大白话
自从认清了某些现实之后,走了某些曾经不曾走过的路,失败了,在一切的利益面前,所有的努力都是白搭,本来说的挺好的,但是事实就是一切都那么苍白无力,自从走出之后,博客一次都没有写过,是一次都没有,一年了,过去的了都过去了,总归重新开始。
作为一个干了几年的码农,最近看了很多的书,编译原理、数据结构、算法导论等等。。。说真的,很多还是看不懂,是真的看不懂,大学时代的高数都交给高中数学老师了,还指望看算法,好头疼。这不,打算开始装逼了,看了几天python。
首先,说python的安装,自己用sublime text+python3.6的环境配置好了,但是又给卸载了,不是因为其他的,是太多的快捷键不舒服,不习惯,虽然曾经的网名是习惯不习惯的习惯,但是,那叫做曾经。
Fisrt
现在开始隆重介绍,全球最强IDE,Visual Studio,说真的,可能是.net写多了,微软综合征越来越多了,下载了vs2017,安装了python开发环境,必须声明我不是打广告,微软那么大的公司,需要我这种屁民打个声明广告,不是Visual Studio Code,是Visual Studio 2017,不要给我说什么空间占用率的什么玩意,用脑子想想,至少我觉得都是扯犊子,这都21世纪了,还担心硬件问题,担心硬件问题的人家上的税比我们工资高,所以,本屌丝从来不奢求,至少,现在还没有这个资格。目前本屌丝所在的公司就是硬件设备,所以可能觉得那帮人比较牛逼吧,作为应用服务部的一个菜鸡,只能涨涨嘴上功夫,扯远了。继续说Visual Studio 2017,下载了,都是无脑安装,至于具体的安装步骤,就不说了,说说对应的路径吧,这个不注意的话,到时候找起来比较难找。
Visual Studio 2017安装完成后,应该有三个文件夹Packages、Professional(不同的版本应该不一样,我这里是Professional版本的)、Shared,我们关注的是Shared文件夹,打开文件夹应该就一目了然了,点开python文件夹,里面有对应的内容
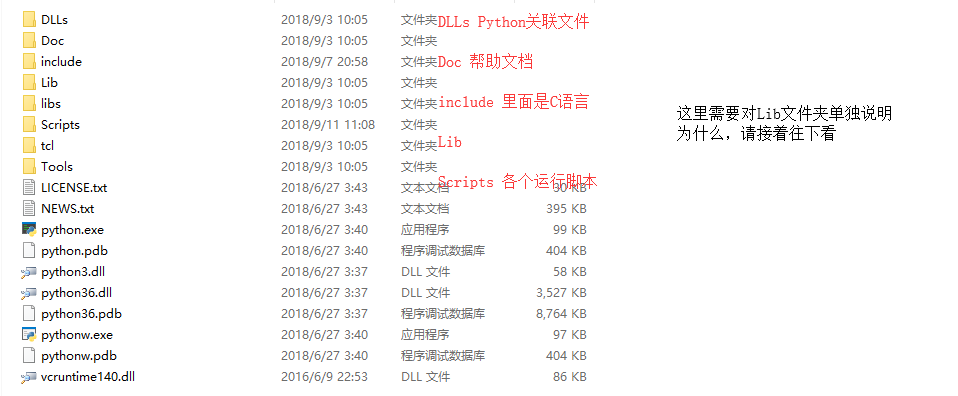
Second
大概就这样的,可能有些大佬都会说,裤子都脱了,你们给我说这个,那好,我们说Hello Word。这个总是很屌的吧。双击上图中的python.exe。然后输入 print('Hello Word'),这里必须要提醒一下诸位,请自己查看前面的python版本,如果是2.x版本的,那么这里是python 'Hello Word',不是这种括号形式的。既然说到了,那么,就说第一个问题,本文中提到的全部都是基于python3.x的,如果我想起来很python2中的冲突,可能会提醒,如果过了,那就过了吧,我也没办法,反正你又不咬我。

Third
3.1 Create Project
新建项目,随便一个,总会吧,反正我们又不是生产上线,只是尝试,对不。算了,我还是截个图吧,当年我小白入门的时候,不知道选择什么项目,可给我愁死了。
3.2 Create Class
添加一个Python类,叫做Main吧,不知道为什么,反正都已经习惯了,这就叫做习惯不习惯的习惯。

千万不要着急,这个时候是启动不了的,为什么呢。。那个牛逼的,来来,你告诉我,我保证不打死你,虽然我够不到你。你设置为启动文件了么,是的,你没听错,不是他舅舅他大爷,就是没有设置为启动文件。因为python运行的时候也是按照文件走的,可以用A.py调用B.py。但是总得让IDE知道用的是A吧,如果这个也不需要的话,那么我估计AI已经是牛逼Plus的那种的,要我们还能干吗?给你发工资还没AI干的好,对不。来来,写上我们刚才的Hello Word,这里又必须要注意了,为什么呢,Main呀,这个问题很屌的,如果不注意,是不是又觉得的我坑了你,举个栗子,Net你没有Main函数能运行么?好了,虽然代码很少,但是还是上一下吧。
if __name__ == '__main__':
print("Hello Word");
用的是全球最强IDE,你还需要其他的东西,No,No at all,F5轻轻的按下去,正如你轻轻的来。简直完美么,Python程序运行,屌不屌。
3.3 Get Web Content
来来,都说Python写爬虫厉害,我们试试怎么个厉害法。首先给个网址 http://www.xiaohuar.com/v/(此处不能加粗,我们要尊重技术) 是的,老铁,你没看错,你们都懂得,如果需要此基础上升级的,请拿出你们的诚意,假设这个算做三级,那么我可以给你五级的网址哦,too young too simple对不。说说怎么爬取这里的内容吧。
来来,改点代码。很简单的,这时候就用到包了,怎么导入包呢,很简单,import 比如需要爬这个网页的信息,那么有多简单呢,请看如下代码。
import urllib
from urllib.request import urlopen
if __name__ == '__main__':
data = urllib.request.urlopen("http://www.baidu.com/").read();
print(data);
print("Hello Word");
诸位请看自己的屏幕就晓得了,是不是,多么屌,这里,需要说明一下import和 from import,借用之前大神的描述,from import : 从车里把矿泉水拿出来,给我 import : 把车给我,就是这个意思。之所以要这么干,是因为你不这么导入一下的话,运行的时候他会告诉你 AttributeError("module 'urllib' has no attribute 'request'",) 我这英语八级的水平就不给你们翻译了,毕竟是负数不是。
OK,接下来,怎么保存呢,这又是个问题。不过这个我觉得百度都可以自行解决,直接上代码多直接,对不。
import urllib
from urllib.request import urlopen
if __name__ == '__main__':
data = urllib.request.urlopen("http://www.xiaohuar.com/").read();
print(data);
with open("data.html","w") as fi:
fi.write(str(data)); #str 必须转码,因为openurl之后的是python数据类型
fi.flush();
print("Hello Word");
鸡冻不,这是我们自己的妹纸了,开森不,打开了么,吓到你了吧,乱码,啊哈哈哈哈哈哈哈哈~~~~~~~~~~~~~~~
3.4 Modify Charset
说正事,怎么才能不乱码呢,当然是编码了,这么简单的问题,那么问题来了,所有的编码格式都是一样,No,not at all,So,我们应该首先获取这个网页的编码格式,然后根据网页的编码格式才能保存我们需要的格式,对不,OK,来,小小的改造一下。这时候就必须要说明一个小玩意,这个玩意叫做pip,用sublime text的时候,运行pip环境直接安装即可,那么我们怎么搞呢,号称全球最强IDE,那不是盖的,也不是吹的,那是真的,来来
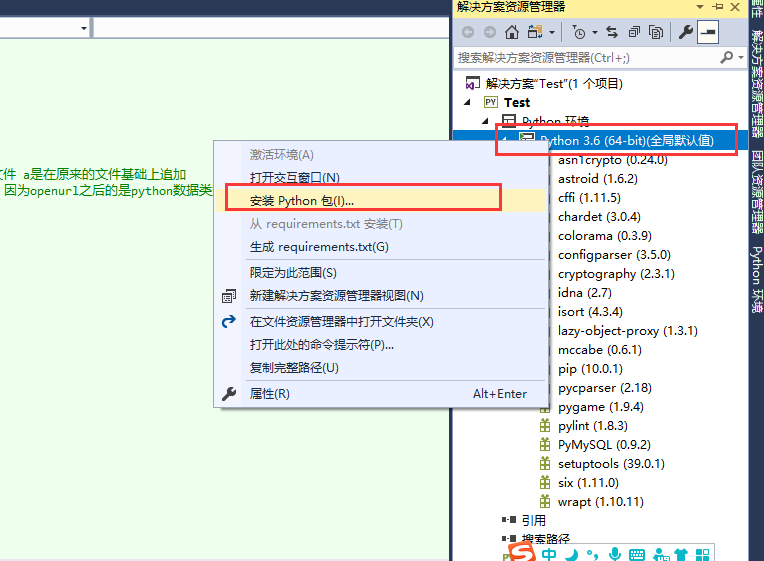
请记住,这个位置一定要则正确,是在全局默认值那个上面右击的哦,要不然打开的不对哦,是不是很吊,输入我们需要的包,既然包能解决问题,我们何必找那么多问题呢,对不,大家不都是这样,只有条件满足不了的时候才去修改自己需要的,才去重写某个函数,对不。
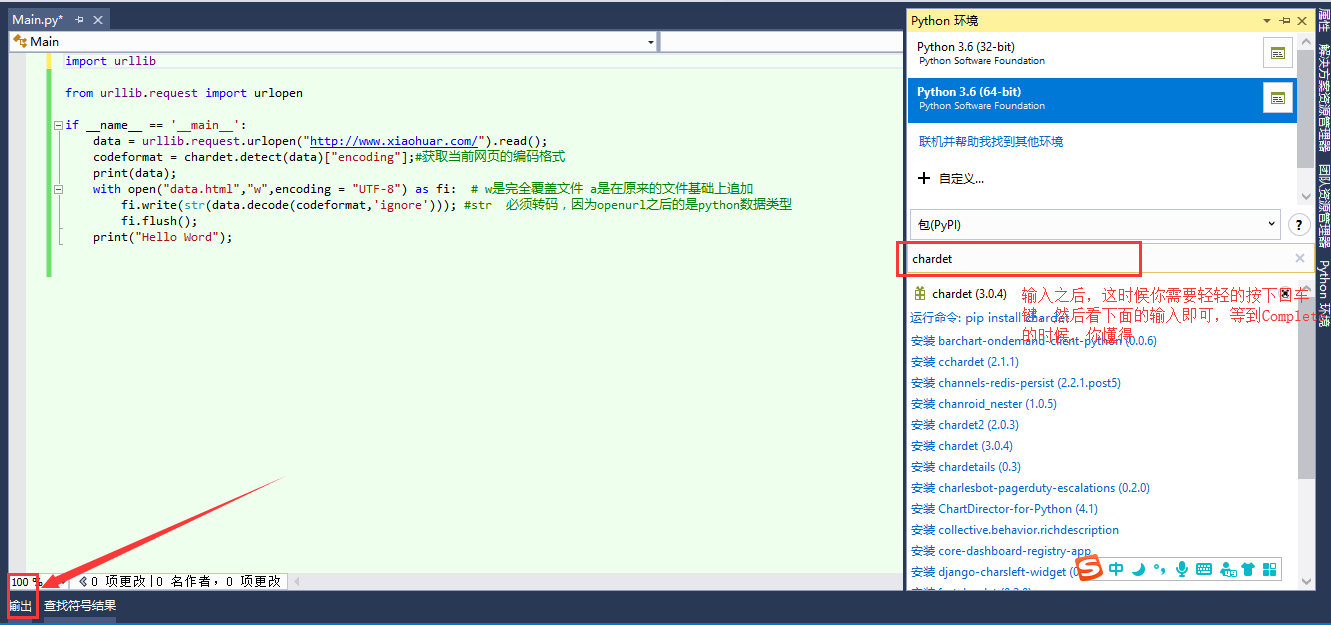
还要说么,直接import即可,是不是很鸡冻,看到代码了,直接搞上去,结果你发现,还是乱码,我草,我不是说了么,获取了网页编码格式,那么字符集一定是按照网页的编码格式输出的,你得到的用UTF-8,那不是坑爹,那你还再等什么?来来,上点完整代码。
import urllib,chardet
from urllib.request import urlopen
if __name__ == '__main__':
data = urllib.request.urlopen("http://www.xiaohuar.com/").read();
codeformat = chardet.detect(data)["encoding"]; #获取当前网页的编码格式
print(data);
with open("data.html","w",encoding = codeformat) as fi: # w是完全覆盖文件 a是在原来的文件基础上追加
fi.write(str(data.decode(codeformat,'ignore'))); #str 必须转码,因为openurl之后的是python数据类型
fi.flush();
print("Hello Word");
这里必须说明一下,python是严格按照缩进来的,我后面加的分号,那都是扯淡,那就压根没用,只是习惯了,难道你们没发现我有点的代码有分号,有的没分号么,好心么,是不是,OK回到之前的问题,是不是想问我,pip install 之后的包去了哪里。比如chardet这个包在哪里。还记得文章开头么,都说猜到了开头,没用猜到结尾,但是本屌丝告诉你,开头也没想到吧,开森不,来说说我们爬下来的东西再那里,比如我们起名字的data.html去了哪里呢?这个我觉得大家可以想到的,当然是根目录了,之前文章中提到了,python运行是文件形式的,那么,我们目前的Main.py文件在哪里,很明显,对应的data.html文件就在哪里了呗,对不。卧槽,又扯远了。说正题,我们的pip install之后的包,就是我们右键直接安装的包在哪里,来来,打开安装目录,还记得那个Shard文件夹不,打开里面不是有Python么。然后还有个Lib么,对,是Lib,不是Libs里面有一个叫做site-packages的文件夹,是不是很机智,想看源码,很OK呀,去看吧,各种各种的.py文件,是不是。
尾记
今天就到这里吧,还记得文章中的各种伏笔么,我不能再提醒了,如果想要更高级别的,可以私聊我,你懂得。欢迎各位大神唠叨。如有巧合,真的不是纯属雷同,必经代码这玩意,对不,如果意犹未尽,请听下回分解。