传统的TP库难以应对AP的需求
如果要应对AP的需求,
现在有几种做法,
列存,列存可以降低数据传输量,而且让压缩更有效

NewSql,Hybrid TP/AP,一般都是内存数据库

离线数据库,Hive,Presto,Spark,无论快慢,它自己本身不存储数据的,只是一个执行引擎和查询引擎

预聚合cube,直接查询结果,问题是牺牲flexibility,而且不是什么数据都可以聚合
典型的系统kylin

最后一种,Pinot和druid
称为,异步实时消费分析库,
其实说白了,是实时数仓的简化版本,因为他依赖实时消息队列来接clients发来的数据,然后实时的消费队列的数据构建索引
这样做的好处,架构简单,接实时流量是个很麻烦的工作,保障高可用,数据还不能丢;
关键,这样可以批量load,因为对于建索引,或Pinot号称Cloud-friendly,最关键的是你不能一条条load,否则性能肯定跟不上;这里很难设计,自己buffer,如果先返回会丢数据,不返回client等超时;现在有了个实时队列,完美解
这种架构的坏处,异步意味着不是实时可见,队列里面的数据是不可查询的

那么Pinot说他比druid好的地方,就是对于简单查询,可以接受很高的qps
架构
数据模型上,
有Table,固定schema,
Table由segments组成,replicated,immutable,columnar的,大同小异

模块上,分成Controller,Broker,Server,MInion

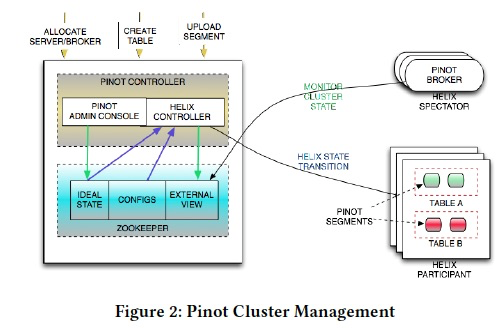
Server,用来放Segments和处理查询,真正的worker

Controller控制节点,最关键的是要记录下segments和servers之间的对应关系;当然可以做一系列的管控操作,listing,add,delete segment
metadata是存在ZK上,各个组件和segment的状态是由Helix来管理

Broker,就是router,把query发到合适的server上,merge结果返回

Minion,任务流管理,比如进行数据过期

Zookeeper
保存所有的状态和meta,和节点间的信息交互,上一个看到这么干的是storm

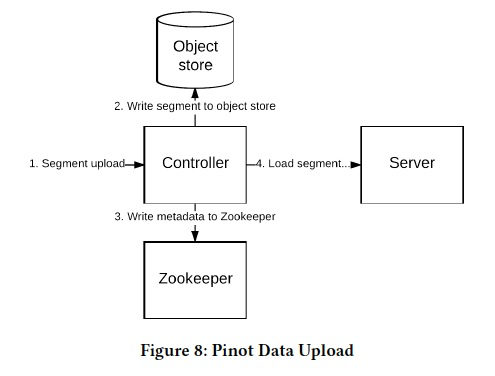
UpLoad和Load过程,
Segment进入系统,需要upload,Upload通过Controller,把meta和data分别存到Zk和Object Store上
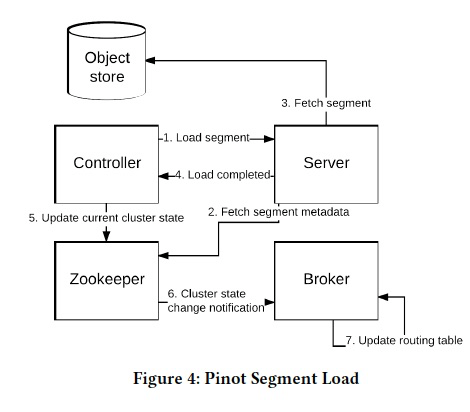
然后开始Load Segment,这里有个问题,如果选择Server来加载这个segment,他后面搞了一章来水这个问题,其实就是随机贪婪算法,脑补一下就可以
选好server,server会去download meta和data,完成后通知Controller,把这个segment加入Broker的路由
这时这个Segment的状态就变成Online,这个系统的对象的状态管理都是依赖Helix,简单的理解就是一个,分布式状态机框架,你可以定义状态和desire 状态,以及转移的函数,然后Helix会保证尽量让集群称为你想要的desire state
查询,
首先他的查询是可以Partial的,这个有些意思,如果部分查询失败了,还是会返回给用户,用户可以凑合看看,也可以重发查询

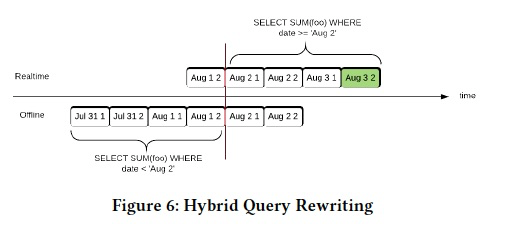
Piont可以支持,lambda架构,好久没有听到这个名词了,尤其是linkedin发表的论文,异样的感觉
Pinot可以建立Hybrid表,查询的时候会自动merge,overlap的部分数据


副本建立,各个副本是独立从kafka消费和构建的,通过offset来保证各个副本数据一致
后面说了一堆,如果发生不一致,他提供了一堆命令去同步各个副本的状态,感觉简单问题复杂化了

前面也说了,之所以能cloud friendly,是因为他做的事情本来就简单
前面依赖了消息队列

这论文最大的价值,related work写的还不错,然后引入Helix进行集群管理