一、
1、打开mysql服务
sudo service mysql start
2、root用户登录
mysql -uroot
3、查看数据库
show databases;
4、选择连接库
use <数据库名>
5、查看当前正在使用的库
select database();
6、查看表
show tables;
7、退出
quit或者exit
二、
1、新建数据库
出于严谨,而且便于区分保留字和变量名,保留字大写,变量和数据小写
CREATE DATABASE <数据库名字>;
2、新建数据表
CREATE TABLE 表的名字
(
列名a 数据类型(数据长度),
列名b 数据类型(数据长度),
列名c 数据类型(数据长度)
);
数据类型
CHAR 和 VARCHAR 的区别:
CHAR 的长度是固定的,而 VARCHAR 的长度是可以变化的,比如,存储字符串 “abc",对于 CHAR(10),表示存储的字符将占 10 个字节(包括 7 个空字符),而同样的 VARCHAR(12) 则只占用4个字节的长度,增加一个额外字节来存储字符串本身的长度,12 只是最大值,当你存储的字符小于 12 时,按实际长度存储。
ENUM和SET的区别:
ENUM 类型的数据的值,必须是定义时枚举的值的其中之一,即单选,而 SET 类型的值则可以多选。
想要了解更多关于 MySQL 数据类型的信息,可以参考下面两篇博客。
https://www.cnblogs.com/bukudekong/archive/2011/06/27/2091590.html
https://blog.csdn.net/anxpp/article/details/51284106#comments
3、插入数据
INSERT INTO 表的名字(列名a,列名b,列名c) VALUES(值1,值2,值3);
数据类型是 CHAR、VARCHAR、TEXT、DATE、TIME、ENUM 等的数据需要用单引号修饰,而 INT,FLOAT,DOUBLE 等则不需要。
三、SQL约束
CREATE DATABASE mysql_shiyan;
use mysql_shiyan;
CREATE TABLE department
(
dpt_name CHAR(20) NOT NULL,
people_num INT(10) DEFAULT '10',
CONSTRAINT dpt_pk PRIMARY KEY (dpt_name)#dpt_pk主键名(自定义)
);
CREATE TABLE employee
(
id INT(10) PRIMARY KEY,#主键
name CHAR(20),
age INT(10),
salary INT(10) NOT NULL,
phone INT(12) NOT NULL,
in_dpt CHAR(20) NOT NULL,
UNIQUE (phone),
CONSTRAINT emp_fk FOREIGN KEY (in_dpt) REFERENCES department(dpt_name)#emp_fk外键名字(自定义),in_dpt为外键,参考列为department表的dpt_name列。
);
CREATE TABLE project
(
proj_num INT(10) NOT NULL,
proj_name CHAR(20) NOT NULL,
start_date DATE NOT NULL,
end_date DATE DEFAULT '2015-04-01',
of_dpt CHAR(20) REFERENCES department(dpt_name),
CONSTRAINT proj_pk PRIMARY KEY (proj_num,proj_name)#proj_pk主键名字(自定义),proj_num,proj_name复合主键
);
AUTO_INCREMENT 自增
四、SELECT语句
建表语句
CREATE DATABASE mysql_shiyan;
use mysql_shiyan;
CREATE TABLE department
(
dpt_name CHAR(20) NOT NULL,
people_num INT(10) DEFAULT '10',
CONSTRAINT dpt_pk PRIMARY KEY (dpt_name)
);
CREATE TABLE employee
(
id INT(10) PRIMARY KEY,
name CHAR(20),
age INT(10),
salary INT(10) NOT NULL,
phone INT(12) NOT NULL,
in_dpt CHAR(20) NOT NULL,
UNIQUE (phone),
CONSTRAINT emp_fk FOREIGN KEY (in_dpt) REFERENCES department(dpt_name)
);
CREATE TABLE project
(
proj_num INT(10) NOT NULL,
proj_name CHAR(20) NOT NULL,
start_date DATE NOT NULL,
end_date DATE DEFAULT '2015-04-01',
of_dpt CHAR(20) REFERENCES department(dpt_name),
CONSTRAINT proj_pk PRIMARY KEY (proj_num,proj_name)
);
插入数据
#INSERT INTO department(dpt_name,people_num) VALUES('部门',人数);
INSERT INTO department(dpt_name,people_num) VALUES('dpt1',11);
INSERT INTO department(dpt_name,people_num) VALUES('dpt2',12);
INSERT INTO department(dpt_name,people_num) VALUES('dpt3',10);
INSERT INTO department(dpt_name,people_num) VALUES('dpt4',15);
#INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(编号,'名字',年龄,工资,电话,'部门');
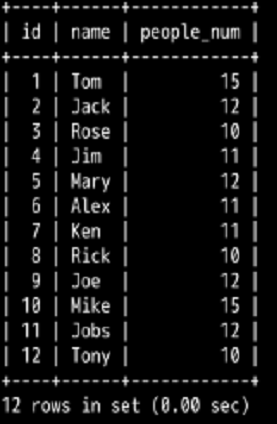
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(01,'Tom',26,2500,119119,'dpt4');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(02,'Jack',24,2500,120120,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(03,'Rose',22,2800,114114,'dpt3');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(04,'Jim',35,3000,100861,'dpt1');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(05,'Mary',21,3000,100101,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(06,'Alex',26,3000,123456,'dpt1');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(07,'Ken',27,3500,654321,'dpt1');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(08,'Rick',24,3500,987654,'dpt3');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(09,'Joe',31,3600,110129,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(10,'Mike',23,3400,110110,'dpt4');
INSERT INTO employee(id,name,salary,phone,in_dpt) VALUES(11,'Jobs',3600,019283,'dpt2');
INSERT INTO employee(id,name,salary,phone,in_dpt) VALUES(12,'Tony',3400,102938,'dpt3');
#INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(编号,'工程名','开始时间','结束时间','部门名');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(01,'proj_a','2015-01-15','2015-01-31','dpt2');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(02,'proj_b','2015-01-15','2015-02-15','dpt1');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(03,'proj_c','2015-02-01','2015-03-01','dpt4');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(04,'proj_d','2015-02-15','2015-04-01','dpt3');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(05,'proj_e','2015-02-25','2015-03-01','dpt4');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(06,'proj_f','2015-02-26','2015-03-01','dpt2');
基本格式:SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
1、查询表的所有内容
SELECT * FROM 表名字 WHERE 限制条件;
IN 用于筛选“在”某个范围内的结果
NOT IN 用于筛选“不在”某个范围内的结果
关键字 LIKE 可用于实现模糊查询,常见于搜索功能中。
和 LIKE 联用的通常还有通配符,代表未知字符。
SQL中的通配符是 _ 和 % 。其中 _ 代表一个未指定字符,% 代表不定个未指定字符
ORDER BY 对结果按某一列来排序
默认情况下,ORDER BY 的结果是升序排列,而使用关键词 ASC 和 DESC可指定升序或降序排序
SQL 有 5 个内置函数,这些函数都对 SELECT 的结果做操作:
COUNT:计数,可用于任何数据类型
SUM:求和,只能对数字类数据类型做计算
AVG:求平均值,只能对数字类数据类型做计算
MAX:最大值,可用于数值、字符串或是日期时间数据类型
MIN:最小值,可用于数值、字符串或是日期时间数据类型
6、子查询
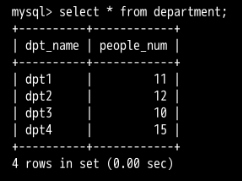

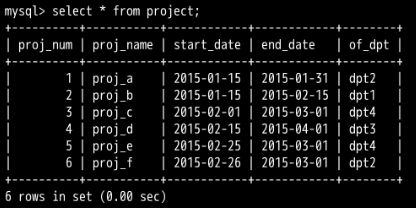
想要知道名为 "Tom" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,但工程信息储存在 project 表中。
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project GROUP BY of_dpt HAVING of_dpt IN (SELECT in_dpt FROM employee WHERE name='Tom');
HAVING 关键字的作用和 WHERE 是一样的,都是说明接下来要进行条件筛选操作。区别在于 HAVING 用于对分组后的数据进行筛选
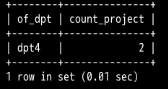
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 (join) 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
各员工所在部门的人数,其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表:
SELECT id,name,people_num FROM employee,department WHERE employee.in_dpt = department.dpt_name ORDER BY id;
或:
SELECT id,name,people_num FROM employee JOIN department ON employee.in_dpt = department.dpt_name ORDER BY id;
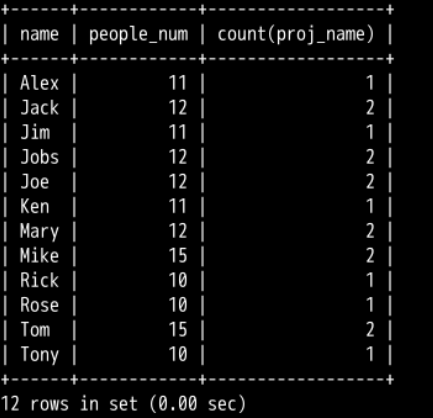
使用连接查询的方式,查询出各员工所在部门的人数与工程数,工程数命名为 count_project。(连接 3 个表,并使用 COUNT 内置函数)


分组不可或缺,否则会出现无意义的数据(一般来说连接查询语句中有 COUNT 就会有 GROUP BY)
正解
mysql> SELECT name, people_num, COUNT(proj_name) AS count_project -> FROM employee, department, project -> WHERE in_dpt = dpt_name AND of_dpt = dpt_name -> GROUP BY name, people_num;
五、数据库及表的修改和删除
1、删除数据库
DROP DATABASE test_01;
2、重命名一张表
RENAME TABLE 原名 TO 新名字;
或:
ALTER TABLE 原名 RENAME 新名;
或:
ALTER TABLE 原名 RENAME TO 新名;
3、删除一张表
DROP TABLE 表名字;
4、增加一列(新增加的列,被默认放置在这张表的最右边)
ALTER TABLE 表名字 ADD COLUMN 列名字 数据类型 约束;
或:
ALTER TABLE 表名字 ADD 列名字 数据类型 约束;
ALTER TABLE employee ADD height INT(4) DEFAULT 170;
提醒:语句中的 INT(4) 不是表示整数的字节数,而是表示该值的显示宽度,如果设置填充字符为 0,则 170 显示为 0170
5、增加一列(增加的列插入在指定位置)
需要在语句的最后使用AFTER关键词(“AFTER 列1” 表示新增的列被放置在 “列1” 的后面)。
ALTER TABLE employee ADD weight INT(4) DEFAULT 120 AFTER age;
6、增加一列(放在第一列的位置)
使用 FIRST 关键词
ALTER TABLE employee ADD test INT(10) DEFAULT 11 FIRST;
7、删除一列
ALTER TABLE 表名字 DROP COLUMN 列名字;
或:
ALTER TABLE 表名字 DROP 列名字;
8、重命名一列
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;
注意:这条重命名语句后面的 “数据类型” 不能省略,否则重命名失败。
9、改变数据类型
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;(当原列名和新列名相同的时候,指定新的数据类型或约束,就可以用于修改数据类型或约束。)
或:
ALTER TABLE 表名字 MODIFY 列名字 新数据类型;
需要注意的是,修改数据类型可能会导致数据丢失,所以要慎重使用。
10、修改表中某个值
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件;
注意:一定要有 WHERE 条件,否则会出现你不想看到的后果
11、删除一行记录
DELETE FROM 表名字 WHERE 条件;
注意: 删除表中的一行数据,也必须加上 WHERE 条件
六、其他基本操作
1、索引:可以加快查询速度
对一张表中的某个列建立索引
ALTER TABLE 表名字 ADD INDEX 索引名 (列名);
或:
CREATE INDEX 索引名 ON 表名字 (列名);
查看新建的索引
SHOW INDEX FROM 表名字;
在使用 SELECT 语句查询的时候,语句中 WHERE 里面的条件,会自动判断有没有可用的索引。
2、视图:是一种虚拟存在的表
创建视图的语句格式为:
CREATE VIEW 视图名(列a,列b,列c) AS SELECT 列1,列2,列3 FROM 表名字;
3、导入:从文件中导入数据到表
导入一个纯数据文件
LOAD DATA INFILE '文件路径和文件名' INTO TABLE 表名字;
SQL 语句的导入方式 source *.sql
4、导出:从表中导出到文件中
SELECT 列1,列2 INTO OUTFILE '文件路径和文件名' FROM 表名字;
注意:语句中 “文件路径” 之下不能已经有同名文件。
5、备份:mysqldump 备份数据库到文件
备份与导出的区别:导出的文件只是保存数据库中的数据;而备份,则是把数据库的结构,包括数据、约束、索引、视图等全部另存为一个文件。
mysqldump -u root 数据库名>备份文件名; #备份整个数据库
mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表
6、恢复:从文件恢复数据库
source *.sql
或:
CREATE DATABASE test; #新建一个名为test的数据库
mysql -u root test < bak.sql#退出 MySQL,然后输入语句进行恢复,把备份的 bak.sql 恢复到 test 数据库:
做个题吧(新东方的面试题)
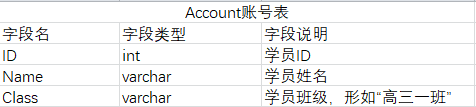
现有三张库表,分别为账号表Account、考试成绩表Exam、课程信息表Course,字段定义如下:


写sql输出高三年级人数大于50人的班的各学科平均分,按班级人数降序排序,查询结果形如下表:

SELECT 班级,班级人数,考试科目,班级平均分 from (select account.class as 班级,exam.course as 考试科目,avg(exam.score)as 班级平均分 from account join exam
on account.ID = exam.ID and account.class like '高三%' and account.class in(select class from account group by class having count(class)>50)
group by exam.course,account.class) as a join (select class,count(*)AS 班级人数 FROM account GROUP BY class HAVING count(class)>50) as b on a.班级=b.class ORDER BY 班级人数 DESC ;
优化:
select a.class,b.count,c.course,avg(score) FROM
account a
INNER JOIN
(select class,count(1) count from account where class like '高三%' group by class HAVING count(1)>50) b
on a.class=b.class
INNER JOIN
exam c
ON
c.id=a.id
group by a.class,c.course
order by b.count desc
有人说这个题目都不严谨,你发现了吗