本文整理自线上直播【MCtalk Live#2 :RTC 系统音频弱网对抗技术发展与实践】网易云信资深音视频引擎开发专家崔承宗分享内容,文末也可查看直播回顾视频。
1、背景介绍
RTC(Real Time Communication)系统广泛应用在视频会议、在线医疗、泛娱乐、在线教育等实时互动场景,为用户提供低延时、高清晰度和流畅度、高保真音质的实时互动体验。音频弱网对抗技术旨在提升 RTC 系统在弱网(高丢包、大抖动、高延迟)条件下的用户体验。
本文从 RTC 系统的音频弱网效果、弱网对抗的诸多技术以及 RTC 系统层面进行较为详尽的分析,希望可以帮助读者对 RTC 系统的音频弱网对抗技术有所了解。
2、常见音频弱网卡顿现象
实际场景中常见的音频弱网卡顿现象有如下表所示几次情况:
| 表1 常见 RTC 应用音频弱网卡顿现象 | |||
|---|---|---|---|
| 序号 | 现象 | 排查路径 | 问题归类 |
| 1 | 音乐声音不饱满、发闷,飘忽、卡顿 | 确认 CODEC 采样率、码率,编码器类型 | CODEC类 型选型,CODEC参数设置 |
| 2 | 声音快进、慢放 | 网络 RTT,网络数据突发数据量,设备信号强度等 | 网络抖动、去抖动处理逻辑、网络连接信号差等 |
| 3 | 声音卡顿、卡死、断续 | 网络丢包率和 RTT、网络带宽预测、码率分配、网络拥塞控制等 | 网络拥塞、网络连接差等 |
3、RTC 系统音频的抗性
针对上述音频卡顿现象,我们该如何应对呢?表2列举了业界常用的音频抗丢包算法和相互对比。
| 表2 业界常用的音频抗丢包算法对比 | |||||
|---|---|---|---|---|---|
| 对比 | 带外 FEC | Opus/SILK 带内 FEC | RED | ARQ | PLC |
| 延迟 | 分组延时+单向传输的时间 | 1或者2倍帧长+单向传输的时间 | RED 最大层数 N 倍的帧长+单向传输的时间 | N 倍 RTT 的传输延时,N 是最大重传次数 | 无延迟 |
| 使用方式 | 前向纠错 | 编码器特性 | 前向纠错 | 后验纠错 | 后验纠错 |
| 适用情况 | 随机丢包、网络 RTT 较大、包长度较大的场景 | 小丢包或者非连续丢包、编码器编码码率较高的场景 | 随机丢包、网络 RTT 较大、包长度较小的场景 | 突发丢包和持续丢包、网络 RTT 较小的场景 | 小丢包或者非连续丢包根据上下文或者临近波形生成相似波形 |
| 实现难度 | 相对复杂,涉及到发端、收端FEC编解码逻辑,动态冗余、反馈及时性等 | 相对简单,涉及编码器码率和网络丢包模型 | 复杂度低于带外 FEC,涉及到动态冗余、反馈及时性等 | 看似简单,实际上网络复杂场景下的挑战较大 | 相对复杂,通过波形相关性或者噪声填充,提升抗丢包能力 |
下面,我们详细介绍一下音频抗性的这几种算法。
抗丢包 FEC
前向纠错也叫前向纠错码(Forward Error Correction,简称 FEC),是增加数据通信可信度的方法。FEC 利用数据进行冗余信息的传输,当传输中出现数据丢失时,将允许接收端根据已经接收的数据恢复丢失数据。
如下图所示,我们可以看到,发送端将数据包根据冗余度参数进行分组 (block),对分组数据增加冗余。接收端在收齐分组后,即可恢复丢失数据(条件是丢失不超过冗余包数)。因为接收端要等待FEC分组到齐,所以存在 FEC 恢复算法上的延时, FecDelay = Block个数 * 帧长。

图1 发送端和接收端的 FEC 处理示意图
那么,常用的 FEC 冗余算法包括哪些呢?
RTC 系统中常用的 FEC 冗余算法包括:XOR、Reed Solomon、喷泉码等。其中,以 XOR 和 Reed Solomon 算法的应用较为广泛。
下面简单介绍一下 Reed Solomon 算法的数学背景。
Reed Solomon 算法的核心思想包括三个部分:
- 利用范德蒙德(Vandermonde)矩阵 F,通过数据块计算编码块(即算冗余矩阵),如图2所示

图2 利用范德蒙德(Vandermonde)矩阵计算冗余矩阵示意图
- 利用高斯消元法(Gaussian elimination) ,恢复损坏的数据块 (即算冗余矩阵的逆矩阵)
- 为了方便计算机处理,所有的运算是在伽罗华域 Galios, GF(2^w) 的基础上进行
抗丢包 RED
如前所述,RS FEC 算法由于涉及矩阵运算,在发送端和接收端都会增加额外的性能开销。考虑到音频包长度较小,采用 RED(Redundant Audio Data)方式进行冗余是一种更有优势的策略,可以提高数据包 payload 的利用率,并降低性能开销。
我们举一个实际的例子:一个 RTP 音频数据包,包括一个 DVI4(8KHz) 主编码块和一个单独的 8KHz LPC 编码的冗余块,两者长度均为 20ms。参照 RFC 2198 标准所定义,示例格式如图3所示。

图3 基于 RFC 2198 的 RED 组包示意图
抗丢包 ARQ
介绍了 FEC 和 RED 这两种前向纠错方法之后,下面我们再看一下音频 ARQ。
音频 ARQ(自动重传请求)重传使用的是 NACK 方式,如下图。
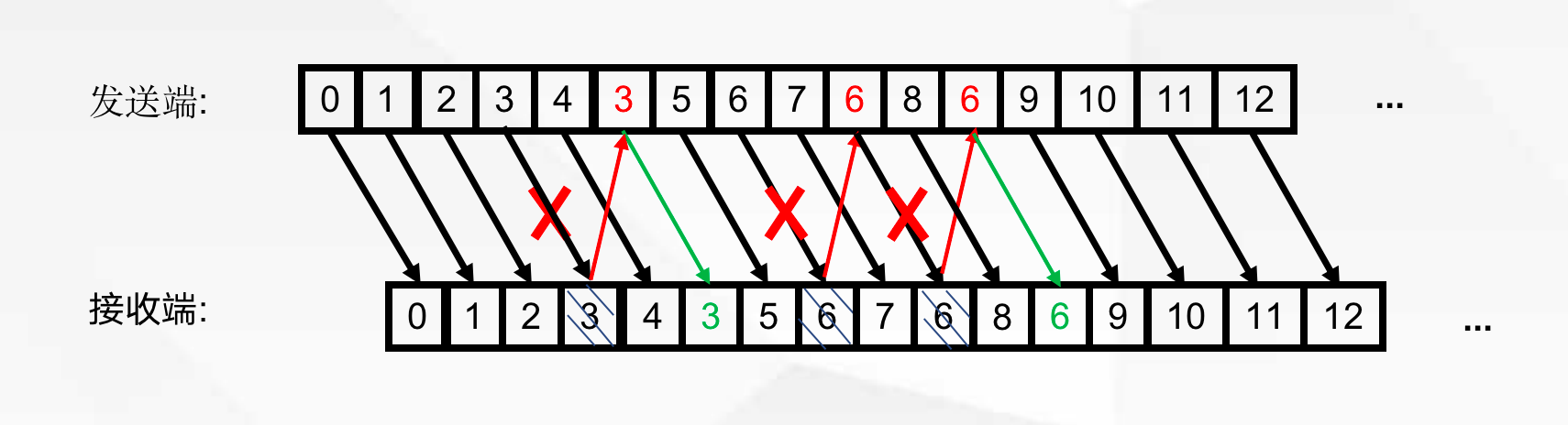
图4 发送端和接收端的 ARQ 处理示意图
假设是随机均匀丢包场景,重传失败率概率为:Pn = P(n-1)*lossrate。对于音频来说,假设当重传失败概率 Pn<1% 时,认为重传成功,那么 n 就是重传成功所需的次数(截断二进制指数退避算法)。
各种丢包率条件下需要的理论重传次数如表3所示。
| 表3 各种丢包率条件下需要的理论重传次数 | |
|---|---|
| 丢包率 | 需要重传的理论次数 |
| 10% | 1 |
| 20% | 2 |
| 30% | 3 |
| 40% | 5 |
| 50% | 6 |
| 60% | 8 |
| 70% | 10 |
| 80% | 21 |
我们可以看一下两种情况:
- 假设 10% 丢包:重传一次失败的概率 10% * 10% = 1%。
- 假设 50% 丢包:重传一次失败 50%50%=25%,2次:2550% = 12.5%,4次: 3.125%,6次:0.78%。
音频快速重传 ARQ 就是以“选择重传”算法作为基本的请求策略,其算法的关键特色在于重传请求与 JitterBuffer 的紧密配合。
- 请求重传模块记录并缓存所有重传数据包的重传成功所消耗的时间,并将重传延时 Arq Delay 告知 JitterBuffer 模块,提高了数据的缓冲等待时长的高可控性,参见(6)。
- 接收端通过 ARQ 请求,在数据缓冲队列的数据帧被播放之前,当还未重传成功的数据帧在已经达到播放时间时,接收端通过 ACK 通知取消请求重传,减少无用请求,参见(5)。
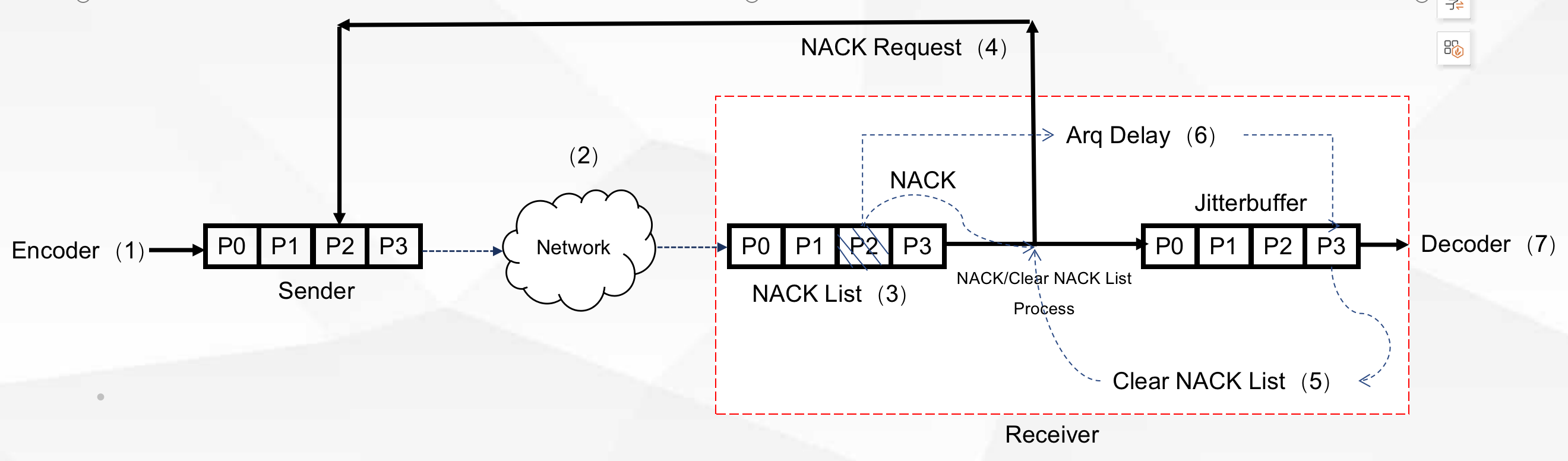
图5 发送端和接收端的 NACK 请求和重传示意图
ARQ 策略受 RTT 影响较大,由于 ARQ 的原理是针对丢包进行选择性请求和重传,所以它对于突发丢包有较好的对抗能力,冗余码率的利用率远高于 FEC 和 RED。
ARQ 策略在使用中的难点是合理把握 NACK 请求的时机和间隔以及重传包的码率控制,防止误请求、多请求和多重传,尤其在抖动场景下需要格外关注。
抗抖动
弱网环境除了丢包以外,在 4G 和 Wifi 等移动接入场景中抖动和乱序较为常见,主要原因是移动链路的多径干扰、信号衰减、临频干扰等。为了处理抖动和乱序,保证接收端数据包的有序接收,在 RTC 系统的接收端引入抗抖动模块,原理如图6所示。
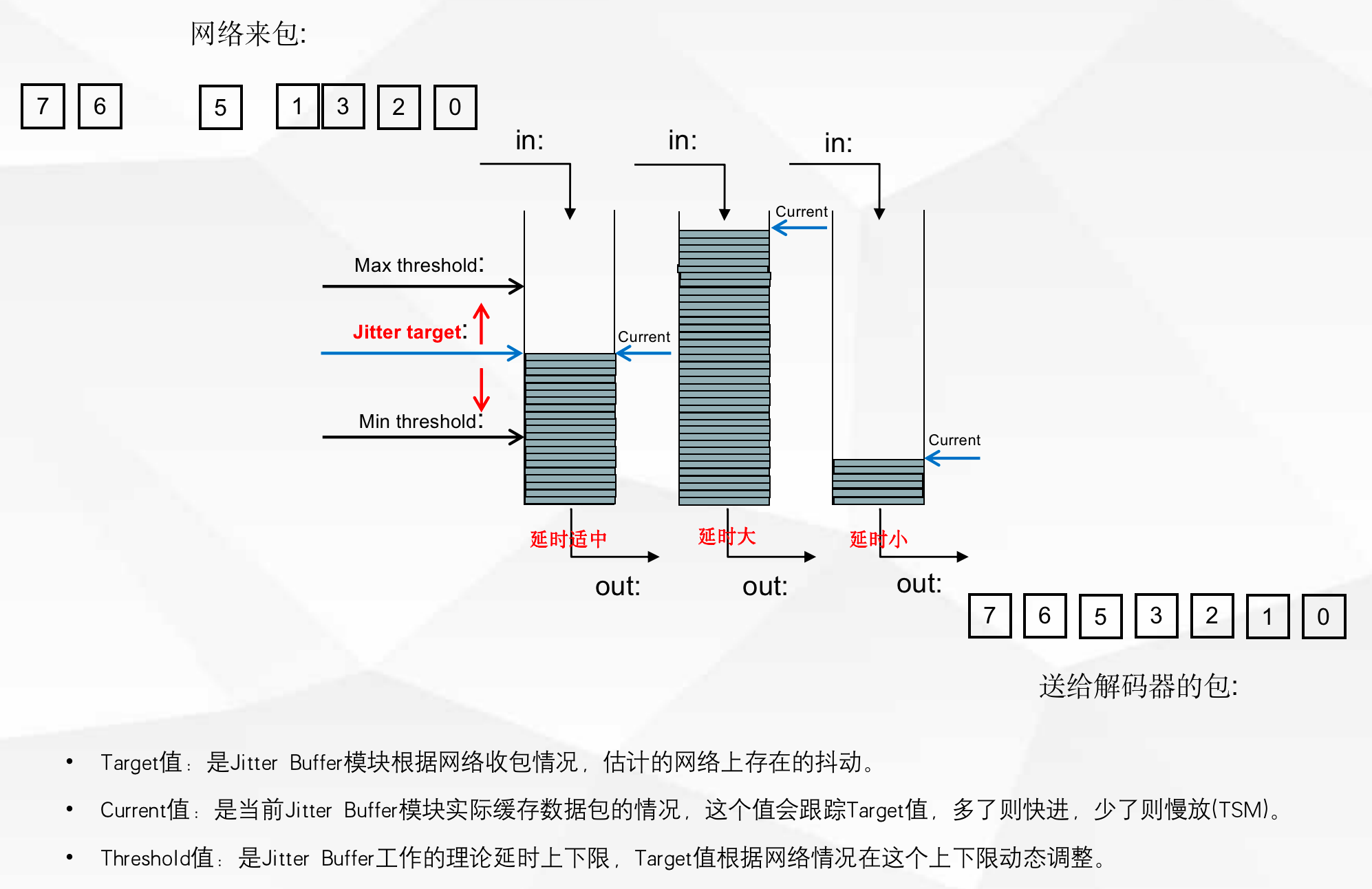
图6 RTC 系统的抗抖动模块原理示意图
抗抖动模块重要的组成部分之一是网络抖动的预测。抗抖动模块根据网络抖动的预测结果自适应调节Jitterbuffer长度,以达到抗抖动的目的,并能够在网络无抖动的时候保证低延时。抗抖动模块的抖动预测模块原理如图7和8所示。
Jitterbuffer 模块的网络延时估计是以 IAT(inter arrival time)为基础的。IAT 的含义是相邻包到达时间间隔。通话时间越长,包间隔 IAT 的概率分布越稳定。观察周期内 IAT 的整体概率分布之和近似为1。一般采用 95% 作为满足统计概率的阈值,计算出 Jitterbuffer 的目标值大小。
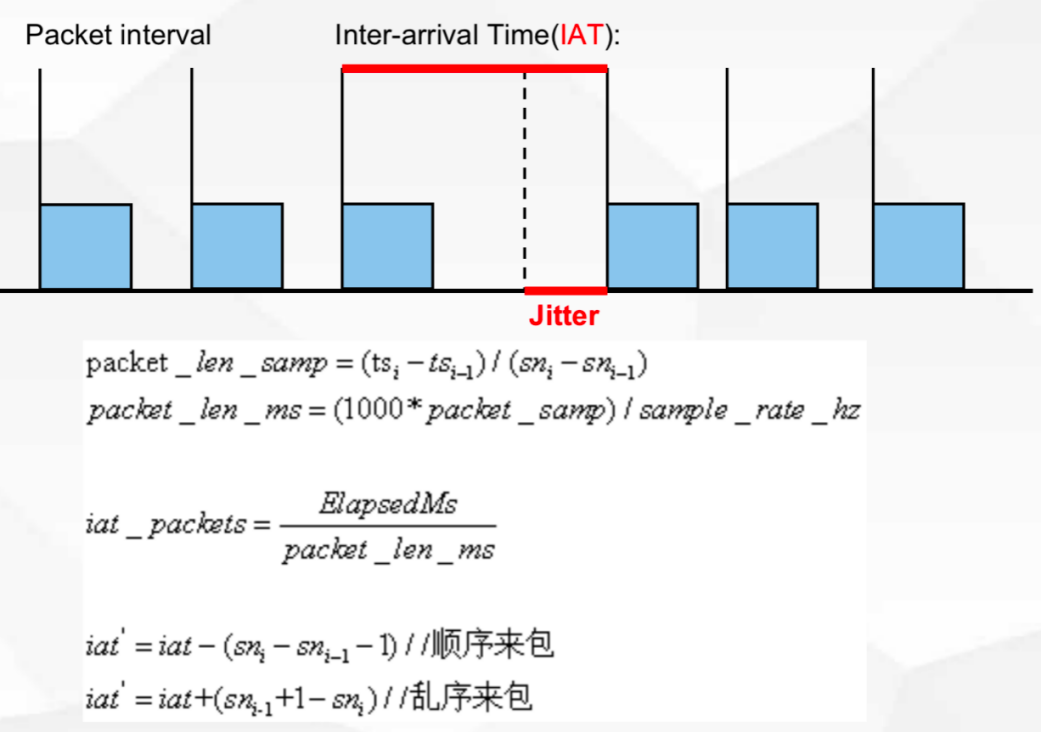
图7 抗抖动模块的抖动预测原理1
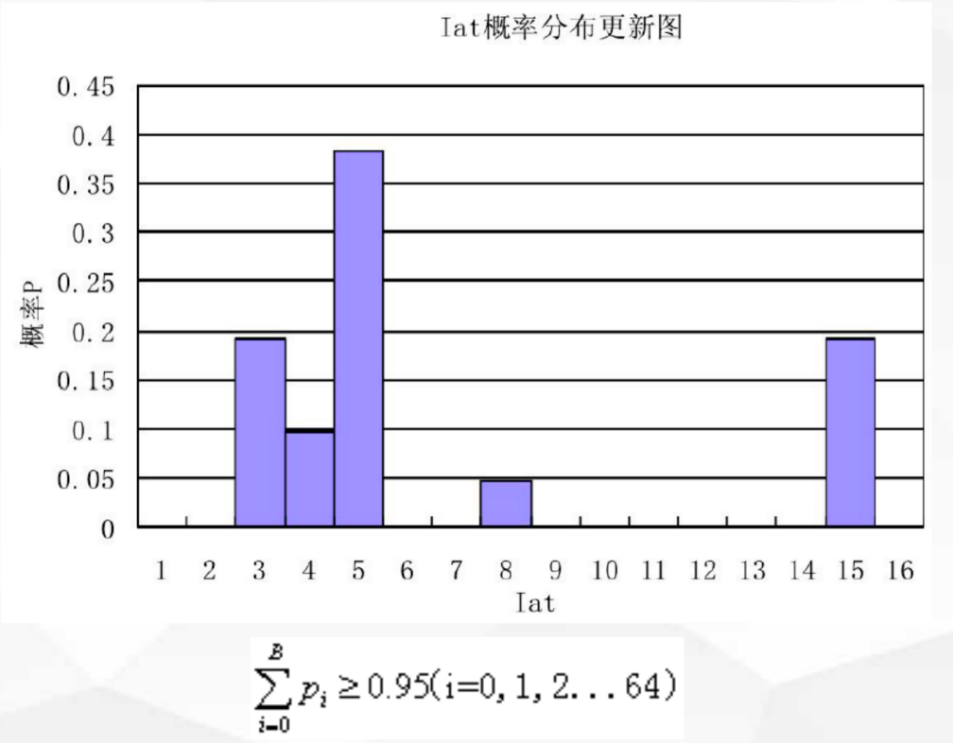
图8 抗抖动模块的抖动预测原理2
抖动预测之后,需要对 buffer 中音频数据进行调节,常用的做法是进行加减速播放。在需要拉伸 jitterbuffer 的时候进行慢放操作,在需要压缩 jitterbuffer 的时候进行快放操作。
- 语音时长修正(Time Scale Modification, TSM)是一种通过扩展或者压缩语音长度,从而改变语音速度的技术。在进行时域压缩或者扩展的同时,还应尽量保证语音信号的基音频率及音色—即变长不变调。
- Wsola(波形形似同步叠加法)是一种基于语音信号准周期特性,进而插入基因周期整数倍的信号来实现波形长度变化的算法。
4、RTC 系统音频的编解码
在介绍了 RED、ARQ 和抗抖动等弱网对抗技术之后,我们再介绍一下基于音频编解码器实现的弱网对抗技术。
如下图,说明了各种编解码器的质量与码率的关系:
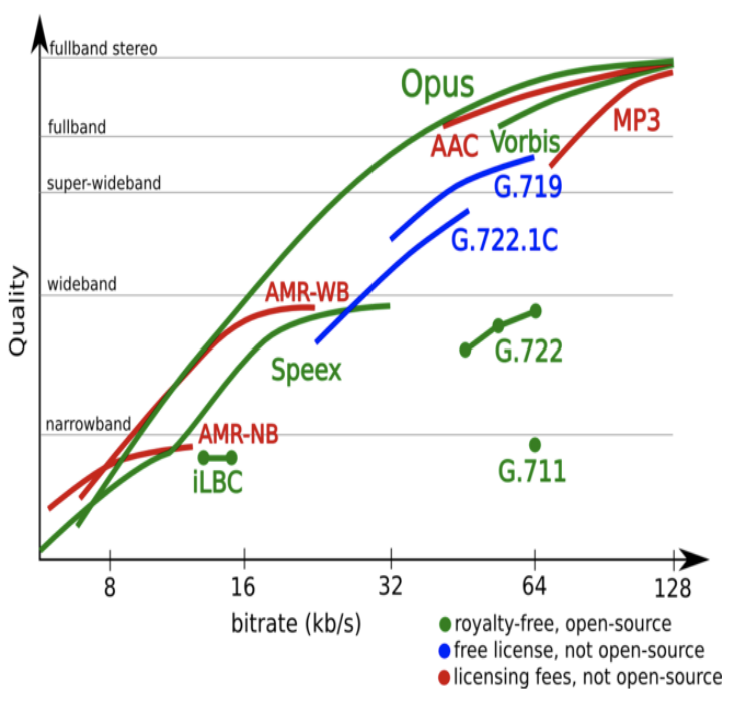
图9 音频编码器码率和质量对比图
图中绿色线条代表的是无专利要求且开源的编解码器,其中 G.711 和 G.722 是 ITU 早期应用于电信网络的语音编码标准,相应只支持窄带和宽带频率范围,码率相对固定,压缩率较低。蓝色线条代表的是无专利要求但是闭源的编解码器,相比 G.711 和 G.722,它们支持的频带更广。最后,红色线条代表的是有专利要求并且闭源的编解码器,其中 AAC 和 MP3 是 Fraunhofer 主导制定的音乐编解码器标准,广泛应用在数字音乐领域。
图10 则说明了各种编码器的编码延迟与码率的关系:
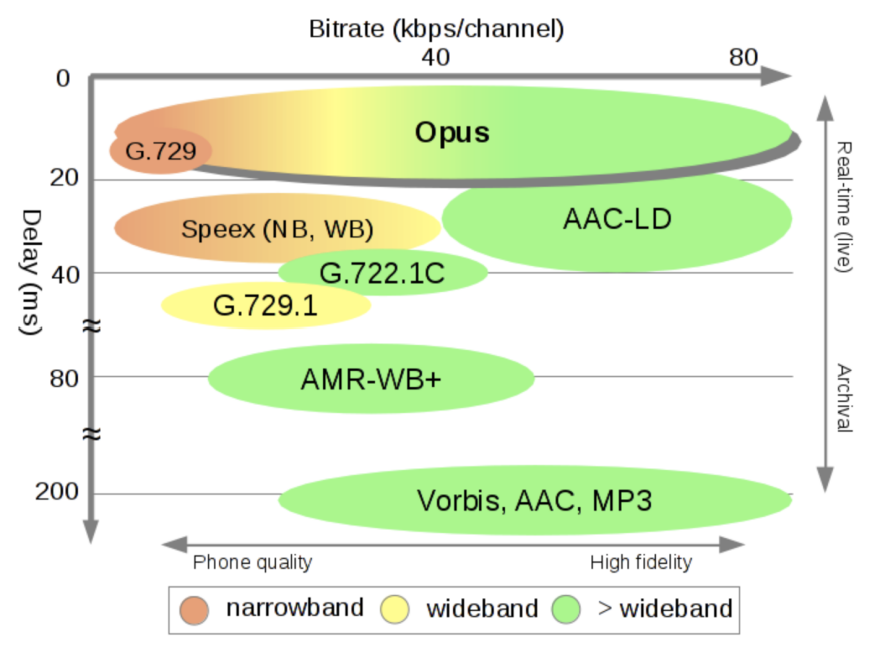
图10 音频编码器码率和编码延时对比图
从图中也可以看出,除了 Opus 以外,其他编解码器的码率变化范围相对较小,这与编解码器所覆盖的频带范围相关。另外,不同编解码器的编码延时也有明显差异,MP3 和 AAC 等音乐编解码器的编码延时较大。
由此,我们可以得出结论,Opus(RFC 6716) 是唯一一个覆盖全频带的音频编码器,并且它有如下的特性:
- 支持动态码率
- 在同等码率水平(高于8kbps),其质量高于其他音频编码器
- 其编码延迟低于其他音频编码器
带内 FEC
Opus 编解码器内部支持的原生带内 FEC 在 Speech 场景下,可以处理大约 20% 以内的丢包,其原理是通过当前帧携带前一帧的缩小版压缩包信息来恢复丢失的信源。如图11所示。
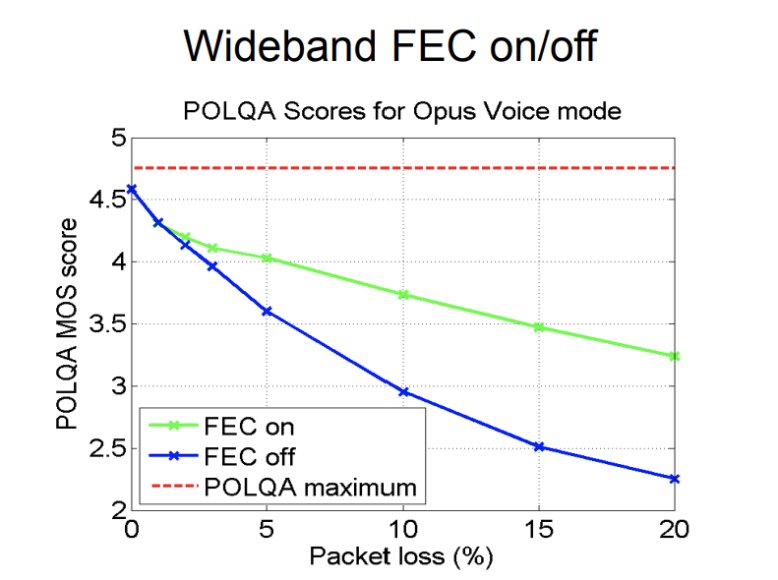
图11 官方 Opus inband FEC 抗丢包能力
具体到 Opus 编码器内部实现,inband FEC 是通过 LBRR(Low Bitrate Redundant)帧实现的。LBRR 帧包含了前一个音频帧的信息,和当前帧一起打包编码。图12是 LBRR 帧的编码代码。
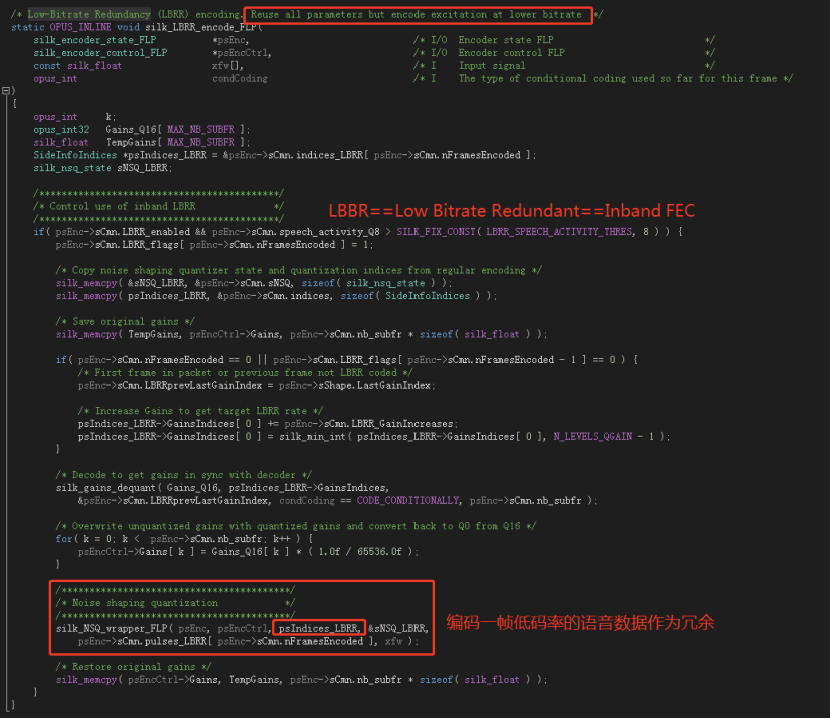
图12 Opus 带内 low bitrate redundant(LBRR)
PLC
以上介绍了多种带外抗丢包策略,下面简单介绍一下丢包补偿策略 PLC。
PLC(Packet Loss Concealment)丢包补偿是 Opus 编解码器中的一个可选项,在弱网传输场景下应该开启这个特征。
PLC 代码的实现根据收到的数据包模式的不同而有所不同:在 CELT 模式(audio)和 SILK 模式(speech),PLC 分别采用不同的方式进行丢包补偿。

图13 Opus PLC 官方介绍
5、总结
最后,我们总结一下音频RTC系统整体的结构,从系统角度分析一下,如图15所示。
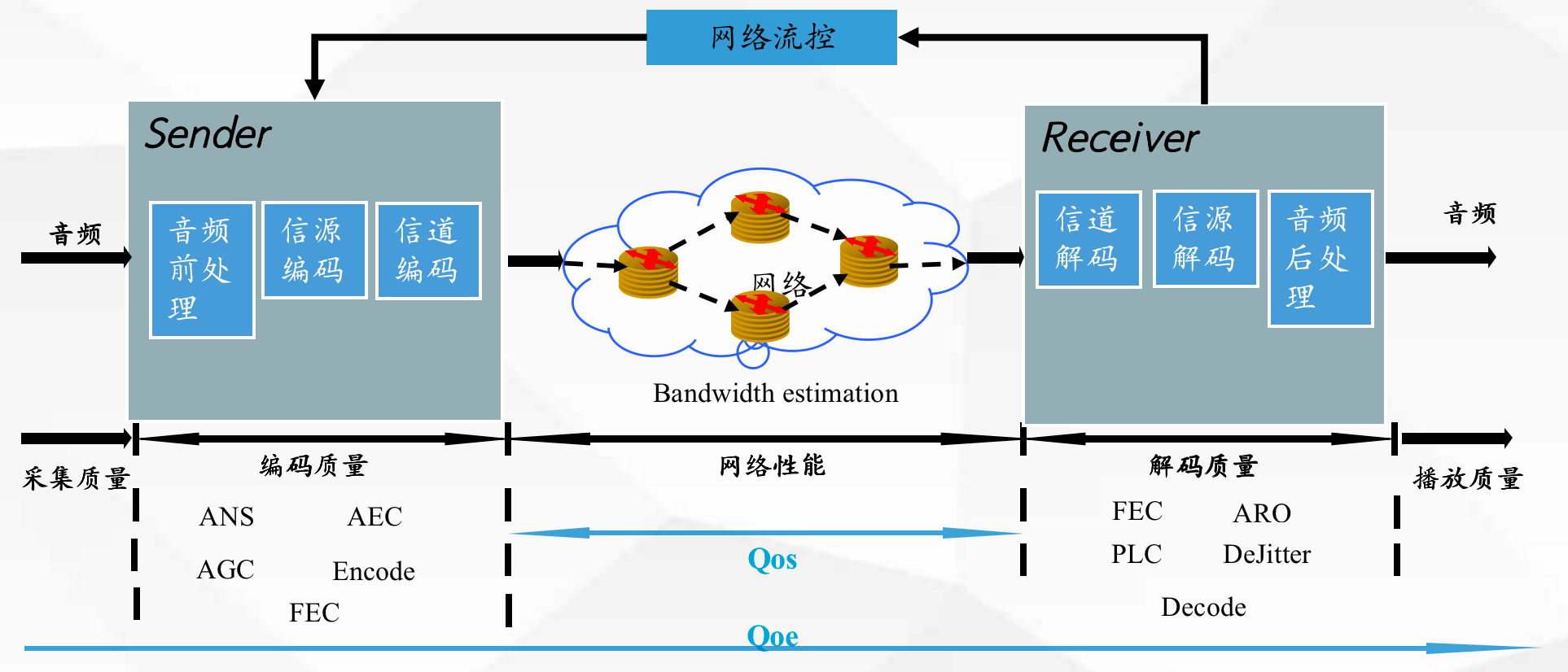
图15 音频 RTC 系统
今天分享了音频 RTC 系统的弱网对抗技术与实践,总结值得我们思考的几个方面:
- 表面上的音频卡顿,背后往往隐藏着各种各样的问题,需要对各个问题逐一进行分析;
- RTC 系统的任意一个环节出问题,最终呈现给用户的就是不足的音频体验;
- RTC 系统中各个模块组成一个有机整体,如何有效适应复杂多变的网络环境,将各个模块弱网对抗的能力有机结合,从而发挥最大的作用,是一个颇具挑战的课题,值得我们不断探索。
以上,就是本次分享的全部内容,本次分享的视频内容,可以点击“这里”进行观看。
作者介绍
崔承宗,网易云信音视频引擎专家,10余年音视频引擎开发经验,对 WebRTC 引擎、音视频会议系统、视频编解码技术有一定研究和实践经验。