初步总结的SSD和yolo-v3之间的一些区别。
其中的一些概念还有待充分解释。
| SSD | YOLOv3 | |
|---|---|---|
| Loss | Softmax loss | Logistic loss |
| Feature extractor | VGG19 | Darknet-53 |
| Bounding Box Prediction | direct offset with default box | offset with gird cell by sigmoid activation |
| Anchor box | Different scale and aspect ratio | K-means from coco and VOC |
| Small objects | Semantic value for bottom layer is not high. Worse for small objects. | Higher resolution layers have higher semantic values. Better for small objects. |
| Big objects | Better. Feature map rangers from 38 * 38 to 3 * 3 ,1 * 1. | Worse. 13 * 13 feature map is the most coarse-grained. |
| Data Augmentation | different sample IOU crop on original image | randomly put the scaled original image (from 0.25 to 2) on the gray canvas |
| Input | resize original image to fixed size | Random multi-scale input |
| FPN | no | with FPN |
SSD的loss中,不同类别的分类器是softmax,最终检测目标的类别只能是一类。而在yolo-v3中,例如对于80类的coco数据集,对于类别进行判断是80个logistic分类器,只要输出大于设置的阈值,则都是物体的类别,物体同时可以属于多类,例如一个物体同时是person和woman。
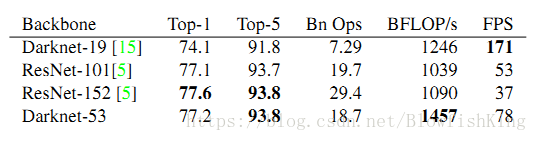
Backbone network。ssd原版的基础网络就是VGG19,也可以用mobile-net、resnet等。yolo-v3的基础网络是作者自己设计的darknet-53(因为具有53个卷积层),借鉴了resnet的shortcut层,根据作者的话,以更少的参数、更少的计算量实现了接近的效果。
Anchor box。ssd从faster-rcnn中吸收了这一思想,采用的是均匀地将不同尺寸的default box分配到不同尺度的feature map上。例如6个feature map的尺度,default box的大小从20%到90%的占比,同时有aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] ,最终可以计算出不同default box大小。而yolo-v3延续了yolo-v2的方法:从coco数据集中对bouding box 的(width, height)进行聚类,作者聚出9类,每类中心点取出作为一个box_size, 将每三个box_size划分给一个feature map。例如总共有(10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198), (373,326)共9组w,h, 作者将后三个(116,90), (156,198), (373,326)作为13 * 13 的gird cell上的anchor box size。
图片输入。yolo-v3将输入图片映射到第一层feature map的固定比例是32。对于输入为416 * 416的图片,第一层feature map 大小为13 * 13。但是yolo-v3支持从300到600的所有32的倍数的输入。例如输入图片为320 * 320,这样第一层feature map就为10 * 10,在这样的gird cell中同样可以进行predict和match groudtruth。
Bounding Box 的预测方法。在不同的gird cell上,SSD预测出每个box相对于default box的位置偏移和宽高值。yolo-v3的作者觉得这样刚开始训练的时候,预测会很不稳定。因为位置偏移值在float的范围内都有可能,出现一个很大的值的话,位置都超出图片范围了,都是完全无效的预测了。所以yolov3的作者对于这位置偏移值都再做一个sigmoid激活,将范围缩为0-1 。b_x和b_y的值在(cell_x_loc, cell_x_loc+1), (cell_y_loc, cell_y_loc+1)之间波动。
</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-095d4a0b23.css" rel="stylesheet">
</div>
yolov3为什么比ssd好.
不仅仅因为YOLO V3引入FPN结构,同时它的检测层由三级feature layers融合,而SSD的六个特征金字塔层全部来自于FCN的最后一层,其实也就是一级特征再做细化,明显一级feature map的特征容量肯定要弱于三级,尤其是浅层包含的大量小物体特征。