一、数据驱动作用域
1.1.支持支持测试用例 / 步骤层级的参数化驱动配置
1.2.配置方式包括三个部分:参数定义、数据源指定、数据源准备
二、参数定义 & 数据源指定
2.1.参数位置
config模块中,新增一个parameters字段,参数化的定义均放置在该字段下
2.2.参数定义内容
包括参数名称和数据源指定
2.3.参数名称定义
独立参数单独进行定义;
多个参数具有关联性的参数需要将其定义在一起,采用短横线(-)进行连接。
- config:
parameters:
- username - password:
- ["user1", "111111"]
- ["user2", "222222"]
- ["user3", "333333"]
2.4.数据源指定
在YAML / JSON中直接指定参数列表通过内置的parameterize(可简写为P)函数引用CSV文件调用debugtalk.py中自定义的函数生成参数列表
示例如:
- config:
name: "demo"
parameters:
- user_agent: ["iOS/10.1", "iOS/10.2", "iOS/10.3"]
- user_id: ${P(user_id.csv)}
- username - password: ${get_account(10)}
三、数据源准备
3.1.数据较少,使用参数列表,进行该配置后,测试用例在运行时就会对user_agent实现数据驱动,即分别使用"iOS/10.1"、"iOS/10.2"、"iOS/10.3"三个值运行测试用例。如:
- config:
parameters:
- user_agent: ["iOS/10.1", "iOS/10.2", "iOS/10.3"]
对于具有关联性的多个参数,进行该配置后,测试用例在运行时就会对username和password实现数据驱动,并且保证参数值总是成对使用例如
username和password,那么就可以按照如下方式进行配置:
- config:
parameters:
- username - password:
- ["user1", "111111"]
- ["user2", "222222"]
- ["user3", "333333"]
3.2.数据量比较大,引用CSV数据文件
CSV数据文件遵守:
文件需放置在与测试用例文件相同的目录中;
CSV文件中的第一行必须为参数名称,从第二行开始为参数值,每个(组)值占一行;
若同一个CSV文件中具有多个参数,则参数名称和数值的间隔符需实用英文逗号。
parameters引用注意事项:
参数名称必须与CSV文件中第一行的参数名称一致:
顺序可以不一致(参数顺序无需与CSV文件中参数名称的顺序一致):
参数个数也可以不一致(可以只引用部分参数)。
单参数引用方式:
user_id
1001
1002
...
1999
2000
- config:
parameters:
- user_id: ${parameterize(user_id.csv)}
- user_id: ${P(user_id.csv)} # 简写方式
关联性的多个参数引用方式,例如
username和password,创建 account.csv,如
username, password
test1, 111111
test2, 222222
test3, 333333
- config:
parameters:
- username - password: ${parameterize(account.csv)}
- username - password: ${P(account.csv)} # 简写方式
自定义函数生成参数列表
在debugtalk.py定义获取参数列表函数,如:
1、固定数据
def get_account():
return [
{"user_id": 1001},
{"user_id": 1002},
{"user_id": 1003},
{"user_id": 1004}
]
2、生成指定数量的参数列表
def get_account(num):
accounts = []
for index in range(1, num + 1):
accounts.append(
{"username": "user%s" % index, "password": str(index) * 6},
)
return accounts
parameters引用
- config:
parameters:
- username - password: ${get_account(10)}
四、参数化运行
参数定义和数据源准备后参数化运行(与普通测试用例的运行完全一致)。
采用hrun命令运行自动化测试:
$ hrun tests / data / demo_parameters.yml
采用locusts命令运行性能测试:
$ locusts - f tests / data / demo_parameters.yml
运行方式一致,实现功能区别:
1、测试用例在运行时会分别运行每一种组合情况
2、自动化测试时遍历一遍后会终止执行
3、性能测试时每个用户都会循环遍历
五、案例分析
如获取token的接口,我们需要使用user_agent和app_version这两个参数来进行参数化数据驱动
app_version
2.8.5
2.8.6
def get_os_platform():
return [
{"os_platform": "ios"},
{"os_platform": "android"}
]
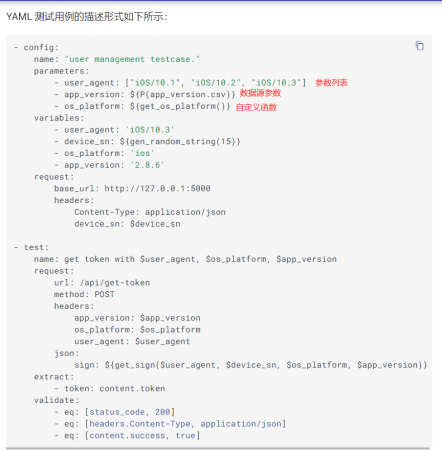
经过笛卡尔积组合,应该总共有 3 * 2 * 2 种参数组合情况
