在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析
更加深入的了解网络爬虫的本质与内涵
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99 (正式版本) (32 位)
网页分析工具:开发者工具
2、网页分析
(1)网页源代码分析
我们知道,网页有静态网页和动态网页之分,很多人会误认为静态网页就是没有动态效果的网页,其实这种说法是不对的
-
静态网页 是指没有后台数据库的不可交互网页 ,常以
.htm、.html、.xml为后缀 -
动态网页 是指能与后台数据库进行数据传递的可交互网页,常以
.aspx、.asp、.jsp、.php为后缀
另外,目前很多动态网站都采取了 异步加载技术 (Ajax),这就是很多时候抓取到的源代码和网站显示的源代码不一致的原因
至于如何爬取动态网页,这里提供两种方法:
-
一是下面即将讲到的通过抓包分析 Ajax 请求
-
二是利用 Selenium 等工具进行动态渲染,这个可以参考我的另一篇文章 —— selenium的基本使用
下面我们以京东商品为例,分析如何通过 Chrome 进行抓包,我们首先打开某个商品的首页
https://item.jd.com/10072615543.html
来到网页空白处单击鼠标右键,选择 查看网页源代码(或者使用快捷键 Ctrl+U 直接打开)
请注意,查看网页源代码 得到的是网站最原始的源代码,也就是通常我们抓取到的源代码
再次来到网页空白处单击鼠标右键,选择 检查(或者使用快捷键 Ctrl+Shift+I / F12直接打开)
请注意,检查 得到的是是经过 Ajax 加载和 JavaScript 渲染的源代码,也就是当前网站显示内容的源代码
经过对比之后,我们可以发现两者的内容是不一样的,这就是 异步加载技术 (Ajax) 的典型例子
就目前来说至少京东商品的价格是通过异步加载生成的,这里提供三种方法判断网页中某个内容是否为动态生成:
-
一是分析 查看网页源代码 生成的源代码,可以在其中寻找动态请求的典型语句,也可以将其与 检查 生成的源代码进行比较
-
二是通过以下将要讲解的网页抓包分析来判断,这种方法最为常用,应当好好掌握
-
三是一种取巧的方法,就是禁用 Chrome 浏览器的 JavaScript 加载
具体可以在 Chrome 的地址栏中输入 chrome://settings/content/javascript 来到 JavaScript 的设置页面
然后将 JavaScript 的选项关闭,这时候重新刷新网页,就会看到原来显示价格的地方出现了空白
这就表明原来的价格是通过 JavaScript 动态生成的
(2)网页抓包分析
我们还是以京东商品为例进行讲解,打开某个商品的首页,尝试抓取动态加载的商品价格数据
https://item.jd.com/10072615543.html
使用快捷键 Ctrl+Shift+I 或 F12打开开发者工具,然后选择 Network 选项卡 进行抓包分析
此时按下快捷键 F5 刷新页面,可以看到开发者工具中出现了各种各样的包,我们使用 Filter 对包进行过滤
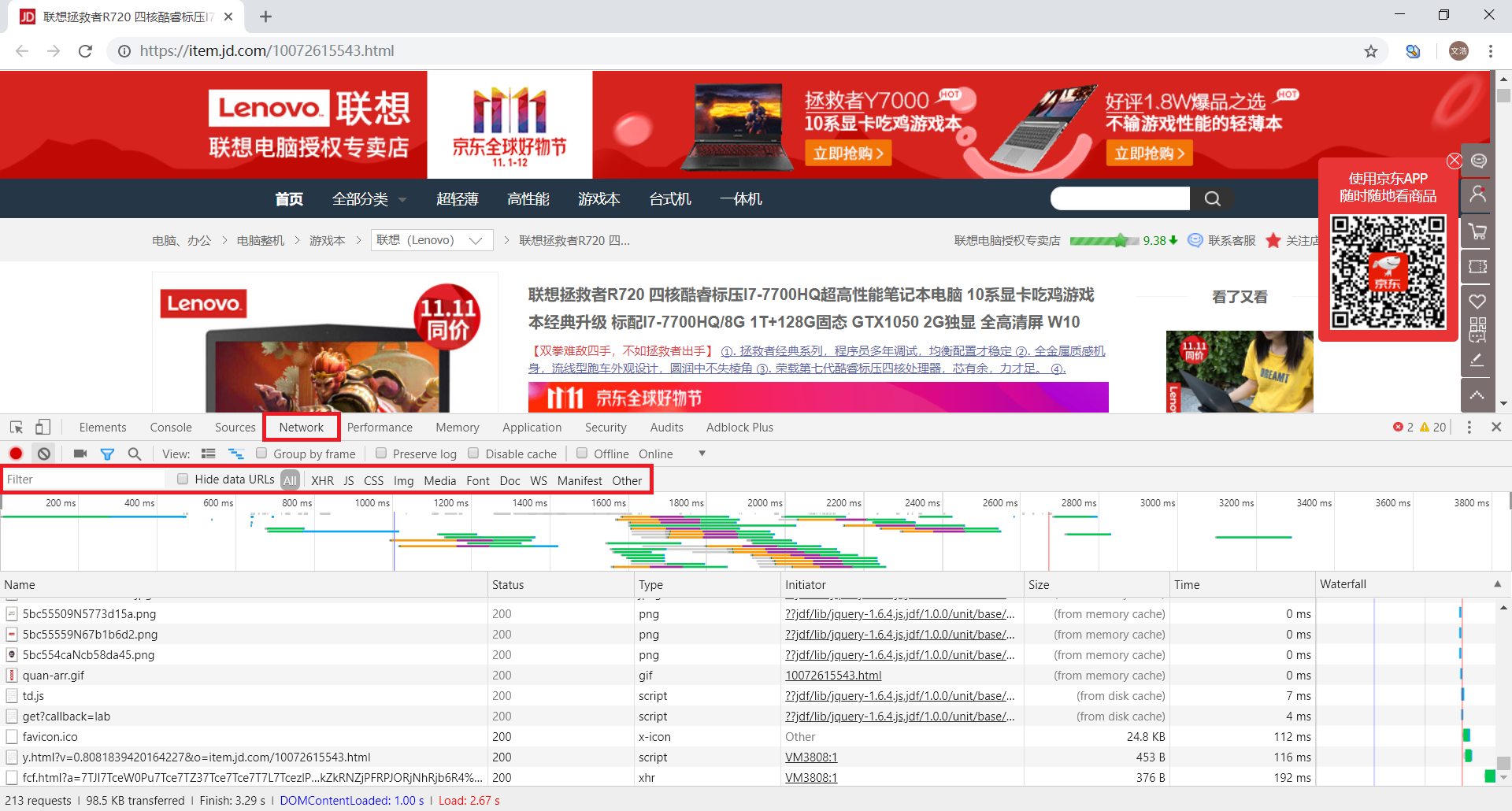
首先,我们选中 Doc,可以看到列表中只出现了一个包
一般来说,这个就是浏览器接收到的第一个包,用于获取请求网站的原始源代码
点击 Header 可以看到它的头部参数设置
点击 Response 可以看到返回的源代码,容易发现,它其实和 查看网页源代码 返回的信息是一致的
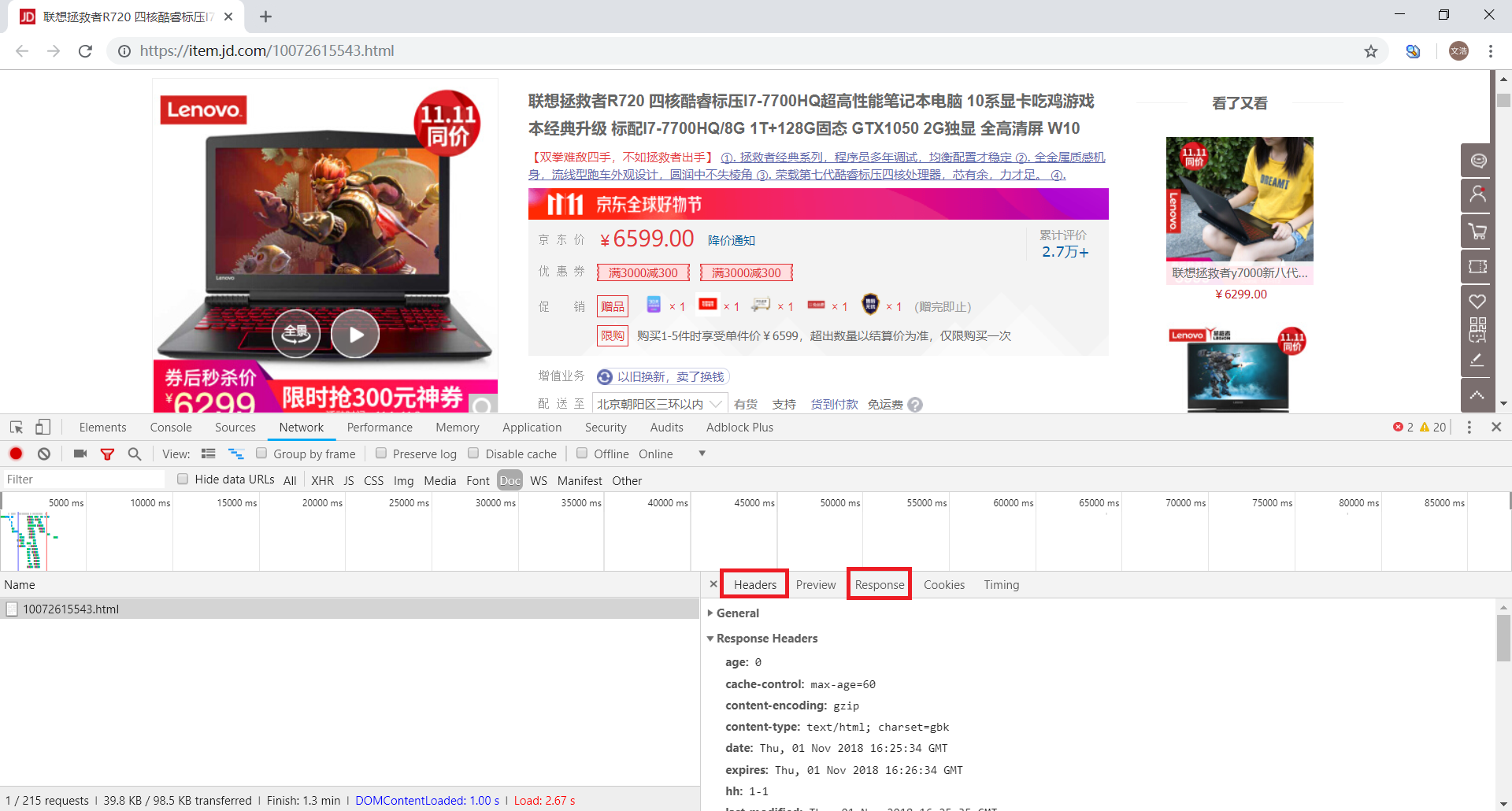
下面让我们重新回到正题,对于动态加载的抓包分析,主要看 XHR 和 JS 选项卡即可
选中 JS 进行过滤,发现列表中出现了好多包,经过分析,我们筛选出下图中加标记的包
这个包返回的是关于价格的信息,可是经过仔细分析发现,这些价格并不是属于当前商品的,而是属于相关商品的
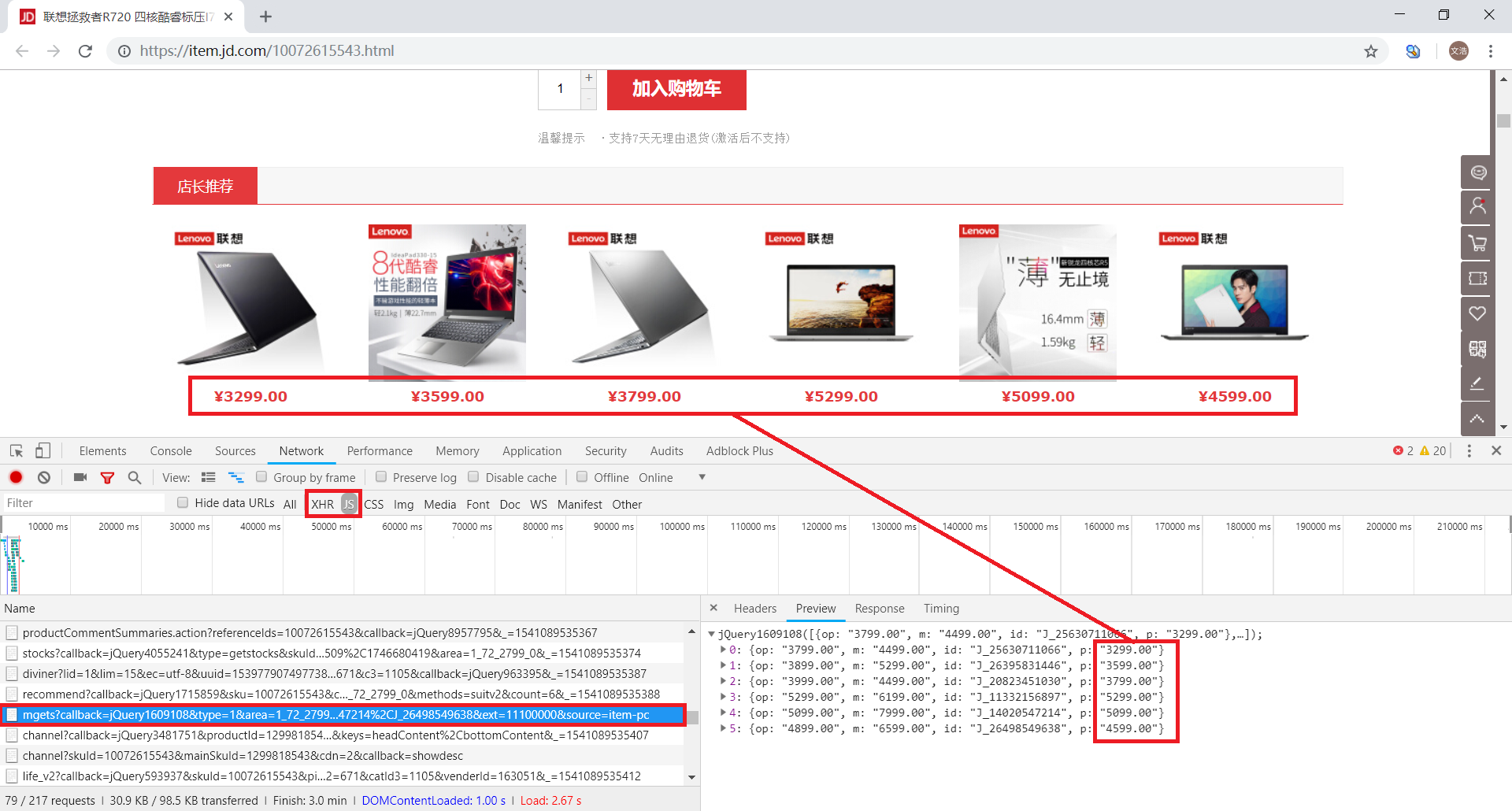
但是怎么说这个包还是和价格相关的,我们还是先看看这个包的请求 URL 吧
https://p.3.cn/prices/mgets?callback=jQuery1609108&type=1&area=1_72_2799_0&pdtk=&pduid=1539779074977382417990&pdpin=&pin=null&pdbp=0&skuIds=J_25630711066%2CJ_26395831446%2CJ_20823451030%2CJ_11332156897%2CJ_14020547214%2CJ_26498549638&ext=11100000&source=item-pc
对包括 callback 等不必要的参数进行筛选,可以得到简单而有效的 URL
https://p.3.cn/prices/mgets?skuIds=J_25630711066%2CJ_26395831446%2CJ_20823451030%2CJ_11332156897%2CJ_14020547214%2CJ_26498549638
直接用浏览器打开该 URL,可以看到返回的的确是包含价格信息的 JSON 数据(只可惜是其他商品的价格)

分析该 URL 的参数,可以推测 skuId 应该就是每一个商品独一无二的标志了,那么我们所需要的商品的 skuId 究竟可以在哪里找到呢?
事实上,SKU 是一个在物流、运输等产业中常用的缩写,其全称是 Stock Keeping Unit(库存量单位)
即库存进出计量的基本单元,现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的 SKU
回顾我们刚开始进入的商品首页,https://item.jd.com/10072615543.html
这其中不是就隐藏着当前商品的唯一号码标识(10072615543)了吗?不妨一试!
果然,访问商品价格的完整 URL 我们就可以得到了,https://p.3.cn/prices/mgets?skuIds=10072615543
通过直接访问该网址我们就可以得到当前商品的价格信息

事实上,我们还可以对该 URL 进行适当的泛化以适应京东所有商品的价格爬取
很简单,只需要将 skuIds 作为参数独立分离出来即可,https://p.3.cn/prices/mgets?skuIds={ID}
通过泛化后的 URL ,理论上只要能得到商品的 skuId,我们就可以访问对应商品的价格
【爬虫系列相关文章】