要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息:

需要微信扫描登录
因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息:
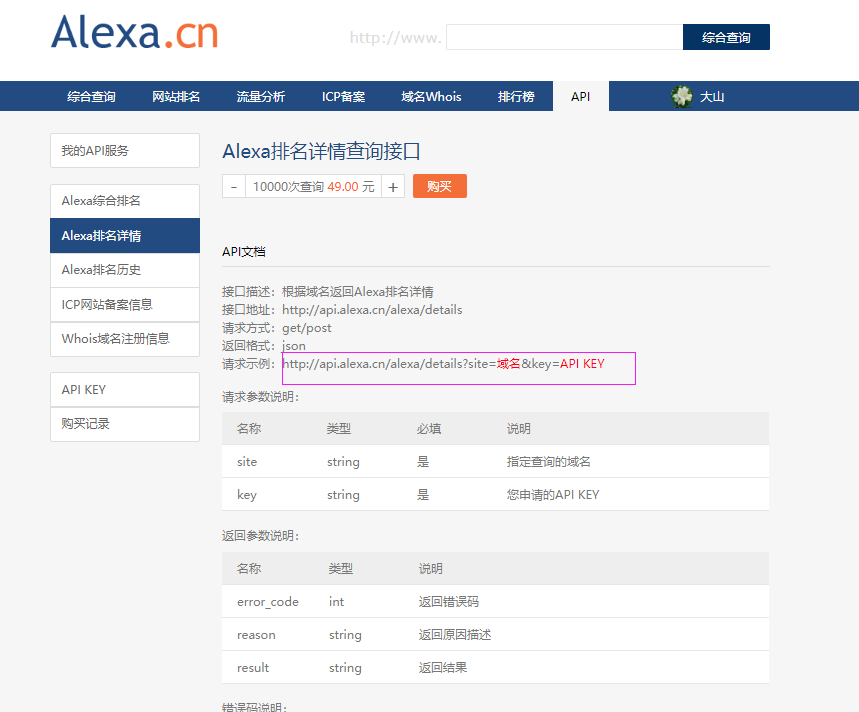
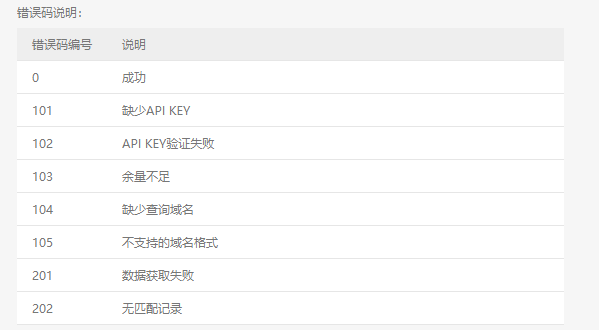

上面的API KEY值需要花钱买的(注意开通会员的方式不行,必须以10000次查询 49.00 元这种方式,比较坑爹啊)
具体python代码


# coding=utf-8 import json import httplib2 import json import xlrd import xlwt import os import datetime import time class alexa: def __init__(self,key="7Z4ddd6ywaQuo6RkKfI3SzGeKn8Mavde"): self.key = key def WriteLog(self, message,date): fileName = os.path.join(os.getcwd(), 'alexa/' + date + '.txt') with open(fileName, 'a') as f: f.write(message) def WriteSheetRow(self,sheet, rowValueList, rowIndex, isBold): i = 0 style = xlwt.easyxf('font: bold 1') # style = xlwt.easyxf('font: bold 0, color red;')#红色字体 style2 = xlwt.easyxf('pattern: pattern solid, fore_colour yellow; font: bold on;') # 设置Excel单元格的背景色为黄色,字体为粗体 for svalue in rowValueList: if isBold: sheet.write(rowIndex, i, svalue, style2) else: sheet.write(rowIndex, i, svalue) i = i + 1 def save_Excel(self,headList,valuelist,fileName): wbk = xlwt.Workbook() sheet = wbk.add_sheet('sheet1', cell_overwrite_ok=True) # headList = ['周期', '全球网站排名', '变化趋势', '日均UV'] rowIndex = 0 self.WriteSheetRow(sheet, headList, rowIndex, True) for lst in valuelist: rowIndex+=1 self.WriteSheetRow(sheet, lst, rowIndex, False) wbk.save(fileName) def getAlexaData(self,domain): url="http://api.alexa.cn/alexa/details?site=%s&key=%s"%(domain,self.key) try: h = httplib2.Http(".cache") (resp_headers, content) = h.request(url, "GET") data = json.loads(content.decode('utf8')) self.parserData(data) # print(data) except Exception as e1: error = "ex" def parserData(self,data): # f = open("alexa.txt", "r") # txt = f.read() # data = json.loads(txt) traffic_dict = data["result"]["traffic_data"] day = traffic_dict["day"] week = traffic_dict["week"] month = traffic_dict["month"] three_month = traffic_dict["three_month"] trafic_headList = ['周期', '全球网站排名', '变化趋势', '日均UV', '日均PV'] traffic_data_list =[] day_list = ["当日"] week_list = ["周平均"] month_list = ["月平均"] three_month_list = ["三月平均"] trafic = ["time_range", "traffic_rank", "traffic_rank_delta", "avg_daily_uv", "avg_daily_pv"] length = len(trafic) for i in range(1,length): day_list.append(day[trafic[i]]) week_list.append(week[trafic[i]]) month_list.append(month[trafic[i]]) three_month_list.append(three_month[trafic[i]]) traffic_data_list.append(day_list) traffic_data_list.append(week_list) traffic_data_list.append(month_list) traffic_data_list.append(three_month_list) fileName = datetime.datetime.now().strftime('%Y-%m-%d')+"_traffic.xlsx" fileName = os.path.join(os.getcwd(),fileName) self.save_Excel(trafic_headList,traffic_data_list,fileName) country_headList = ['国家/地区名称', '国家/地区代码', '国家/地区排名', '网站访问比例', '页面浏览比例'] country_data_list = [] country_data = data["result"]["country_data"] col_list = ["country","code","rank","per_users","per_pageviews"] length = len(col_list) for item in country_data: lst =[] for i in range(0,length): lst.append(item[col_list[i]]) country_data_list.append(lst) fileName = datetime.datetime.now().strftime('%Y-%m-%d') + "_country.xlsx" fileName = os.path.join(os.getcwd(), fileName) self.save_Excel(country_headList, country_data_list, fileName) subdomains_headList = ['被访问网址', '近月网站访问比例', '近月页面访问比例', '人均页面浏览量'] subdomains_data_list = [] subdomains_data = data["result"]["subdomains_data"] sub_col_list = ["subdomain", "reach_percentage", "pageviews_percentage", "pageviews_peruser"] length = len(sub_col_list) for item in subdomains_data: lst = [] for i in range(0, length): lst.append(item[sub_col_list[i]]) subdomains_data_list.append(lst) fileName = datetime.datetime.now().strftime('%Y-%m-%d') + "_subdomains.xlsx" fileName = os.path.join(os.getcwd(), fileName) self.save_Excel(subdomains_headList, subdomains_data_list, fileName) # print(("%s,%s,%s,%s,%s") % (day[trafic[0]], day[trafic[1]], day[trafic[2]], day[trafic[3]], day[trafic[4]])) # print(("%s,%s,%s,%s,%s") % (week[trafic[0]], week[trafic[1]], week[trafic[2]], week[trafic[3]], week[trafic[4]])) # print(("%s,%s,%s,%s,%s") % (month[trafic[0]], month[trafic[1]], month[trafic[2]], month[trafic[3]], month[trafic[4]])) # print(("%s,%s,%s,%s,%s") % (three_month[trafic[0]], three_month[trafic[1]], three_month[trafic[2]], three_month[trafic[3]], three_month[trafic[4]])) # print(" ") # print("country_data") # country_data = data["result"]["country_data"] # for item in country_data: # print(("%s,%s,%s,%s,%s") % (item["country"], item["code"], item["rank"], item["per_users"], item["per_pageviews"])) # # print(" ") # print("subdomains_data") # subdomains_data = data["result"]["subdomains_data"] # for item in subdomains_data: # print(("%s,%s,%s,%s") % (item["subdomain"], item["reach_percentage"], item["pageviews_percentage"], item["pageviews_peruser"])) obj = alexa() obj.getAlexaData("baidu.com") # obj.parserData("")