一、spark安装
因为之前安装过hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,然后,点击“Download Spark”后面的“spark-2.1.0-bin-without-hadoop.tgz”下载即可。Pre-build with user-provided Hadoop: 属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。

上传spark软件包到任意节点上
解压缩spark软件包到/usr/local/目录下
![]()
重命名为spark文件夹
mv spark-2.1.0-bin-without-hadoop/ spark
重命名conf/目录下spark-env.sh.template为spark-env.sh
cp spark-env.sh.template spark-env.sh
重命名conf/目录下slaves.template为slaves
mv slaves.template slaves
二、配置spark
编辑conf/spark-env.sh文件,在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
#上述表示Spark可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
export JAVA_HOME=/usr/local/jdk64/jdk1.8.0
编辑conf/slaves文件
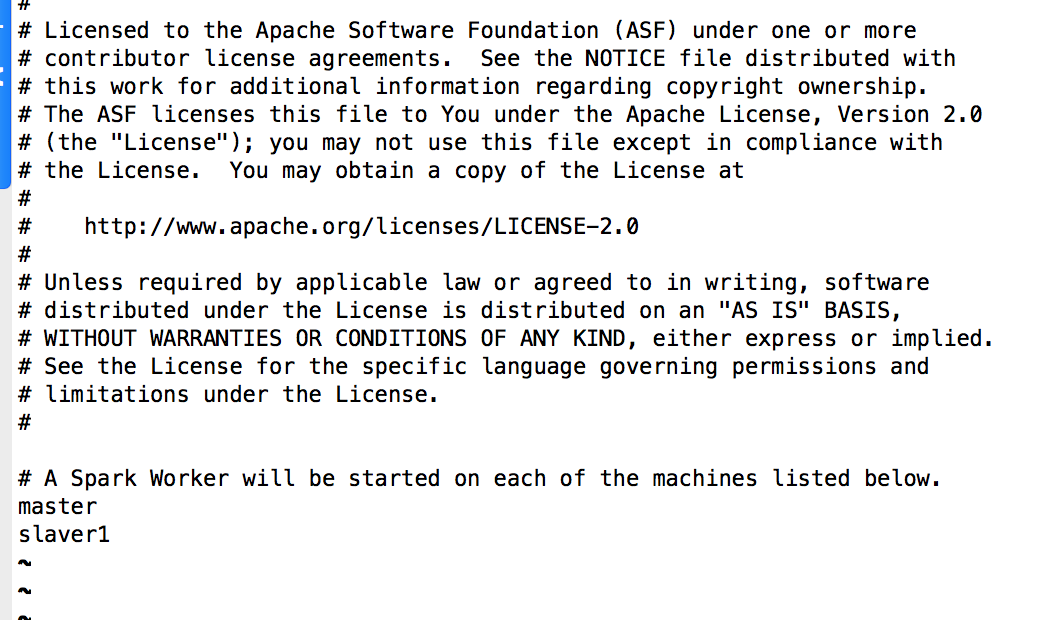
三、验证spark是否安装成功
在spark目录中输入命令验证spark是否安装成功
bin/run-example SparkPi
bin/run-example SparkPi 2>&1 | grep "Pi is" #过滤显示出pi的值

web界面为8080端口
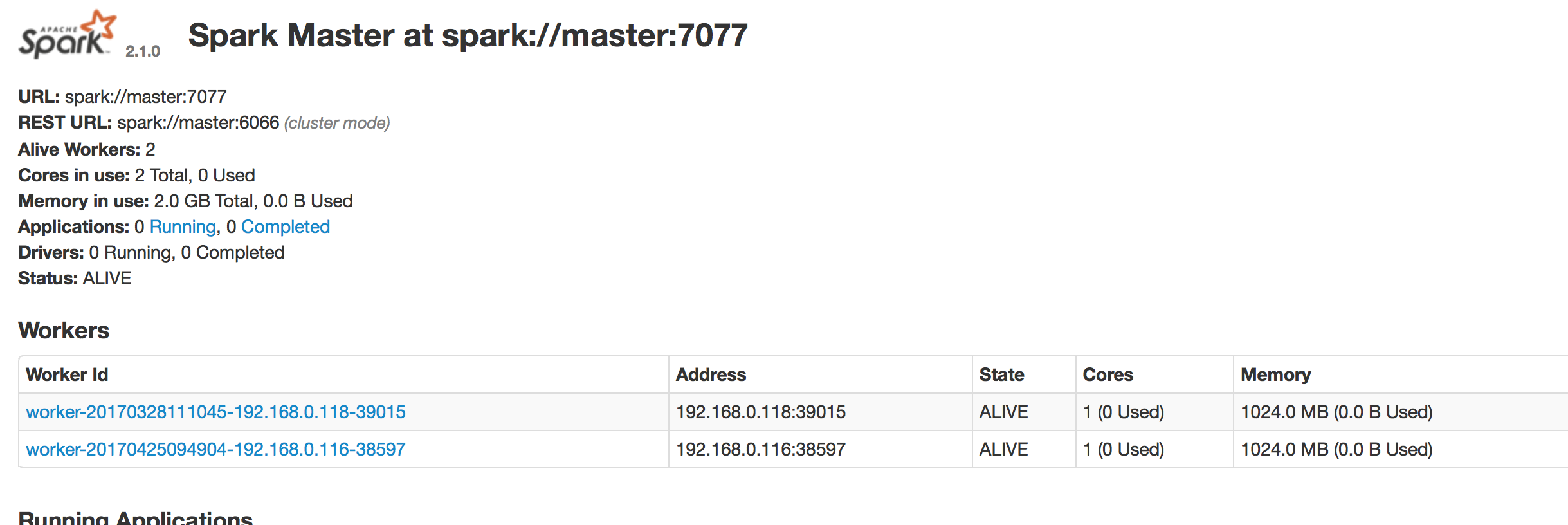
集群模式下shell
pyspark --master spark://master:7077 #python
提交应用
spark-submit
--class <main-class> #需要运行的程序的主类,应用程序的入口点
--master <master-url> #Master URL,下面会有具体解释
--deploy-mode <deploy-mode> #部署模式
... # other options #其他参数
<application-jar> #应用程序JAR包
[application-arguments] #传递给主类的主方法的参数