一.模型选择
常见的模型:分类模型, 回归模型, 聚类模型, 强化学习 等.

模型评估:损失函数小的模型是好的模型
损失函数:
我们在进行机器学习任务时,使用的每一个算法都有一个目标函数,算法便是对这个目标函数进行优化,特别是在分类或者回归任务中,便是使用损失函数(Loss Function)作为其目标函数,又称为代价函数(Cost Function)。损失函数是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
$Jleft ( mathbf{w} ight )=sum_{i}Lleft ( m_ileft (mathbf{ w} ight ) ight )+lambda Rleft ( mathbf{w} ight )$
其中,$Lleft ( m_ileft (mathbf{ w} ight ) ight )$为损失项,$Rleft ( mathbf{w} ight )$.$m_i$的具体形式如下:
$m_i=y^{left ( i ight )}f_mathbf{w}left ( mathbf{x}^{left ( i ight )} ight )$
$y^{left ( i ight )}in left { -1,;1 ight }$
$f_mathbf{w}left ( mathbf{x}^{left ( i ight )} ight )=mathbf{w}^Tmathbf{x}^{(i)}$
常见的损失函数:
1.log对数损失函数(逻辑回归)
$L(Y,P(Y|X)) = -log P(Y|X)$
2.平方损失函数(最小二乘法)
$L(Y, f(X)) = (Y - f(X))^2$
3.指数损失函数(Adaboost)
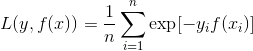
4.Hinge损失函数(SVM:合页损失)
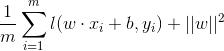
5.0-1损失函数
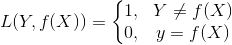
6.绝对值损失函数
![]()
模型选择时不仅要考虑对已知数据的预测能力,而且要考虑对位置数据的预测能力,减小模型的过拟合,这是模型的泛化能力
1.正则化
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或罚项(penalty term)。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数。
正则化的一般形式是在整个平均损失函数后增加一个正则项


上图所示拟合函数形式:
$y(x, extbf{w})=w_0+w_1x+w_2x^2+ldots+w_Mx^M=sum^M_{j=0}w_jx^j$
我们发现,常数(M=0)和一阶多项式曲线(M=1)的拟合效果(红)不是很好,它们与正弦曲线(绿)形状相差较大。相比而言,三阶多项式曲线(M=3)拟合效果不错,不仅大体上符合数据的走向,而且也和正弦曲线较为吻合。不过,这并不意味着阶数越高,拟合效果越好,例如,九阶多项式曲线(M=9)虽然穿过了所有的数据散点,拟合了全部数据,然而却是陡上陡下的跳跃式曲线,从中压根看不到正弦曲线的影子。这种模型是不能够做预测的,我们称最后这种情形为过拟合(over fitting)。
过拟合的突出表现是回归系数估计变得非常离谱。如下表,我们发现,随着多项式阶数越来越高,回归系数估计的绝对值变得越来越大。尤其是对于九阶多项式曲线,回归系数取的都是一些绝对值巨大的正数或者负数,结果是,虽然拟合了全部的数据,但是曲线形状也变得不成样子。究其原因,当多项式阶数越来越高时,它不仅仅去适应数据的模式,它甚至也适应了噪声。
为了避免过拟合现象的产生,我们需要根据样本容量的大小确定模型中参数的个数?从上例中,答案似乎是肯定的,然而当我们考虑模型的复杂度(参数的多少)时,应该依据问题本身的复杂度,而不能依据样本容量。事实上,在上例中,阶数越高,对正弦曲线的近似也越准确,这也就意味着阶数越高模型越接近于真实模型(正弦曲线)。一个接近于真实模型的模型最后的结却是实过拟合,这匪夷所思。究其根源,过拟合现象不能归罪于参数数量的多少和样本容量的大小,过拟合是由极大似然估计的内在的弊端造成的。
正则化符合奥卡姆剃刀(Occam's razor)原理。奥卡姆剃刀原理应用于模型选择时变为以下想法:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
L1正则化:对预测影响较小的特征,特征系数为0。
L2正则化:特征全部保留,但特征系数进行最小优化。
2.交叉验证
这种方法的基本思想是把数据分割成训练集和验证集,训练集用来拟合模型,验证集用来检验预测效果,这种方法可以选择出拟合效果较好、预测效果也较优的模型。
常见的交叉验证:
1.简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
2.留一交叉验证(Leave-one-out Cross Validation),它是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,我一般采用留一交叉验证。
3.K折交叉验证(K-Fold Cross Validation)。和第一种方法不同,S折交叉验证会把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
K折交叉验证(k-fold cross-validation)的基本步骤如下:
- 获取原始数据集合
- 将原始数据集合平均分成K份,标记为:1,2,3...K
- 第1轮:取第1到第K-1份数据作为训练数据对模型进行训练,取第K份数据作为测试集测试模型,获取准确率A-1
- 第2轮:取第1到第K-2和第K作为训练数据对模型进行训练,取第K-1份作为测试数据测试模型,获取准确率A-2
- 第3轮:取第1到第K-3和第K-1到第K份作为训练数据多模型进行训练,取第K-2份作为测试数据测试模型,获取准确率A-3
- ...依次类推
- 第K轮:取第2到K份作为训练数据进行训练,取第1份作为测试数据测试模型,获取准确率A-k
- 得出最后的模型,模型的准确率就是这K轮的平均值
例如:10折交叉验证

二.模型参数
1.含义
2.选择
GridSearchCV实现了fit,predict,predict_proba等方法,并通过交叉验证对参数空间进行求解,寻找最佳的参数。
from sklearn import svm, datasets from sklearn.model_selection import GridSearchCV iris = datasets.load_iris() parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]} svr = svm.SVC() clf = GridSearchCV(svr, parameters) clf.fit(iris.data, iris.target) GridSearchCV(cv=None, error_score=..., estimator=SVC(C=1.0, cache_size=..., class_weight=..., coef0=..., decision_function_shape=None, degree=..., gamma=..., kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=..., verbose=False), fit_params={}, iid=..., n_jobs=1, param_grid=..., pre_dispatch=..., refit=..., return_train_score=..., scoring=..., verbose=...) sorted(clf.cv_results_.keys()) ... ['mean_fit_time', 'mean_score_time', 'mean_test_score',... 'mean_train_score', 'param_C', 'param_kernel', 'params',... 'rank_test_score', 'split0_test_score',... 'split0_train_score', 'split1_test_score', 'split1_train_score',... 'split2_test_score', 'split2_train_score',... 'std_fit_time', 'std_score_time', 'std_test_score', 'std_train_score'...]
三.模型优化
1.模型状态

a.欠拟合(underfitting),高偏差(high bias)
b.过拟合(overfitting),高方差(high variance)
验证工具:学习曲线

上图的左上角子图中模型偏差很高。它的训练集和验证集准确率都很低,很可能是欠拟合。解决欠拟合的方法就是增加模型参数,比如,构建更多的特征,减小正则项。
上图右上角子图中模型方差很高,表现就是训练集和验证集准确率相差太多。解决过拟合的方法有增大训练集或者降低模型复杂度,比如增大正则项,或者通过特征选择减少特征数。
2.状态处理
a.过拟合处理
找更多数据
增大正则化系数
减少特征个数(降维,不推荐)
b.欠拟合处理
找更多特征
减小正则化系数
3.模型高权重特征处理
a.将特征进行更细致化的工作
b.对特征进行组合
4.bad-case分析
a.分类问题
b.回归问题
5.模型融合
a.Bagging(并行)
Bagging让该学习算法训练多轮,每轮的训练集由从初始的训练集中随机取出的n个训练样本组成,某个初始训练样本在某轮训练集中可以出现多次或根本不出现,训练之后可得到一个预测函数序列h_1,⋯ ⋯h_n ,最终的预测函数H对分类问题采用投票方式,对回归问题采用简单平均方法对新示例进行判别。训练R个分类器f_i,分类器之间其他相同就是参数不同。其中f_i是通过从训练集合中(N篇文档)随机取(取后放回)N次文档构成的训练集合训练得到的。对于新文档d,用这R个分类器去分类,得到的最多的那个类别作为d的最终类别。
Bagging算法可与其他分类,回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。
b.Boosting(串行)
Boosting算法是一种把若干个分类器整合为一个分类器的方法,如果一个问题存在弱分类器,则可以通过提升的办法得到强分类器,可以用于回归和分类问题。它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中;如果一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升.gbdt和adaboost都是提升树,