

1 import pandas as pd
2 import numpy as np
3 data1 = pd.DataFrame(np.arange(12).reshape((3, 4)))
4 data2 = pd.DataFrame(np.random.randn(1, 2))
5 data3 = pd.DataFrame(np.random.randn(2, 3))
6 data4 = pd.DataFrame(np.random.randn(3, 4))
--该代码是后续内容所使用到的数据。
使用Pandas数据库对Excel文件进行写入并保存--新增多个sheet时覆盖原excel表中保存的sheet数据与不覆盖原excel表中保存的sheet数据的情况
# 1.使用 文件.to_excel ---覆盖原数据,只保留最后一个to_excel的sheet
"""
df1 = ....
df2 = ....
df1.to_excel('文件名',sheet_name='1',...)
df2.to_excel('文件名',sheet_name='2',..)
执行结果:只有df2信息,出现'2'sheet, to_excel只保存最后一个数据,原文件数据全部消失并被替代
"""
file_excel = r'C:UsersAdministratorDesktop est.xls'
data1.to_excel(file_excel, sheet_name='sheet_data1')
data2.to_excel(file_excel, sheet_name='sheet_data2') # test.xls表中只有data2的sheet_data2内容

# ps:从指定单元格开始写入
data = pd.DataFrame({'One': [1, 2, 3]})
data.to_excel(file_excel, sheet_name='123', startrow=10, startcol=2, index=False) # 从123sheet的11行3列单元格开始写入
# 2.使用pd.ExcelWriter('文件名') 及 文件.to_excel ---覆盖原数据,同时执行多个to_excel时才保存多个sheet,结束后再执行一个数据的to_excel只剩该数据的sheet
"""
writer = pd.ExcelWriter('文件')
df1 = ....
df2 = ....
df1.to_excel(writer,sheet_name='1')
df2.to_excel(writer,sheet_name='2')
writer.save()
执行结果:df1、df2的信息均有,同时出现'1'与'2'sheet,原文件数据全部消失并被替代
writer = pd.ExcelWriter('文件')
df3 = ....
df3.to_excel(writer,sheet_name='3')
writer.save()
执行结果:只有df3信息,出现'3'sheet,原文件数据全部消失并被替代
"""
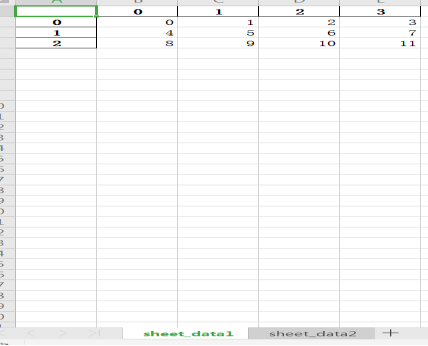
excel_writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx') # 定义writer,选择文件(文件可以不存在,相当于新建文件)
data1.to_excel(excel_writer, sheet_name='sheet_data1')
data2.to_excel(excel_writer, sheet_name='sheet_data2')
excel_writer.save() # 保存文件 ---data1和data2都在,原数据被覆盖
excel_writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx')
data3.to_excel(excel_writer, sheet_name='sheet_data3')
excel_writer.save() # 只有data3,原data1和data2被覆盖
excel_writer.close() # 关闭excel_writer

# ps:2.将不同表格中的数据写入同一个excel中的同一个sheet
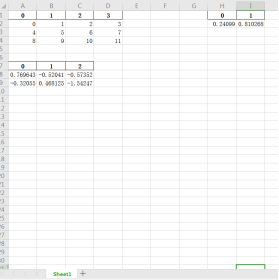
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx')
data1.to_excel(writer, index=False) # 不写sheet_name默认进excel中同一个sheet
data2.to_excel(writer, startcol=7, index=False) # 自行定义行、列开始写入的位置
data3.to_excel(writer, startrow=6, index=False)
writer.save()
# 3.使用openpyxl.load_workbook--不覆盖原数据且保存多个sheet--openpyxl打开的文件格式需为.xlsx格式
"""
from openpyxl import load_workbook # 导入模块load_workbook
writer = pd.ExcelWriter('文件')
save_book = load_workbook(writer.path)
writer.book = save_book # 将'文件'原表中的内容保存
df1 = ....
df2 = ....
df1.to_excel(writer,sheet_name='1')
df2.to_excel(writer,sheet_name='2')
writer.save()
执行结果:df1、df2的sheet信息均存在,且原文件的sheet数据都存在,没有覆盖原数据
"""
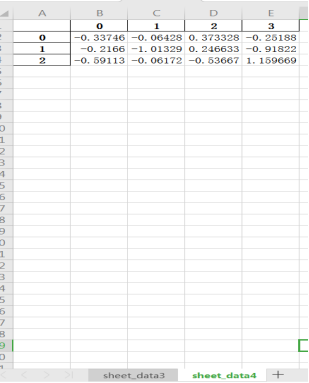
from openpyxl import load_workbook
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx')
save_book = load_workbook(writer.path)
writer.book = save_book # 将test2.xlsx原表中的内容保存
data4.to_excel(writer, sheet_name='sheet_data4') # 原表格中的数据均存在,并保存新的数据data4,若再执行一遍,新数据会被再次保存为副本sheet_data41
writer.save()
# ps:(3).只更改指定sheet中的某些数据,其他数据及sheet保持不变
# (3.1)将修改与未修改的sheet均读取出来,修改之后,再同时保存到新的excel中--若数据多、修改次数较多比较困难
import pandas as pd
read_excel = pd.ExcelFile(r'C:UsersAdministratorDesktop est2.xlsx')
df_change_1 = read_excel.parse(sheet_name='sheet_data1')
df_change_2 = read_excel.parse(sheet_name='sheet_data2')
df_change_3 = read_excel.parse(sheet_name='sheet_data3')
df_change_2.loc[0, 0] = 8
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est3.xls')
df_change_1.to_excel(writer, sheet_name='sheet_data3')
df_change_2.to_excel(writer, sheet_name='sheet_data3')
df_change_3.to_excel(writer, sheet_name='sheet_data3')
writer.save() # 更改df_change_2中的数据,并将更改后的与原sheet保存在一起
# ps: 若sheet较多,可使用循环遍历+条件语句读取与保存数据
read_excel = pd.ExcelFile(r'C:UsersAdministratorDesktop est4.xlsx')
sheet_names = read_excel.sheet_names # 读取sheet表名
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est5.xls')
j = 1
for i in sheet_names:
if j <= len(sheet_names):
dfj = read_excel.parse(i) # 读取多个sheet数据
dfj.loc[0, 0] = 8 # 更改第2个sheet数据
'.....其他要修改的内容类似'
dfj.to_excel(writer, i) # 将多个sheet数据写入到writer中
j += 1
# (3.2)直接修改指定的sheet表中某些数据,然后进行保存,其他数据及sheet内容保持不变
import openpyxl
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx')
writer_book = openpyxl.load_workbook(writer.path)
work_sheet = writer_book.worksheets[0] # 获取要修改的sheet表(这里是第一个sheet)
work_sheet.cell(1, 1, 'hello') # 将1行1列的数据改为hello
work_sheet['B2'] = 'python' # 将B2单元格改为python
writer_book.save(writer) # 将修改后的数据保存到原表中
# 与追加新的sheet到excel末尾中是不冲突的
data4 = pd.DataFrame({'name': [1, 2, 3]})
writer.book = writer_book # 将test2.xlsx原表中的内容保存
data4.to_excel(writer, sheet_name='dfhdwashd')
writer.save()
# ps:(4)向excel表的某一sheet中添加数据,覆盖原sheet数据,但不改变其他的sheet内容(即:指定sheet中用新数据替代原数据,其他sheet数据保持不变)
writer = pd.ExcelWriter(r'C:UsersAdministratorDesktop est2.xlsx')
writer_book = openpyxl.load_workbook(writer.path)
writer.book = writer_book
idx = writer_book.sheetnames.index('sheet_data2') # 找到sheet_data2的索引
writer_book.remove(writer_book.worksheets[idx]) # 删除sheet_data2工作表中的原数据
writer_book.create_sheet('sheet_data2', idx) # 重新创建空白的sheet_data2工作表
writer.sheets = dict((i.title, i) for i in writer_book.worksheets) # 保存其他用不到的sheet页面
data = pd.DataFrame({'name': [1, 2, 3]})
data.to_excel(writer, 'sheet_data2') # 将新数据data写入sheet_data2工作表中
print(writer.sheets)
writer.save()