1、测试数据
test <- c(5.3, 5.6, 0.7, 0.6, 1.3, 2.8, 2.9, 2.1, 2.4, 3.7, 4.2, 4.9, 4.7, 4.8, 4.2)

2、生成统计节点
breaks <- seq(0, 6, length.out = 7) ## 生成统计节点 breaks test.break = cut(test, breaks) ##按照统计节点归类数据 test.break class(test.break) length(test.break)

3、统计频数频率、密度
freq <- table(test.break) freq densi <- freq / length(test) densi

4、画直方图
a、频数图
hist(test, breaks = breaks,labels = T)
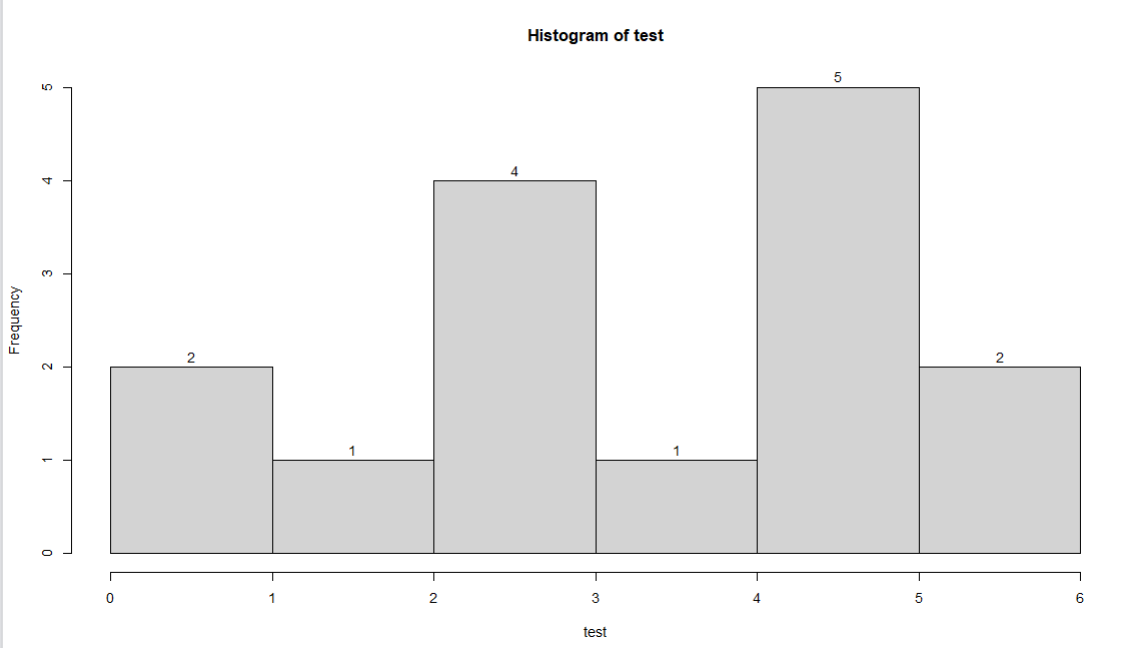
b、密度图
hist(test, breaks = breaks,labels = T, freq = F)
