循环冗余校验检错方案:
奇偶校验码(PCC)只能校验一位错误,本节所要介绍的循环冗余校验码(CRC)的检错能力更强,可以检出多位错误。
1. CRC校验原理
CRC校验原理看起来比较复杂,好难懂,因为大多数书上基本上是以二进制的多项式形式来说明的。其实很简单的问题,其根本思想就是先在要发送的帧后面附加一个数(这个就是用来校验的校验码,但要注意,这里的数也是二进制序列的,下同),生成一个新帧发送给接收端。当然,这个附加的数不是随意的,它要使所生成的新帧能与发送端和接收端共同选定的某个特定数整除(注意,这里不是直接采用二进制除法,而是采用一种称之为“模2除法”)。到达接收端后,再把接收到的新帧除以(同样采用“模2除法”)这个选定的除数。因为在发送端发送数据帧之前就已通过附加一个数,做了“去余”处理(也就已经能整除了),所以结果应该是没有余数。如果有余数,则表明该帧在传输过程中出现了差错。
【说明】“模2除法”与“算术除法”类似,但它既不向上位借位,也不比较除数和被除数的相同位数值的大小,只要以相同位数进行相除即可。模2加法运算为:1+1=0,0+1=1,0+0=0,无进位,也无借位;模2减法运算为:1-1=0,0-1=1,1-0=1,0-0=0,也无进位,无借位。相当于二进制中的逻辑异或运算。也就是比较后,两者对应位相同则结果为“0”,不同则结果为“1”。如100101除以1110,结果得到商为11,余数为1,如图5-9左图所示。如11×11=101,如图5-9右图所示。


图5-9 “模2除法”和“模2乘法”示例
具体来说,CRC校验原理就是以下几个步骤:
(1)先选择(可以随机选择,也可按标准选择,具体在后面介绍)一个用于在接收端进行校验时,对接收的帧进行除法运算的除数(是二进制比较特串,通常是以多项方式表示,所以CRC又称多项式编码方法,这个多项式也称之为“生成多项式”)。
(2)看所选定的除数二进制位数(假设为k位),然后在要发送的数据帧(假设为m位)后面加上k-1位“0”,然后以这个加了k-1个“0“的新帧(一共是m+k-1位)以“模2除法”方式除以上面这个除数,所得到的余数(也是二进制的比特串)就是该帧的CRC校验码,也称之为FCS(帧校验序列)。但要注意的是,余数的位数一定要是比除数位数只能少一位,哪怕前面位是0,甚至是全为0(附带好整除时)也都不能省略。
(3)再把这个校验码附加在原数据帧(就是m位的帧,注意不是在后面形成的m+k-1位的帧)后面,构建一个新帧发送到接收端,最后在接收端再把这个新帧以“模2除法”方式除以前面选择的除数,如果没有余数,则表明该帧在传输过程中没出错,否则出现了差错。
通过以上介绍,大家一定可以理解CRC校验的原理,并且不再认为很复杂吧。
从上面可以看出,CRC校验中有两个关键点:一是要预先确定一个发送端和接收端都用来作为除数的二进制比特串(或多项式);二是把原始帧与上面选定的除进行二进制除法运算,计算出FCS。前者可以随机选择,也可按国际上通行的标准选择,但最高位和最低位必须均为“1”,如在IBM的SDLC(同步数据链路控制)规程中使用的CRC-16(也就是这个除数一共是17位)生成多项式g(x)= x16 + x15 + x2 +1(对应二进制比特串为:11000000000000101);而在ISO HDLC(高级数据链路控制)规程、ITU的SDLC、X.25、V.34、V.41、V.42等中使用CCITT-16生成多项式g(x)=x16 + x15 + x5 +1(对应二进制比特串为:11000000000100001)。
2. CRC校验码的计算示例
由以上分析可知,既然除数是随机,或者按标准选定的,所以CRC校验的关键是如何求出余数,也就是CRC校验码。
下面以一个例子来具体说明整个过程。现假设选择的CRC生成多项式为G(X) = X4 + X3 + 1,要求出二进制序列10110011的CRC校验码。下面是具体的计算过程:
(1)首先把生成多项式转换成二进制数,由G(X) = X4 + X3 + 1可以知道(,它一共是5位(总位数等于最高位的幂次加1,即4+1=5),然后根据多项式各项的含义(多项式只列出二进制值为1的位,也就是这个二进制的第4位、第3位、第0位的二进制均为1,其它位均为0)很快就可得到它的二进制比特串为11001。
(2)因为生成多项式的位数为5,根据前面的介绍,得知CRC校验码的位数为4(校验码的位数比生成多项式的位数少1)。因为原数据帧10110011,在它后面再加4个0,得到101100110000,然后把这个数以“模2除法”方式除以生成多项式,得到的余数,即CRC校验码为0100,如图5-10所示。注意参考前面介绍的“模2除法”运算法则。
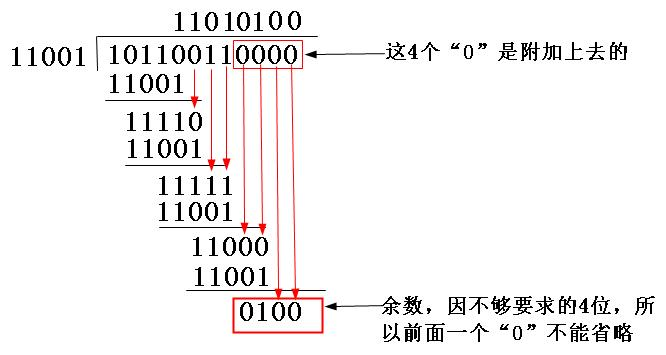
图5-10 CRC校验码计算示例
(3)把上步计算得到的CRC校验码0100替换原始帧101100110000后面的四个“0”,得到新帧101100110100。再把这个新帧发送到接收端。
(4)当以上新帧到达接收端后,接收端会把这个新帧再用上面选定的除数11001以“模2除法”方式去除,验证余数是否为0,如果为0,则证明该帧数据在传输过程中没有出现差错,否则出现了差错。
---------------------------------------------------------------------------------------------------------------------------------------
标准CRC生成多项式如下表:
名称 生成多项式 简记式* 标准引用
CRC-4 x4+x+1 3 ITU G.704
CRC-8 x8+x5+x4+1 0x31
CRC-8 x8+x2+x1+1 0x07
CRC-8 x8+x6+x4+x3+x2+x1 0x5E
CRC-12 x12+x11+x3+x+1 80F
CRC-16 x16+x15+x2+1 8005 IBM SDLC
CRC16-CCITT x16+x12+x5+1 1021 ISO HDLC, ITU X.25, V.34/V.41/V.42, PPP-FCS
CRC-32 x32+x26+x23+...+x2+x+1 04C11DB7 ZIP, RAR, IEEE 802 LAN/FDDI, IEEE 1394, PPP-FCS
CRC-32c x32+x28+x27+...+x8+x6+1 1EDC6F41 SCTP
生成多项式的最高位固定的1,故在简记式中忽略最高位1了,如0x1021实际是0x11021。
I、基本算法(人工笔算):
以CRC16-CCITT为例进行说明,CRC校验码为16位,生成多项式17位。假如数据流为4字节:BYTE[3]、BYTE[2]、BYTE[1]、BYTE[0];
数据流左移16位,相当于扩大256×256倍,再除以生成多项式0x11021,做不借位的除法运算(相当于按位异或),所得的余数就是CRC校验码。
发送时的数据流为6字节:BYTE[3]、BYTE[2]、BYTE[1]、BYTE[0]、CRC[1]、CRC[0];
注意:使用长除法进行计算式,需要将除数多项式与预置位0x0000或0xFFFF异或以后再进行计算。
II、计算机算法1(比特型算法):
1)将扩大后的数据流(6字节)高16位(BYTE[3]、BYTE[2])放入一个长度为16的寄存器;
2)如果寄存器的首位为1,将寄存器左移1位(寄存器的最低位从下一个字节获得),再与生成多项式的简记式异或;
否则仅将寄存器左移1位(寄存器的最低位从下一个字节获得);
3)重复第2步,直到数据流(6字节)全部移入寄存器;
4)寄存器中的值则为CRC校验码CRC[1]、CRC[0]。
III、计算机算法2(字节型算法):256^n表示256的n次方
把按字节排列的数据流表示成数学多项式,设数据流为BYTE[n]BYTE[n-1]BYTE[n-2]、、、BYTE[1]BYTE[0],表示成数学表达式为BYTE[n]×256^n+BYTE[n-1]×256^(n-1)
+...+BYTE[1]*256+BYTE[0],在这里+表示为异或运算。设生成多项式为G17(17bit),CRC码为CRC16。
则,CRC16=(BYTE[n]×256^n+BYTE[n-1]×256^(n-1)+...+BYTE[1]×256+BYTE[0])×256^2/G17,即数据流左移16位,再除以生成多项式G17。
先变换BYTE[n-1]、BYTE[n-1]扩大后的形式,
CRC16=BYTE[n]×256^n×256^2/G17+BYTE[n-1]×256^(n-1)×256^2/G17+...+BYTE[1]×256×256^2/G17+BYTE[0]×256^2/G17
=(Z[n]+Y[n]/G17)×256^n+BYTE[n-1]×256^(n-1)×256^2/G17+...+BYTE[1]×256×256^2/G17+BYTE[0]×256^2/G17
=Z[n]×256^n+{Y[n]×256/G17+BYTE[n-1]×256^2/G17}×256^(n-1)+...+BYTE[1]×256×256^2/G17+BYTE[0]×256^2/G17
=Z[n]×256^n+{(YH8[n]×256+YHL[n])×256/G17+BYTE[n-1]×256^2/G17}×256^(n-1)+...+BYTE[1]×256×256^2/G17+BYTE[0]×256^2/G17
=Z[n]×256^n+{YHL[n]×256/G17+(YH8[n]+BYTE[n-1])×256^2/G17}×256^(n-1)+...+BYTE[1]×256×256^2/G17+BYTE[0]×256^2/G17
这样就推导出,BYTE[n-1]字节的CRC校验码为{YHL[n]×256/G17+(YH8[n]+BYTE[n-1])×256^2/G17},即上一字节CRC校验码Y[n]的高8位(YH8[n])与本字节BYTE[n-1]异或,
该结果单独计算CRC校验码(即单字节的16位CRC校验码,对单字节可建立表格,预先生成对应的16位CRC校验码),所得的CRC校验码与上一字节CRC校验码Y[n]的低8位(YL8[n])
乘以256(即左移8位)异或。然后依次逐个字节求出CRC,直到BYTE[0]。
字节型算法的一般描述为:本字节的CRC码,等于上一字节CRC码的低8位左移8位,与上一字节CRC右移8位同本字节异或后所得的CRC码异或。
字节型算法如下:
1)CRC寄存器组初始化为全"0"(0x0000)。(注意:CRC寄存器组初始化全为1时,最后CRC应取反。)
2)CRC寄存器组向左移8位,并保存到CRC寄存器组。
3)原CRC寄存器组高8位(右移8位)与数据字节进行异或运算,得出一个指向值表的索引。
4)索引所指的表值与CRC寄存器组做异或运算。
5)数据指针加1,如果数据没有全部处理完,则重复步骤2)。
6)得出CRC。
CRC CCITT—1,“-1”的意思是CRC的初值为0Xffff。
方法1:将存有数据的字节数组进行逐位计算,求得字节形式的CRC
typedef unsigned __int16 INT16U;
#define CRC_SEED 0xFFFF // 该位称为预置值,使用人工算法(长除法)时 需要将除数多项式先与该与职位 异或 ,才能得到最后的除数多项式
#define POLY16 0x1021 // 该位为简式书写 实际为0x11021
INT16U crc16(unsigned char *buf,unsigned short length)
{
INT16U shift,data,val;
int i;
shift = CRC_SEED;
for(i=0;i<length;i++) {
if((i % 8) == 0)
data = (*buf++)<<8;
val = shift ^ data;
shift = shift<<1;
data = data <<1;
if(val&0x8000)
shift = shift ^ POLY16;
}
return shift;
}
2、查表法
static unsigned short ccitt_table[256] = {
0x0000, 0x1021, 0x2042, 0x3063, 0x4084, 0x50A5, 0x60C6, 0x70E7,
0x8108, 0x9129, 0xA14A, 0xB16B, 0xC18C, 0xD1AD, 0xE1CE, 0xF1EF,
0x1231, 0x0210, 0x3273, 0x2252, 0x52B5, 0x4294, 0x72F7, 0x62D6,
0x9339, 0x8318, 0xB37B, 0xA35A, 0xD3BD, 0xC39C, 0xF3FF, 0xE3DE,
0x2462, 0x3443, 0x0420, 0x1401, 0x64E6, 0x74C7, 0x44A4, 0x5485,
0xA56A, 0xB54B, 0x8528, 0x9509, 0xE5EE, 0xF5CF, 0xC5AC, 0xD58D,
0x3653, 0x2672, 0x1611, 0x0630, 0x76D7, 0x66F6, 0x5695, 0x46B4,
0xB75B, 0xA77A, 0x9719, 0x8738, 0xF7DF, 0xE7FE, 0xD79D, 0xC7BC,
0x48C4, 0x58E5, 0x6886, 0x78A7, 0x0840, 0x1861, 0x2802, 0x3823,
0xC9CC, 0xD9ED, 0xE98E, 0xF9AF, 0x8948, 0x9969, 0xA90A, 0xB92B,
0x5AF5, 0x4AD4, 0x7AB7, 0x6A96, 0x1A71, 0x0A50, 0x3A33, 0x2A12,
0xDBFD, 0xCBDC, 0xFBBF, 0xEB9E, 0x9B79, 0x8B58, 0xBB3B, 0xAB1A,
0x6CA6, 0x7C87, 0x4CE4, 0x5CC5, 0x2C22, 0x3C03, 0x0C60, 0x1C41,
0xEDAE, 0xFD8F, 0xCDEC, 0xDDCD, 0xAD2A, 0xBD0B, 0x8D68, 0x9D49,
0x7E97, 0x6EB6, 0x5ED5, 0x4EF4, 0x3E13, 0x2E32, 0x1E51, 0x0E70,
0xFF9F, 0xEFBE, 0xDFDD, 0xCFFC, 0xBF1B, 0xAF3A, 0x9F59, 0x8F78,
0x9188, 0x81A9, 0xB1CA, 0xA1EB, 0xD10C, 0xC12D, 0xF14E, 0xE16F,
0x1080, 0x00A1, 0x30C2, 0x20E3, 0x5004, 0x4025, 0x7046, 0x6067,
0x83B9, 0x9398, 0xA3FB, 0xB3DA, 0xC33D, 0xD31C, 0xE37F, 0xF35E,
0x02B1, 0x1290, 0x22F3, 0x32D2, 0x4235, 0x5214, 0x6277, 0x7256,
0xB5EA, 0xA5CB, 0x95A8, 0x8589, 0xF56E, 0xE54F, 0xD52C, 0xC50D,
0x34E2, 0x24C3, 0x14A0, 0x0481, 0x7466, 0x6447, 0x5424, 0x4405,
0xA7DB, 0xB7FA, 0x8799, 0x97B8, 0xE75F, 0xF77E, 0xC71D, 0xD73C,
0x26D3, 0x36F2, 0x0691, 0x16B0, 0x6657, 0x7676, 0x4615, 0x5634,
0xD94C, 0xC96D, 0xF90E, 0xE92F, 0x99C8, 0x89E9, 0xB98A, 0xA9AB,
0x5844, 0x4865, 0x7806, 0x6827, 0x18C0, 0x08E1, 0x3882, 0x28A3,
0xCB7D, 0xDB5C, 0xEB3F, 0xFB1E, 0x8BF9, 0x9BD8, 0xABBB, 0xBB9A,
0x4A75, 0x5A54, 0x6A37, 0x7A16, 0x0AF1, 0x1AD0, 0x2AB3, 0x3A92,
0xFD2E, 0xED0F, 0xDD6C, 0xCD4D, 0xBDAA, 0xAD8B, 0x9DE8, 0x8DC9,
0x7C26, 0x6C07, 0x5C64, 0x4C45, 0x3CA2, 0x2C83, 0x1CE0, 0x0CC1,
0xEF1F, 0xFF3E, 0xCF5D, 0xDF7C, 0xAF9B, 0xBFBA, 0x8FD9, 0x9FF8,
0x6E17, 0x7E36, 0x4E55, 0x5E74, 0x2E93, 0x3EB2, 0x0ED1, 0x1EF0
};
unsigned short crc_ccitt(unsigned char *q, int len)
{
unsigned short crc = 0;
while (len-- > 0)
crc = ccitt_table[(crc >> 8 ^ *q++) & 0xff] ^ (crc << 8);
return ~crc
}