ElasticSearch如何更新集群的状态
最近发生了很多事情,甚至对自己的技术能力和学习方式产生了怀疑,所以有一段时间没更新文章了,估计以后更新的频率会越来越少,希望有更多的沉淀而不是简单地分享。让我有感悟的是,最近看到一篇关于ES集群状态更新的文章Elasticsearch Distributed Consistency Principles Analysis (2) - Meta,和 “提交给线程池的Runnable任务是以怎样的顺序执行的?”这个问题,因此,结合ES6.3.2源码,分析一下ES的Master节点是如何更新集群状态的。
分布式系统的集群状态一般是指各种元数据信息,通俗地讲,在ES中创建了一个Index,这个Index的Mapping结构信息、Index由几个分片组成,这些分片分布在哪些节点上,这样的信息就组成了集群的状态。当Client创建一个新索引、或者删除一个索、或者进行快照备份、或者集群又进行了一次Master选举,这些都会导致集群状态的变化。概括一下就是:发生了某个事件,导致集群状态发生了变化,产生了新集群状态后,如何将新的状态应用到各个节点上去,并且保证一致性。
在ES中,各个模块发生一些事件,会导致集群状态变化,并由org.elasticsearch.cluster.service.ClusterService#submitStateUpdateTask(java.lang.String, T)提交集群状态变化更新任务。当任务执行完成时,就产生了新的集群状态,然后通过"二阶段提交协议"将新的集群状态应用到各个节点上。这里可大概了解一下有哪些模块的操作会提交一个更新任务,比如:
- MetaDataDeleteIndexService#deleteIndices 删除索引
- org.elasticsearch.snapshots.SnapshotsService#createSnapshot 创建快照
- org.elasticsearch.cluster.metadata.MetaDataIndexTemplateService#putTemplate 创建索引模板
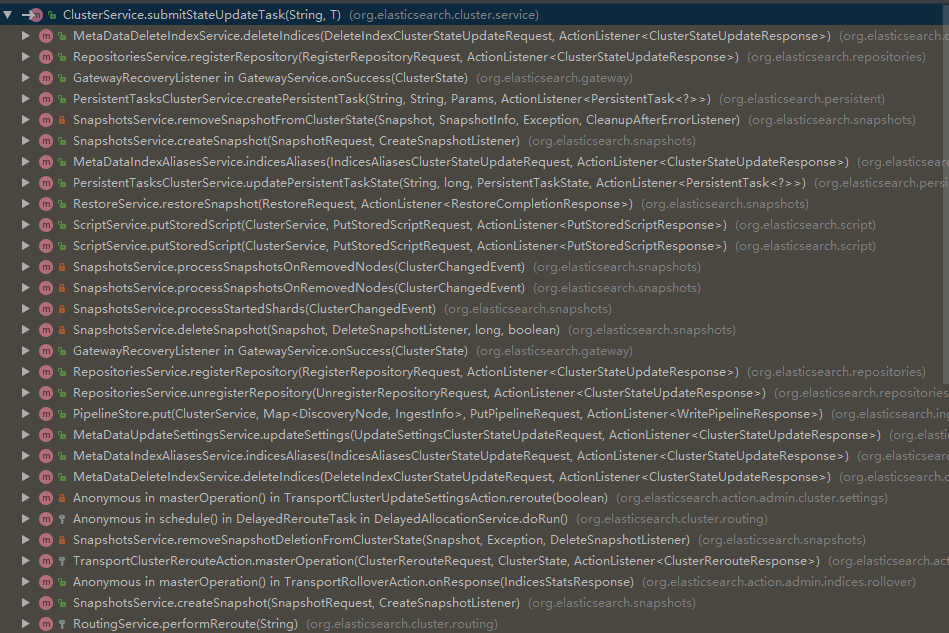
因此各个Service(比如:MetaDataIndexTemplateService)都持有org.elasticsearch.cluster.service.ClusterService实例引用,通过ClusterService#submitStateUpdateTask方法提交更新集群状态的任务。
既然创建新索引、删除索引、修改索引模板、创建快照等都会触发集群状态更新,那么如何保证这些更新操作是"安全"的?比如操作A是删除索引,操作B是对索引做快照备份,操作A、B的顺序不当,就会引发错误!比如,索引都已经删除了,那还怎么做快照?因此,为了防止这种并发操作对集群状态更新的影响,org.elasticsearch.cluster.service.MasterService中采用单线程执行方式提交更新集群状态的任务。状态更新任务由org.elasticsearch.cluster.service.MasterService.Batcher.UpdateTask表示,它本质上是一个具有优先级特征的Runnable任务:
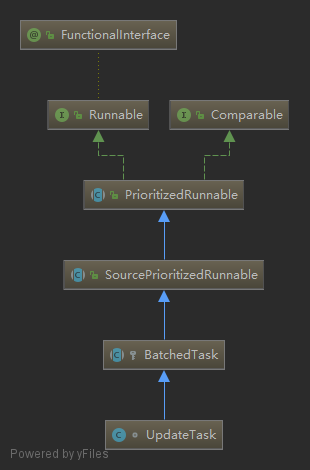
//PrioritizedRunnable 实现了Comparable接口,compareTo方法比较任务的优先级
public abstract class PrioritizedRunnable implements Runnable, Comparable<PrioritizedRunnable> {
private final Priority priority;//Runnable任务优先级
private final long creationDate;
private final LongSupplier relativeTimeProvider;
@Override
public int compareTo(PrioritizedRunnable pr) {
return priority.compareTo(pr.priority);
}
}
而单线程的执行方式,则是通过org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor线程池实现的。看org.elasticsearch.common.util.concurrent.EsExecutors#newSinglePrioritizing线程池的创建:
public static PrioritizedEsThreadPoolExecutor newSinglePrioritizing(String name, ThreadFactory threadFactory, ThreadContext contextHolder, ScheduledExecutorService timer) {
//core pool size == max pool size ==1,说明该线程池里面只有一个工作线程
return new PrioritizedEsThreadPoolExecutor(name, 1, 1, 0L, TimeUnit.MILLISECONDS, threadFactory, contextHolder, timer);
}
而线程池的任务队列则是采用:PriorityBlockingQueue(底层是个数组,数据结构是:堆 Heap),通过compareTo方法比较Priority,从而决定任务的排队顺序。
//PrioritizedEsThreadPoolExecutor#PrioritizedEsThreadPoolExecutor
PrioritizedEsThreadPoolExecutor(String name, int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,ThreadFactory threadFactory, ThreadContext contextHolder, ScheduledExecutorService timer) {
super(name, corePoolSize, maximumPoolSize, keepAliveTime, unit, new PriorityBlockingQueue<>(), threadFactory, contextHolder);
this.timer = timer;
}
这里想提一下这种只采用一个线程执行任务状态更新的思路,它与Redis采用单线程执行Client的操作命令是一致的。各个Redis Client向Redis Server发起操作请求,Redis Server最终是以一个线程来"顺序地"执行各个命令。单线程执行方式,避免了数据并发操作导致的不一致性,并且不需要线程同步。毕竟同步一般是通过加锁来实现的,而加锁会影响程序性能。
在这里,我想插一个问题:JDK线程池执行任务的顺序是怎样的?通过java.util.concurrent.ThreadPoolExecutor#execute方法先提交到线程池中的任务,一定会优先执行吗?这个问题经常被人问到,哈哈。但是,真正地理解,却不容易。因为它涉及到线程池参数,core pool size、max pool size 、任务队列的长度以及任务到来的时机。其实JDK源码中的注释已经讲得很清楚了:
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
- 任务提交到线程池,如果线程池的活跃线程数量小于 core pool size,那么直接创建新线程执行任务,这种情况下任务是不会入队列的。
- 当线程池中的活跃线程数量已经达到core pool size时,继续提交任务,这时的任务就会入队列排队。
- 当任务队列已经满了时,同时又有新任务提交过来,如果线程池的活跃线程数小于 max pool size,那么会创建新的线程,执行这些刚提交过来的任务,此时的任务也不会入队列排队。(注意:这里新创建的线程并不是从任务队列中取任务,而是直接执行刚刚提交过来的任务,而那些前面已经提交了的在任务队列中排队的任务反而不能优先执行,换句话说:任务的执行顺序并不是严格按提交顺序来执行的)
代码验证一下如下,会发现:如果 cool pore size 不等于 max pool size,那么后提交的任务,反而可能先开始执行。因为,先提交的任务在队列中排队,而后提交的任务直接被新创建的线程执行了,省去了排队过程。(这里为了方便看结果,每个任务的所需要的执行时间都是相同的,即1s钟)
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
/**
* @author psj
* @date 2019/11/14
*/
public class ThreadPoolTest {
public static void main(String[] args) throws InterruptedException{
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("test-%d").build();
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(4);
ThreadPoolExecutor executorSevice = new ThreadPoolExecutor(1, 4, 0, TimeUnit.HOURS,
workQueue, threadFactory, new ThreadPoolExecutor.DiscardPolicy());
for (int i = 1; i <=8; i++) {
MyRunnable task = new MyRunnable(i, workQueue);
executorSevice.execute(task);
sleepMills(200);
System.out.println("submit: " + i + ", queue size:" + workQueue.size() + ", active count:" + executorSevice.getActiveCount());
}
Thread.currentThread().join();
}
public static class MyRunnable implements Runnable {
private int sequence;
private BlockingQueue taskQueue;
public MyRunnable(int sequence, BlockingQueue taskQueue) {
this.sequence = sequence;
this.taskQueue = taskQueue;
}
@Override
public void run() {
//模拟任务需要1秒钟才能执行完成
sleepMills(1000);
System.out.println("task :" + sequence + " finished, current queue size:" + taskQueue.size());
}
}
public static void sleepMills(int mills) {
try {
TimeUnit.MILLISECONDS.sleep(mills);
} catch (InterruptedException e) {
}
}
}
当提交第7个任务时,此时任务队列size为4,已经满了。因此,继续创建新线程(因为此时活跃线程数小于max pool size)执行第7个任务,也可以发现:第7个任务比那些在队列中排队的任务(比如第2、3、4个任务)要早执行完成,这是因为第7个任务没有入队列排队,而是直接创建新线程执行它。
submit: 1, queue size:0, active count:1
submit: 2, queue size:1, active count:1
submit: 3, queue size:2, active count:1
submit: 4, queue size:3, active count:1
task :1 finished, current queue size:4
submit: 5, queue size:3, active count:1
submit: 6, queue size:4, active count:1
submit: 7, queue size:4, active count:2
submit: 8, queue size:4, active count:3
task :2 finished, current queue size:4
task :7 finished, current queue size:3
task :8 finished, current queue size:2
task :3 finished, current queue size:1
task :4 finished, current queue size:0
task :5 finished, current queue size:0
task :6 finished, current queue size:0
那么,有什么办法,能够保证先提交的任务,一定先执行吗?还是有的:那就是将线程池的核心线程数core pool size设置成 max pool size 一样大。
但是在现实应用中,有些任务很复杂,有些任务很简单,因此 “每个任务所需要的执行完成的时间完全相等 几乎是不可能的”,当线程池的 core pool size等于max pool size 能保证:先提交的任务,先被线程池执行,但是先提交的任务,不一定先执行完成,这是要注意的。
为什么当core pool size 等于 max pool size时,先提交的任务,就一定会先执行呢?
这是因为:任务提交过来,先通过 addWorker 创建新线程执行任务,由于core ppol size 等于 max pool size,那么addWorker会首先创建到 max pool size个线程数,再有任务提交过来,就会入队列排队,当某个线程上的任务执行完成时,这个线程是在一个while 循环里面 去取任务队列里面排队的任务,源码如下:java.util.concurrent.ThreadPoolExecutor#runWorker
try {
//如果线程刚才执行完了一个task,该task==null, 这时 while 循环 中 getTask()方法执行,从任务队列里面取任务执行
while (task != null || (task = getTask()) != null) {
//省略其他代码...
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();// 这里会执行我们实现的run方法
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;//任务执行完成置成null,这样while循环的条件就会调用 getTask()从任务队列里面取新任务执行
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
OK,分析完了线程池执行任务的顺序,再看看ES的PrioritizedEsThreadPoolExecutor线程池的参数:将 core pool size 和 max pool size 都设置成1,避免了这种"插队"的现象,即能够保证:先提交的任务,一定是先执行完成的。各个模块触发的集群状态更新最终在org.elasticsearch.cluster.service.MasterService#submitStateUpdateTasks方法中构造UpdateTask对象实例,并通过submitTasks方法提交任务执行。额外需要注意的是:集群状态更新任务可以以批量执行方式提交,具体看org.elasticsearch.cluster.service.TaskBatcher的实现吧。
try {
List<Batcher.UpdateTask> safeTasks = tasks.entrySet().stream()
.map(e -> taskBatcher.new UpdateTask(config.priority(), source, e.getKey(), safe(e.getValue()), executor))
.collect(Collectors.toList());
taskBatcher.submitTasks(safeTasks, config.timeout());
} catch (EsRejectedExecutionException e) {
// ignore cases where we are shutting down..., there is really nothing interesting
// to be done here...
if (!lifecycle.stoppedOrClosed()) {
throw e;
}
}
最后来分析一下 org.elasticsearch.cluster.service.ClusterService类,在ES节点启动的时候,在Node#start()方法中会启动ClusterService,当其它各个模块执行一些操作触发集群状态改变时,就是通过ClusterService来提交集群状态更新任务。而ClusterService其实就是封装了 MasterService和ClusterApplierService,MasterService提供任务提交接口,内部维护一个线程池处理更新任务,而ClusterApplierService则负责通知各个模块应用新生成的集群状态。
总结
- 只有单个线程的线程池执行任务,能够保证任务处理的顺序性,又不需要通过加锁实现数据同步,这种思路值得借鉴
- 如果想保证:先提交的任务要先执行,那么 max pool size 必须 等于 core pool size
- 如果 max pool size 不等于 core pool size,那么先提交的任务,可能在任务队列中排队,当任务队列满了时,后提交过来的任务直接通过 addWorker新建一个线程执行,从而使得后提交的任务先执行了(但并不是后提交的任务先执行完成,因为每个任务的复杂度不一样)
- 如果想保证:先提交的任务先执行完成,那么 max pool size 必须 等于 core pool size 并且等于1。这就是ES的PrioritizedEsThreadPoolExecutor线程池所采用的方式,它能保证ES集群的任务更新状态是有序的。