简介
本书是集体智慧编程一书的学习笔记。
1
之前我们已经完成了基于用户的协同过滤的推荐算法,它的思想是将所有的用户和自己对比,显然对于小数据集还是可以忍受的,但是对于大量或巨量的用户数据集,这种实时进行相似度计算即耗时又耗力。
有没有更好的计算方法呢?有,就是我们不再基于用户,我们基于物品。基于用户的时候,来了一个人,就同剩下的全部人比较,实时运算伤不起。基于物品的时候,来了一个人,我们就看他最近看过什么或买过什么(物品),我们计算该物品同剩下的其它全部物品进行相似度比较,找出相似度高的推荐给他。
这里你又会说,这不是一样要实时运算吗。其实不然,我们可以提前就计算好每个物品和它相似度高的物品,仓库里的每个物品都这样算一遍,把结果存储起来。来了个人的时候,我们根据它买过看过的物品,在存储的数据里调用这些买过看过物品相似度高的物品(已经计算过)推荐给他就好了。这样不就好了。
数据集和相似度准则
同基于用户的协同过滤
#基于物品的推荐 critics={ 'Lisa Rose':{'lady in water':2.5,'snakes on a plane':3.5,'just my luck':3.0,'superman returns':3.5,'you,me and dupree':2.5,'the night listener':3.0}, 'Gene Seymour':{'lady in water':3.0,'snakes on a plane':3.5,'just my luck':1.5,'superman returns':5.0,'you,me and dupree':3.5,'the night listener':3.0}, 'Michael Phillips':{'lady in water':2.5,'snakes on a plane':3.0,'superman returns':3.5,'the night listener':4.0}, 'Claudia Puig':{'snakes on a plane':3.5,'just my luck':3.0,'superman returns':4.0,'the night listener':4.5}, 'Mick Lasalle':{'lady in water':3.0,'snakes on a plane':4.0,'just my luck':2.0,'superman returns':3.0,'you,me and dupree':2.0,'the night listener':3.0}, 'Jack Matthews':{'lady in water':3.0,'snakes on a plane':4.0,'superman returns':5.0,'you,me and dupree':3.5,'the night listener':3.0}, 'Toby':{'snakes on a plane':4.5,'superman returns':4.0,'you,me and dupree':1.0}} from math import sqrt #欧几里德距离 def sim_distance(prefs,p1,p2): si={} # find common items for item in prefs[p1]: if item in prefs[p2]: si[item]=1 if len(si)==0: return 0 #cal the distance sum_of_sqr=sum([pow(prefs[p1][item]-prefs[p2][item],2) for item in si]) return 1/(1+sqrt(sum_of_sqr)) #皮尔逊相关度 def sim_pearson(prefs,p1,p2): si={} for item in prefs[p1]: if item in prefs[p2]: si[item]=1 if len(si)==0: return 0 sum1=sum([prefs[p1][item] for item in si]) sum2=sum([prefs[p2][item] for item in si]) sum1sq=sum([pow(prefs[p1][item],2) for item in si]) sum2sq=sum([pow(prefs[p2][item],2) for item in si]) psum=sum([prefs[p1][item]*prefs[p2][item] for item in si]) num=psum-sum1*sum2/len(si) den=sqrt((sum1sq-pow(sum1,2)/len(si))*(sum2sq-pow(sum2, 2)/len(si))) if den==0: return 0 return num/den
基于用户——>基于物品
可以代码复用,只需要将人和物品对调即可
#物品与人员互相调换 def transformprefs(prefs): result={} for person in prefs: for item in prefs[person]: result.setdefault(item,{}) # 人、物对调 result[item][person]=prefs[person][item] return result #最相关的N个person,这里仅仅是函数定义,实际传入参数为物品 def topmatchs(prefs,person,n=5,similarity=sim_pearson): scores=[(similarity(prefs,person,other),other) for other in prefs if other!=person] scores.sort(reverse=True) return scores[0:n] #构建物品比较数据集合,即,每个item有n个最相关的其它item def calculatesimilaryitems(prefs,n=10): itemsim={} itemprefs=transformprefs(prefs) c=0 for item in itemprefs: c+=1.0 if c%100==0:print('%d/%d' %(c,len(itemprefs))) scores=topmatchs(itemprefs,item,n=n,similarity=sim_pearson) itemsim[item]=scores return itemsim
获得推荐
以上部分可以单独提前运行,并存储结果。现在来了一个用户,它有若干买过或看过的物品,我们调用存储的数据库,找到与他买过看过的物品有很高相关度的物品。
例如:我们看过Snake,Superman,Dupree,并有我们给的评分。基于我们看过的这三个电影,查找存储数据库,找到与每个电影(Snake,Superman,Dupree)的相似度高的其它所有或部分排名靠前的相关电影,这里是Night,Lady,Luck。
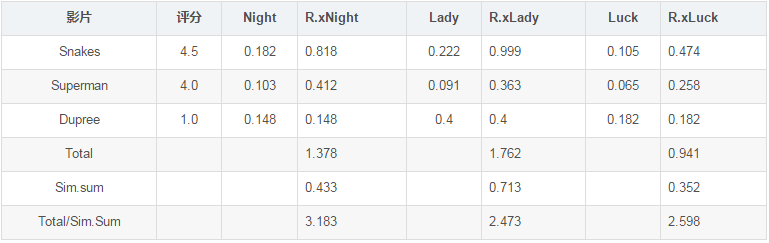

#来了个新用户,获得推荐 def getrecommendations(prefs,itemsim,user): totalsim={} simsum={} for item,ratio in prefs[user].items(): for similarity,item2 in itemsim[item]: if item2 in prefs[user]: continue totalsim.setdefault(item2,0) totalsim[item2]+=similarity*ratio simsum.setdefault(item2,0) simsum[item2]+=similarity rankings=[(total/simsum[item],item) for item ,total in totalsim.items()] rankings.sort(reverse=True) return rankings
总结
