第一章
工程涉及的基本工具:requests, beautiful soup, scrapy。
法规与技术约定:read the Terms & Conditions and the Privacy Policy of the website。让不让爬?
See the robots.txt file 。哪些可以爬?
website’s HTML code。目标网页涉及什么技术?
task and the website's structure.。该选什么工具?
Terms and Robots重点读:scraper/scraping
crawler/crawling
bot
spider
program
网页技术:使用python的builtwith库探查网页使用的技术
谷歌浏览器开发者工具:勘察网页
工具选择:small project(简单页面、没有涉及js的) Beautiful Soup + requests or use Scrapy。
有大量数据的,追求性能的 Scrapy + Beautiful Soup。
面对AJAX技术就要打电话摇人了,Selenium and Portia 出场。
第二章 输入请求
确定目标页面,查看目标页的robots.txt文件
对目标页面进行分析,确定找到目标信息的关键步骤
将整个爬取任务分解为几个步骤
整个网站就是一个树形图,域名为主干最终的页面即为叶子,叶子通过分支连接着域名
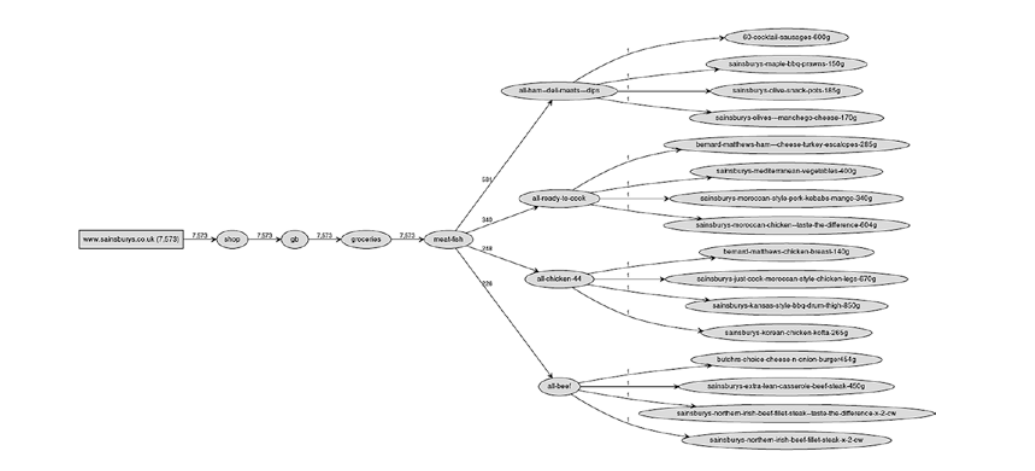
爬虫搜索页面就有了两种方法,一种是广度优先,层层递进式的搜索,另一种是深度优先,一条路走到头,回来再走下一条
第三章 使用BeautifulSoup
导入:from bs4 import BeautifulSoup
它用来解析html内容,提取目标信息
信息保存到csv,json文件
保存到关系数据库
保存到非关系数据库
改进: 1、使用不同的html解析器,html.parser(python自带), lxml(速度快), lxml-xml, html5lib(非常慢)
2、只解析需要的部分,使用SoupStrainer对象,例:
strainer = SoupStrainer(name='ul', attrs={'class':
'productLister gridView'})
soup = BeautifulSoup(content, 'html.parser', parse_only=strainer)
BeautifulSoup(content, 'html.parser', name='ul',
attrs={'class': ['productLister gridView',
'categories shelf', 'categories aisles']})
3、即时保存,减少数据丢失
4、使用缓存中间件保存中间步骤获取的数据,获得更好的性能
5、本地缓存整个网站,缓存的基本思想是创建标识网站的密钥,我们使用它作为键,页面的内容就是值,根据URL创建一个哈希,哈希很短,如果您选择一个好的算法,您可以避免大量页面的冲突。我将使用hashlib.blake2b哈希函数,因为它比常用的哈希(例如MD5)更快,并且它与SHA-313一样安全。此外,该算法生成128个字符,这对于所有三个主导操作系统来说都足够短。

6、基于文件的缓存,将数据保存到文件。数据库缓存,将数据保存到关系数据库或非关系数据库
7、保存空间问题,数据量很大的话就要考虑节省保存空间,保存时压缩页面内容可以节省空间,读取时就需要解压缩,解压缩会增加一些计算时间,我们这里的策略是以时间换空间
8、更新缓存,确定缓存失效时间,超时后更新缓存