linux shell中统计文本中指定单词出现的次数
1、测试数据, 统计 a.txt中e出现的总次数
root@PC1:/home/test/test# cat a.txt e r e y e u e e e g e 3 h r 1 3 e g e y e e s e e e e e
2、awk实现
root@PC1:/home/test/test# cat a.txt e r e y e u e e e g e 3 h r 1 3 e g e y e e s e e e e e root@PC1:/home/test/test# awk -v RS="@##@#" '{print gsub(/e/, "&")}' a.txt ## RS 指定行分割符,意思是把文本当做一行,然后统计一行中所有e的数目 16
3、grep实现
root@PC1:/home/test/test# cat a.txt e r e y e u e e e g e 3 h r 1 3 e g e y e e s e e e e e root@PC1:/home/test/test# grep -o "e" a.txt e e e e e e e e e e e e e e e e root@PC1:/home/test/test# grep -o "e" a.txt | wc -l ## grep -o列出所有匹配的字符,匹配一次占用一行,最后统计行数即可 16
4、sed实现
root@PC1:/home/test/test# cat a.txt e r e y e u e e e g e 3 h r 1 3 e g e y e e s e e e e e root@PC1:/home/test/test# sed 's/ /\n/g' a.txt ## 将所有空格替换为换行符 e r e y e u e e e g e 3 h r 1 3 e g e y e e s e e e e e root@PC1:/home/test/test# sed 's/ /\n/g' a.txt | sed -n '/e/p' ## 利用sed 打印 匹配e的行 e e e e e e e e e e e e e e e e root@PC1:/home/test/test# sed 's/ /\n/g' a.txt | sed -n '/e/p' | sed -n "$=" ## 最后统计行数即可 16
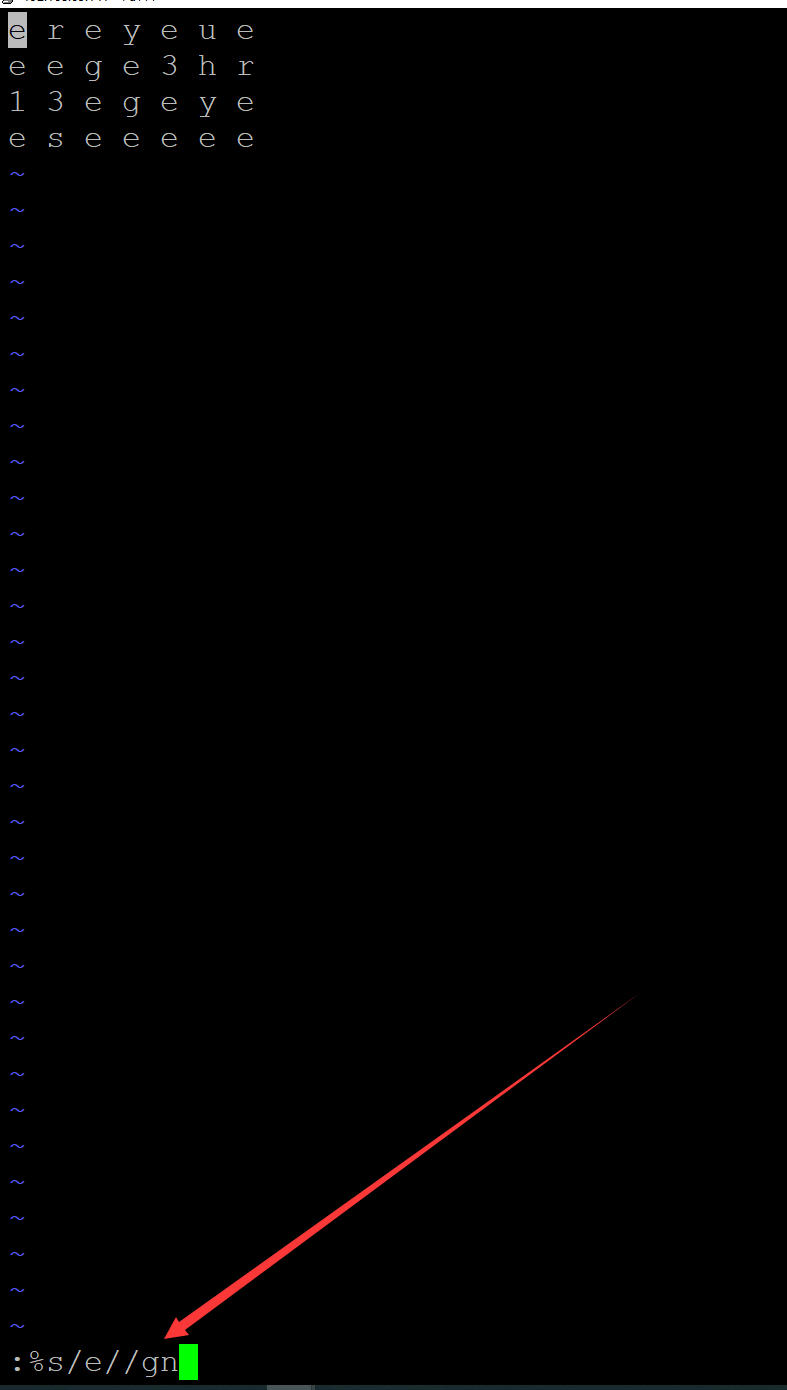
5、vim实现
root@PC1:/home/test/test# vim a.txt
e r e y e u e
e e g e 3 h r
1 3 e g e y e
e s e e e e e
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
~
:%s/e//gn