1.TCP 提供一种面向连接的、可靠的字节流服务
2.在一个 TCP 连接中,仅有两方进行彼此通信。广播和多播不能用于 TCP
3.TCP 使用校验和,确认和重传机制来保证可靠传输
4.TCP 给数据分节进行排序,并使用累积确认保证数据的顺序不变和非重复
5.TCP 使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制
头部信息
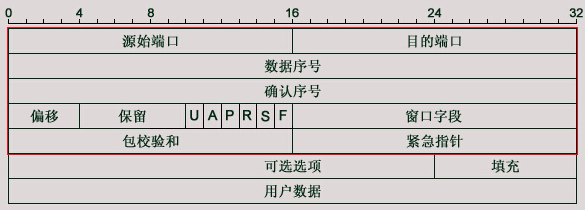
三次握手
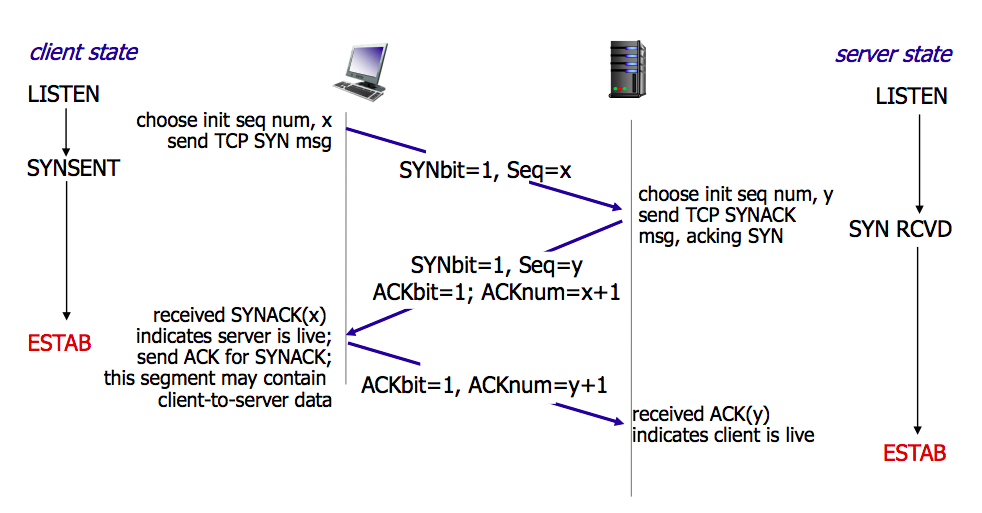
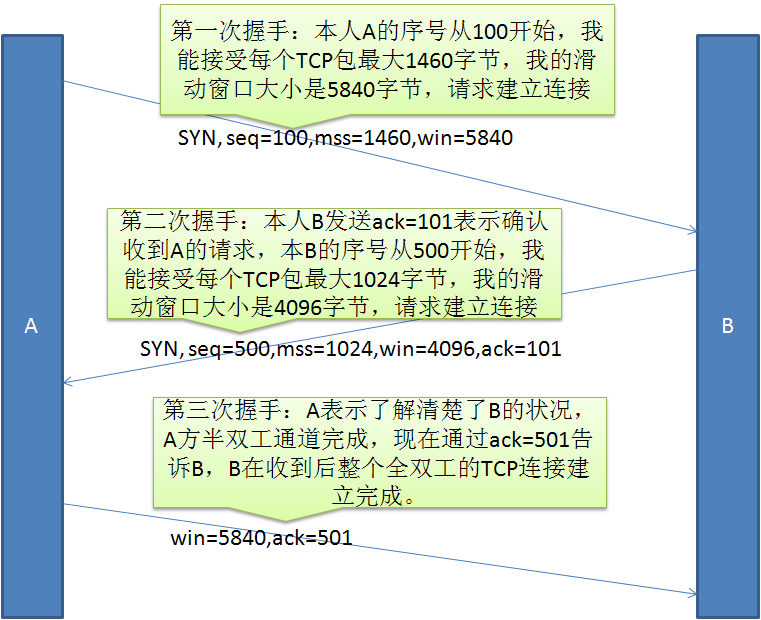
四次挥手


滑动窗口协议:

TCP 主要通过四种算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
为了便于讨论,做如下假设:
- 接收方有足够大的接收缓存,因此不会发生流量控制;
- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。

1. 慢开始与拥塞避免
发送的最初执行慢开始,令 cwnd=1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
如果出现了超时,则令 ssthresh = cwnd/2,然后重新执行慢开始。
2. 快重传与快恢复
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2的确认。
在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd/2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
TCP中的四个计时器包括重传计时器、坚持计时器、保活计时器、时间等待计时器
URG(紧急位):设置为1时,首部中的紧急指针有效;为0时,紧急指针没有意义。
PSH(推位):当设置为1时,要求把数据尽快的交给应用层,不做处理
通常的数据中都会带有PSH但URG只在紧急数据的时设置,也称“带外数据”,解释如下:
紧急数据:URG标志设置为1时,紧急指针才有效,紧急方式是向对方发送紧急数据的一种方式,表示数据要优先处理。他是一个正的偏移量,与TCP收不中序号字段的值相加表示紧急数据后面的字节,即紧急指针是指向紧急数据最后一个字节的下一个字节。这是协议编写上的错误,RFC1122中对此给出了更正说明,紧急指针是数据最后一个字节,不是最后字节的下一位置,TCP首部中只有紧急指针指出紧急数据的位置,他所指的字节为紧急数据,但没有办法指定紧急数据的长度。
URG=1,表示紧急指针指向包内数据段的某个字节(数据从第一字节到指针所指向字节就是紧急数据)不进入缓冲区(一般不都是待发送的数据要先进入发送缓存吗?就直接交个上层进程,余下的数据都是要进入接收缓冲的;一般来说TCP是要等到整个缓存都填满了后在向上交付,但是如果PSH=1的话,就不用等到整个缓存都填满,直接交付,但是这里的交付仍然是从缓冲区交付的,URG是不要经过缓冲区的
RST表示复位,用来异常的关闭连接,在TCP的设计中它是不可或缺的。就像上面说的一样,发送RST包关闭连接时,不必等缓冲区的包都发出去(不像上面的FIN包),直接就丢弃缓存区的包发送RST包。而接收端收到RST包后,也不必发送ACK包来确认。
TCP处理程序会在自己认为的异常时刻发送RST包。例如,A向B发起连接,但B之上并未监听相应的端口,这时B操作系统上的TCP处理程序会发RST包。
又比如,AB正常建立连接了,正在通讯时,A向B发送了FIN包要求关连接,B发送ACK后,网断了,A通过若干原因放弃了这个连接(例如进程重启)。网通了后,B又开始发数据包,A收到后表示压力很大,不知道这野连接哪来的,就发了个RST包强制把连接关了,B收到后会出现connect reset by peer错误。
首先,把伪首部、TCP报头、TCP数据分为16位的字,如果总长度为奇数个字节,则在最后增添一个位都为0的字节。把TCP报头中的校验和字段置为0(否则就陷入鸡生蛋还是蛋生鸡的问题)。
其次,用反码相加法累加所有的16位字(进位也要累加)。
最后,对计算结果取反,作为TCP的校验和
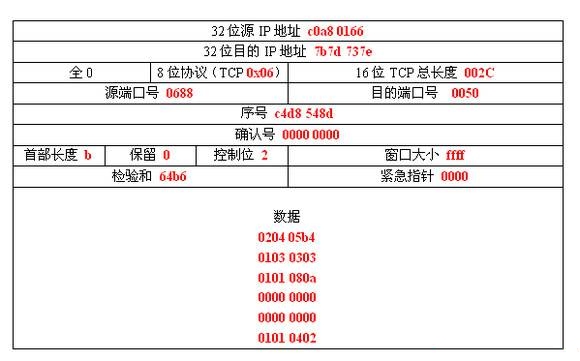
1、首先将检验和置零;
2、然后将TCP伪首部部分,TCP首部部分,数据部分都划分成16位的一个个16进制数
3、将这些数逐个相加,记得溢出的部分加到最低位上,这是循环加法:
0xc0a8+ 0x0166+……+0x0402=0x9b49
4、最后将得到的结果取反,则可以得到检验和位0x64b6
发送方:原码相加 ,并将高位叠加到低位,取反 ,得到反码求和结果,放入校验和
接收方:将所有原码 相加,高位叠加, 如全为1,则正确
