关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践。
作为硬件数码控,我选择了经常光顾的中关村在线的手机页面进行爬取,大体思路如下图所示。
1 # coding:utf-8
2 import scrapy
3 import re
4 import os
5 import sqlite3
6 from myspider.items import SpiderItem
7
8
9 class ZolSpider(scrapy.Spider):
10 name = "zol"
11 # allowed_domains = ["http://detail.zol.com.cn/"] # 用于限定爬取的服务器域名
12 start_urls = [
13 # 主要爬去中关村在线的手机信息页面,考虑到是演示目的就仅仅爬了首页,其实爬分页跟二级爬虫原理相同,出于节省时间目的这里就不爬了
14 # 这里可以写多个入口URL
15 "http://detail.zol.com.cn/cell_phone_index/subcate57_list_1.html"
16 ]
17 item = SpiderItem() # 没法动态创建,索性没用上,用的meta在spider函数间传值
18 # 只是test一下就用sqlite吧,比较轻量化
19 #database = sqlite3.connect(":memory:")
20 database_file = os.path.dirname(os.path.abspath(__file__)) + "\phonedata.db"
21 if os.path.exists(database_file):
22 os.remove(database_file)
23 database = sqlite3.connect(database_file)
24 # 先建个字段,方便理解字段含义就用中文了
25 database.execute(
26 '''
27 CREATE TABLE CELL_PHONES
28 (
29 手机型号 TEXT
30 );
31 '''
32 )
33 # 用于检查数据增改是否全面,与total_changes对比
34 counter = 0
35
36 # 手机报价首页爬取函数
37 def parse(self, response):
38 # 获取手机详情页链接并以其创建二级爬虫
39 hrefs = response.xpath("//h3/a")
40 for href in hrefs:
41 url = response.urljoin(href.xpath("@href")[0].extract())
42 yield scrapy.Request(url, self.parse_detail_page)
43
44 # 手机详情页爬取函数
45 def parse_detail_page(self, response):
46 # 通过xpath获取手机型号
47 model = response.xpath("//h1").xpath("text()")[0].extract()
48 # 创建该型号手机的数据库记录
49 sql = 'INSERT INTO CELL_PHONES (手机型号) VALUES ("' + model + '")'
50 self.counter += 1
51 self.database.execute(sql)
52 self.database.commit()
53 # 获取参数详情页的链接
54 url = response.urljoin(response.xpath("//div[@id='tagNav']//a[text()='参数']").xpath("@href")[0].extract())
55 # 由于Scrapy是异步驱动的(逐级启动爬虫函数),所以当需绑定父子级爬虫函数间的某些变量时,可以采用meta字典传递,全局的item字段无法动态创建,在较灵活的爬取场景中不是很适用
56 yield scrapy.Request(url, callback=self.parse_param_page, meta={'model': model})
57
58 # 手机参数详情页爬取函数
59 def parse_param_page(self, response):
60 # 获取手机参数字段并一一遍历
61 params = response.xpath("//span[contains(@class,'param-name')]")
62 for param in params:
63 legal_param_name_field = param_name = param.xpath("text()")[0].extract()
64 # 将手机参数字段转变为合法的数据库字段(非数字开头,且防止SQL逻辑污染剔除了'/'符号)
65 if re.match(r'^d', param_name):
66 legal_param_name_field = re.sub(r'^d', "f" + param_name[0], param_name)
67 if '/' in param_name:
68 legal_param_name_field = legal_param_name_field.replace('/', '')
69 # 通过查询master表检查动态添加的字段是否已经存在,若不存在则增加该字段
70 sql = "SELECT * FROM sqlite_master WHERE name='CELL_PHONES' AND SQL LIKE '%" + legal_param_name_field + "%'"
71 if self.database.execute(sql).fetchone() is None:
72 sql = "ALTER TABLE CELL_PHONES ADD " + legal_param_name_field + " TEXT"
73 self.database.execute(sql)
74 self.database.commit()
75 # 根据参数字段名的xpath定位参数值元素
76 xpath = "//span[contains(@class,'param-name') and text()='" + param_name +
77 "']/following-sibling::span[contains(@id,'newPmVal')]//text()"
78 vals = response.xpath(xpath)
79 # 由于有些字段的参数值是多个值,所以需将其附加到一起,合成一个字段,以方便存储。
80 # 如需数据细分选用like子句或支持全文索引的数据库也不错,当然nosql更好
81 pm_val = ""
82 for val in vals:
83 pm_val += val.extract()
84 re.sub(r'
|
',"",pm_val)
85 sql = "UPDATE CELL_PHONES SET %s = '%s' WHERE 手机型号 = '%s'"
86 % (legal_param_name_field, pm_val, response.meta['model'])
87 self.database.execute(sql)
88 self.counter += 1
89 # 检查下爬取的数据对不对
90 results = self.database.execute("SELECT * FROM CELL_PHONES").fetchall()
91 # 千万别忘了commit否则持久化数据库可能结果不全
92 self.database.commit()
93 print(self.database.total_changes, self.counter) # 对比下数据库的增改情况是否有丢失
94 for row in results:
95 print(row, end='
') # 其实这里有个小小的编码问题需要解决
96 # 最后愉快的用scrapy crawl zol 启动爬虫吧!
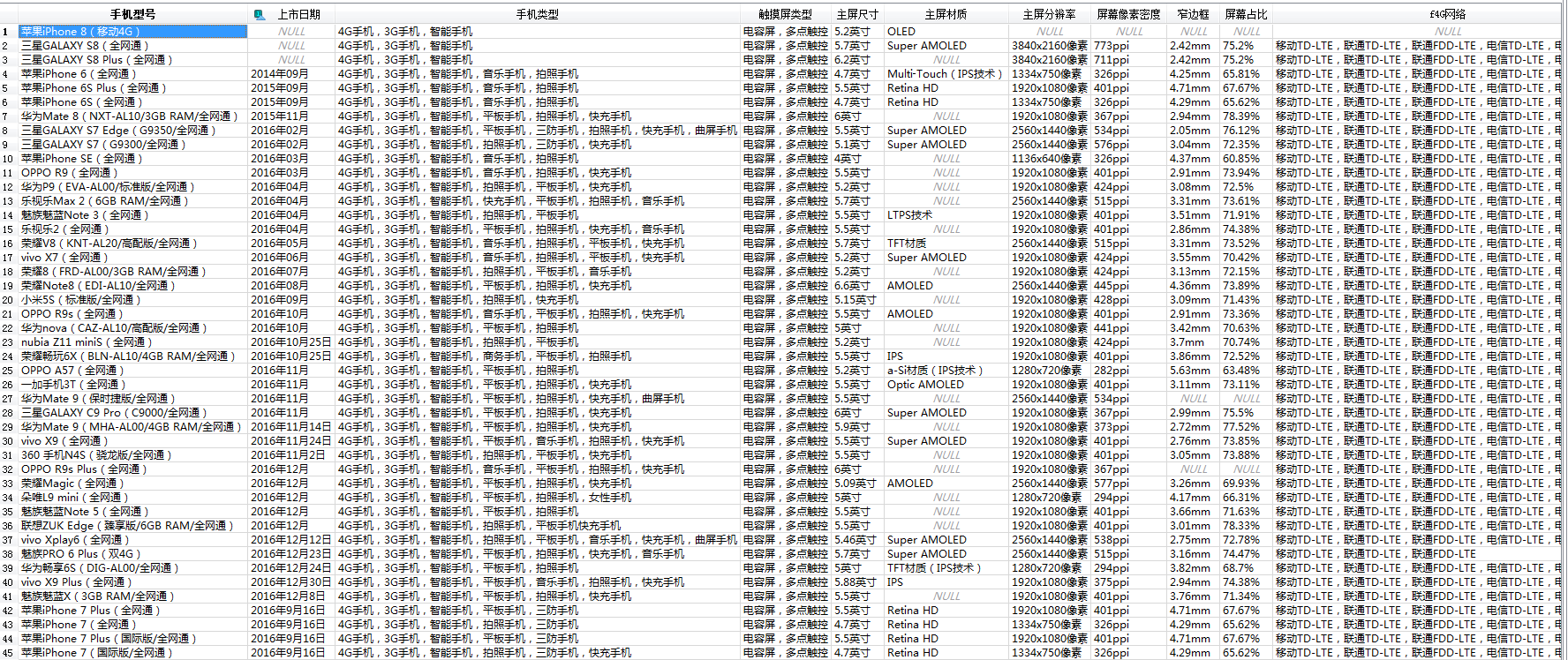
部分爬到数据库的数据
最后建议在settings脚本中修改USER_AGENT,以模拟浏览器请求,避免反爬,例如:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
当然高级点的反爬手段也有别的办法应付:
1.基于用户行为的爬取,可以增设爬取逻辑路由,以动态的爬行方式获取资源,并且频繁切换IP及UA,基于session及cookie的反爬亦可以基于此手段;
2.AJAX等异步js交互的页面,可自定义js请求,如果请求被加密了,结合selenium + webdriver来驱动浏览器,模拟用户交互异曲同工;
3.关于匹配方式,正则,XPath、CSS等等selector因人而异,前端经常调整的话不建议用CSS selector;
正则表达式从执行效率上较XPath会高一些,但是XPath可以基于元素逻辑层次、属性值条件,甚至结合XPath函数十分灵活的定位一个多个(组)元素;
总的来说做爬虫的同学,正则和XPath应该是基本功啦,特别是在定向爬取数据时尤为重要。
4.关于路由及任务调度问题,虽然Scrapy提供了非常简单的异步IO方案,能够轻松爬取多级页面,并根据base URL及灵活的自定义回调函数实现深层(有选择的)爬虫,
但对于爬取海量数据的场景,灵活性较差,因此队列管理(排重、防中断、防重跑)及分布式爬虫可能更为适用。
当然,学习Python爬虫,掌握urllib(2、3)、requests、BeautifulSoup、lxml等模块也会让你如虎添翼,还需因地制宜才是。
p.s.进来用Golang做爬虫的童鞋也多了起来,性能较之Python会好不少,可以尝试一下。会JAVA的童鞋,也可以关注下Nutch引擎。(路漫漫其修远兮啊,一起学习吧。)