1. 进程池
进程池,只开指定数目的进程数(一般是CPU内核数+1)这样调度多个任务时,执行效率要比同时开多个进程执行效率要高很多(因为当同时开多个进程时,开进程是很占用资源的,时间都浪费在开进程上面了)
进程池方法-----p.map()
from multiprocessing import Pool import time import random def func(i): time.sleep(random.random()) # 子进程执行时间有差异,然后可以看出进程池其实是异步的,每次并发五个进程,但是随着进程执行时间不一样所以顺序也不同 print(i) if __name__=="__main__": p=Pool(5) # 进程池 只开五个进程 p.map(func,range(20)) # 执行20个任务,但进程池只开5个进程 p.close() # 不允许在向进程池中发任务,一定要放在join()方法之前 p.join() # 主进程中等待子进程执行完(p.close() p.join()一定要写,普通的进程(Process)主进程会等待子进程执行完毕; # 但是进程池,主进程不会等子进程,如果不写这两句,主进程只管开5个进程,然后不等子进程执行完,就会结束了)
运行结果: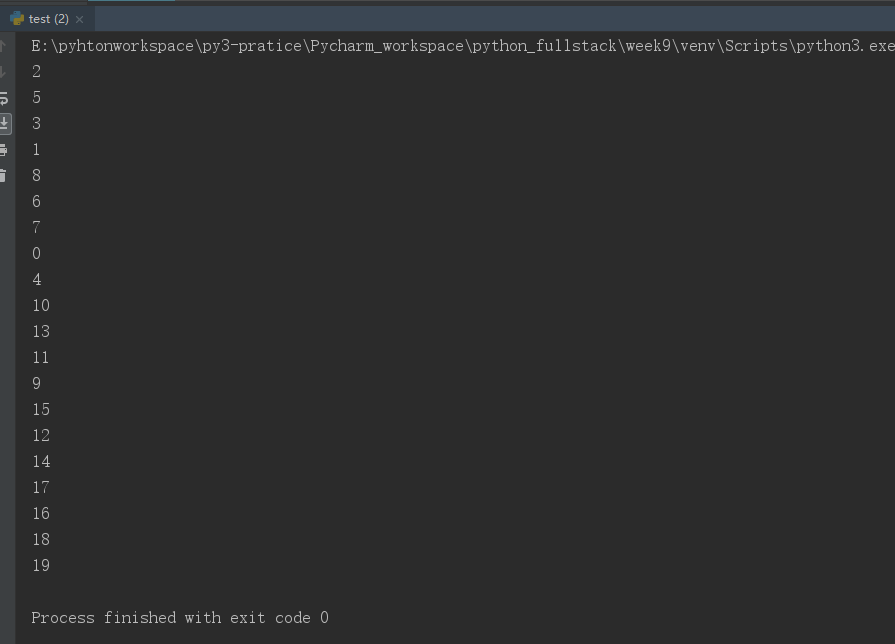
我们可以比较一下,调度100个任务执行func函数,使用进程池和开100个进程执行效率上的差异:(开进程池的方法时间要少很多)
from multiprocessing import Process from multiprocessing import Pool import time def func(i): # 开的子进程执行func函数 i+=1 if __name__=="__main__": p=Pool(5) # 进程池中开5个进程(同一时间只能并发5个) start=time.time() # 计算开进程池执行100个任务所需要的时间 p.map(func,range(100)) # 调度100个任务,func是所开的进程需要执行的函数,第二个参数必须是iterable对象,把每一个元素都作为第一个参数func的参数传进去 p.close() # 不允许再向进程池中调度任务,也就是任务在上面一句都已经发送完了,p.close()一定要写在p.join()之前 p.join() # 主进程等待子进程执行完毕(进程池中开的子进程,主进程是不会等待的,所以一定要写上p.close() p.join()) print("开进程池调度100个任务所使用的时间为:",time.time()-start) P=[] # 用来存放所开的进程,这样是为了计算开一百个进程所需要的时间,肯定得等100个进程执行完毕才可以计算; # 所以需要用到join()判断进程是否执行完毕,但是直接写p.join()就会变为同步的(一个进程执行完,才去开下一个进程)达不到并发的效果; start=time.time() # 计算开100个进程所需要的时间 for i in range(100): # 第二种方法,调度100个任务,开100个进程来执行 p=Process(target=func,args=(i,)) p.start() P.append(p) [p.join() for p in P] # 开的100个进程全都执行完毕 print("开100个进程去执行func所需要的时间:",time.time()-start)
运行结果: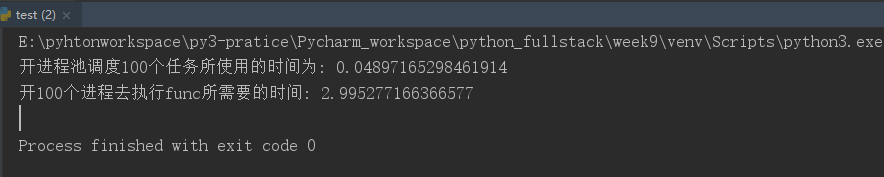
所以执行同样的任务,开进程池比同时开多个进程效率要高很多;
2. 进程池的其他方法--p.apply()-----是一种同步提交任务的机制;
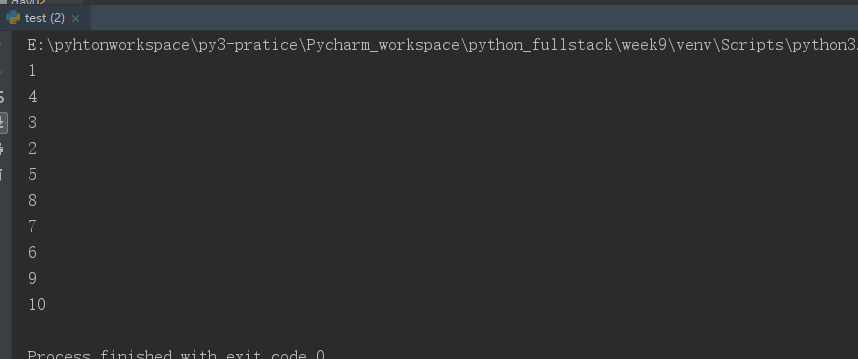
from multiprocessing import Pool import time import random def func(i): time.sleep(random.random()) # 模拟每个进程执行时间是有差异的 i+=1 print(i) if __name__=="__main__": p=Pool(5) # 进程池中开五个进程,实现5个并发的效果 for i in range(10): p.apply(func,args=(i,)) # 进程池的apply方法是一种同步提交任务的机制,所以无法实现高并发(所以不用这种方法) p.close() # 不允许再向进程池中添加任务 p.join() # 主进程等待子进程执行完毕
运行结果:
3. 进程池的其他方法---p.apply_async()---是一种异步提交数据的机制
from multiprocessing import Pool import time import random def func(i): time.sleep(random.random()) # 模拟每个进程执行时间是有差异的 i+=1 print(i) if __name__=="__main__": p=Pool(5) # 进程池中开五个进程,实现5个并发的效果 for i in range(10): p.apply_async(func,args=(i,)) # 进程池的apply_async()方法是一种异步提交任务的机制 p.close() # 不允许再向进程池中添加任务 p.join() # 主进程等待子进程执行完毕
运行结果:(最多5个并发)
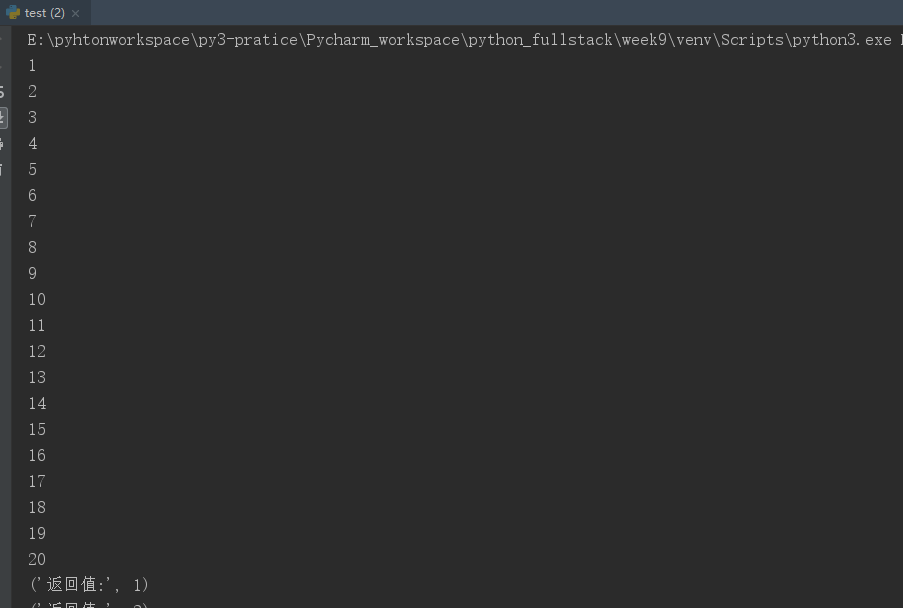
其实使用进程池还可以获得子进程的返回值
from multiprocessing import Pool import time import random def func(i): time.sleep(1) i+=1 print(i) return ("返回值:",i) if __name__=="__main__": p=Pool(5) ret_lst=[] # 存放每一个子进程执行func函数的返回值 for i in range(20): # 假设需要调度的任务有20个 ret=p.apply_async(func,args=(i,)) # 拿到的就是子进程执行func()函数的返回值 return ("返回值:",i) # print(ret.get()) # 拿到的返回值,需要使用 get()方法才可以取到,这里不可以这样直接打印; # 因为打印的话说明该进程必须得去执行func()函数才可以拿到返回值,所以必须得一个进程执行完毕,才可以去开下一个进程,这样就又变为同步了 # 就跟使用Process开多个进程,但是想在所有子进程执行完毕之后再执行主进程中的代码(比如统计所有子进程执行时间),就可以P.append(p),然后最后再同一[p.join() for p in P]实现高并发,异步编程的效果 ret_lst.append(ret) p.close() # 不允许再向主进程添加任务 p.join() [print(ret.get()) for ret in ret_lst] # 把子进程执行func()函数得到的返回值(存在列表ret_lst中的)最后统一取到
运行结果: