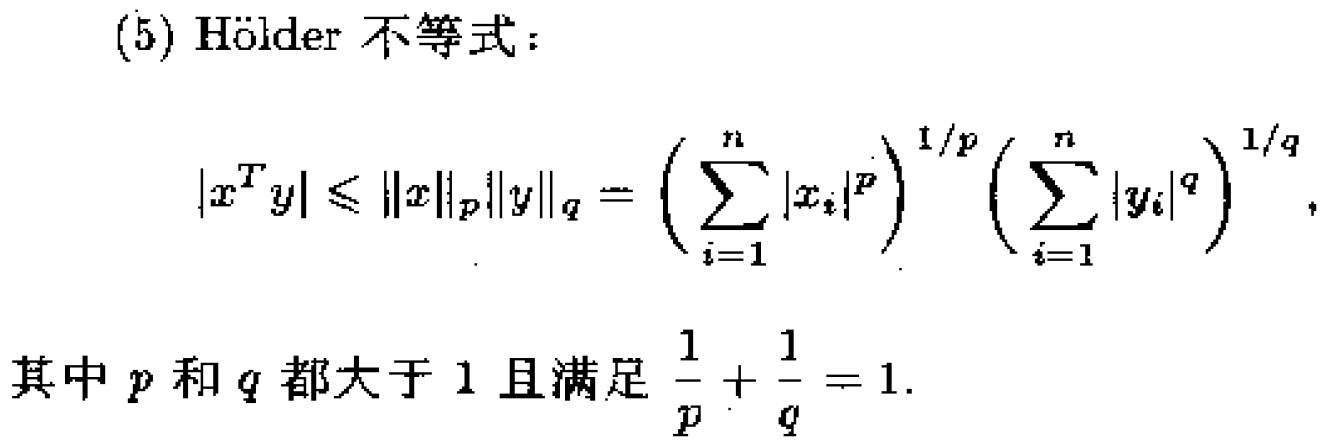
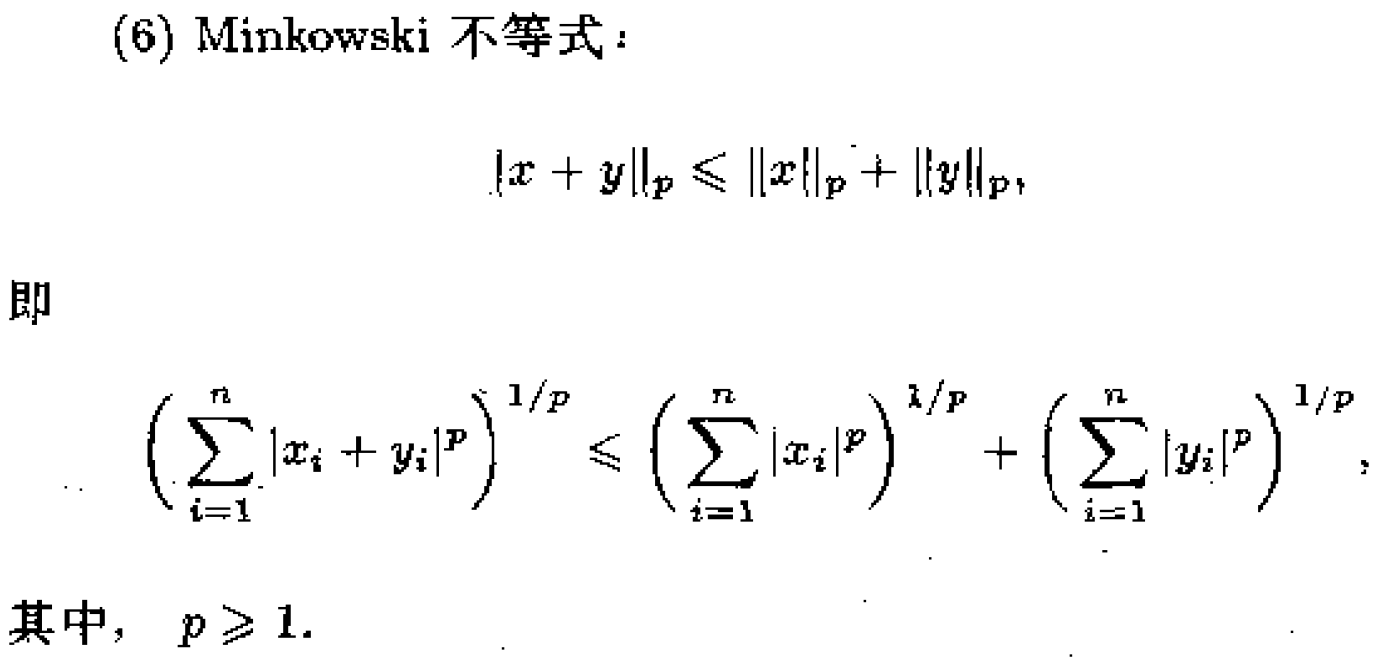
2、无约束问题的最优性条件
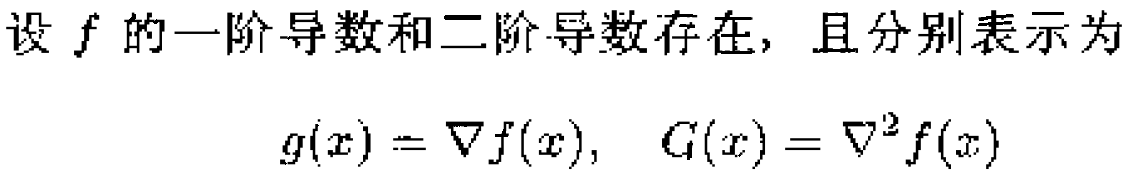
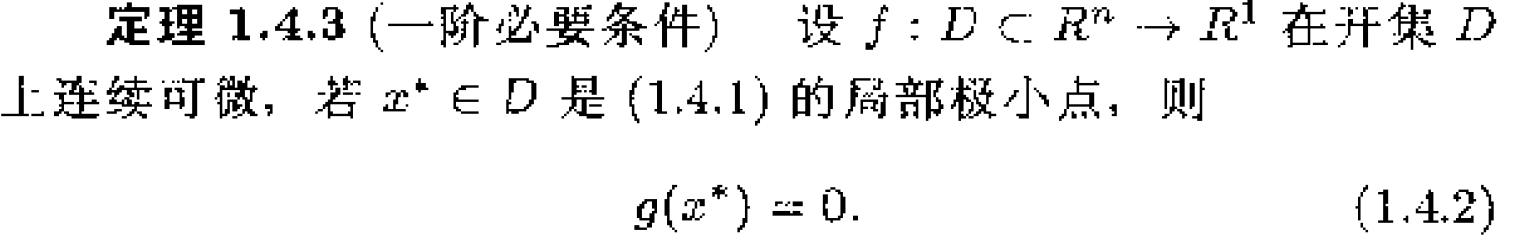


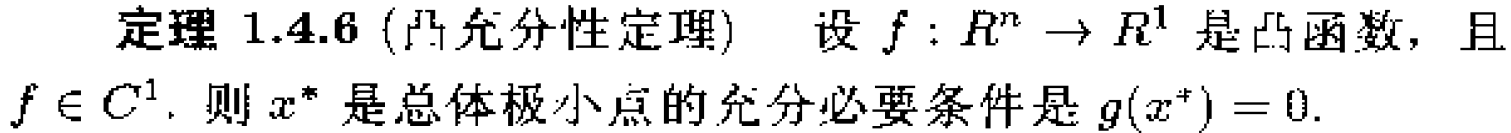
3、最优化方法的结构



二、一维搜索
1、引论
所谓一维搜索,又称线性搜索,就是指单变量函数的最优化,它是多变量函数最优化的基础。
一维搜索的主要结构如下:首先确定包含问题最优解的搜索区间,再采用某种分割技术或插值方法缩小这个区间,进行搜索求解。
确定搜素区间的一种简单方法叫进退法,其基本思想是从一点出发,按一定步长,试图确定出函数呈现“高-低-高”的三点。一个方向不成功,就退回来,再沿相反方向寻找。


2、分割方法







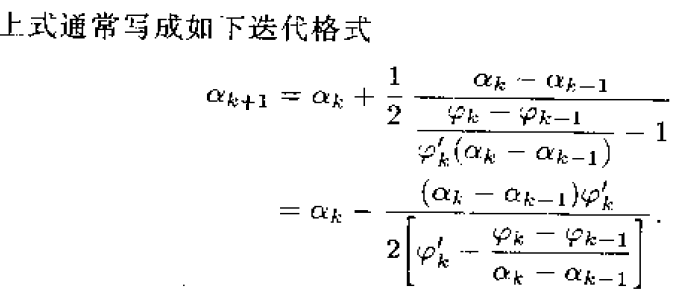
3、插值法


牛顿法具有局部二阶收敛速度。





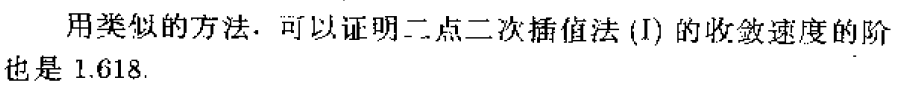






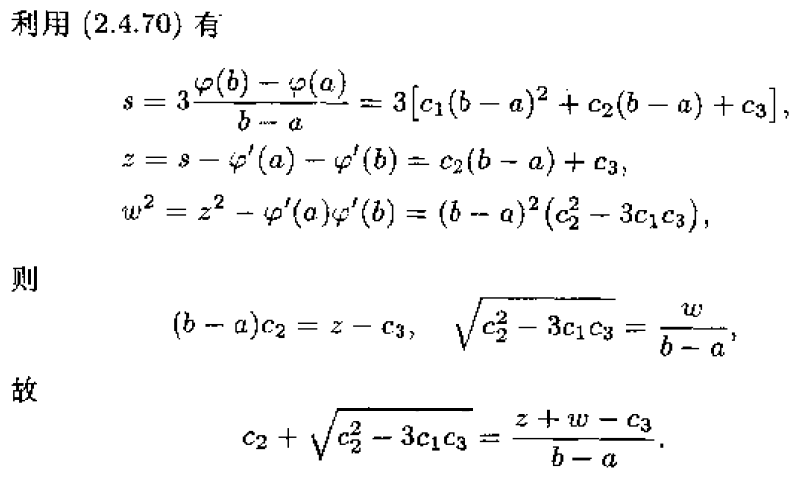

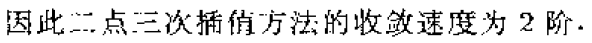
三、牛顿法
1、最速下降法(梯度下降法,简称梯度法)—— P118


收敛性:线性收敛
2、两点步长梯度法 —— P127
![]() 或
或 ![]()
其中,
![]()

收敛性:R-超线性收敛
3、牛顿法 —— P131

对于正定二次函数,牛顿法一步即可达到最优解。对于非二次函数,牛顿法并不能保证经有限次迭代求得最优解,但由于目标函数在极小点附近近似于二次函数,故当初始点靠近极小点时,牛顿法的收敛速度一般是快的。牛顿法具有局部收敛性和二阶收敛速度。
应该注意的是,当初始点远离最优解时,Gk不一定正定。牛顿方向不一定是下降方向,其收敛性不能保证。这说明恒取步长因子为1的牛顿法是不合适的,应该在牛顿法中采用某种一维搜索来确定步长因子。但是应该强调,仅当步长因子{ ak }收敛到1时,牛顿法才是二阶收敛的。这时牛顿法的迭代公式为

其中ak是一维搜索产生的步长因子。

这种带步长因子的牛顿法是总体收敛的。
4、修正牛顿法 —— P136
牛顿法面临的主要困难是Hesse矩阵Gk不正定。这时候二次模型不一定有极小点,甚至没有平稳点。当Gk不定时,二次模型函数是无界的。