第一步:
创建一个Html5文件:
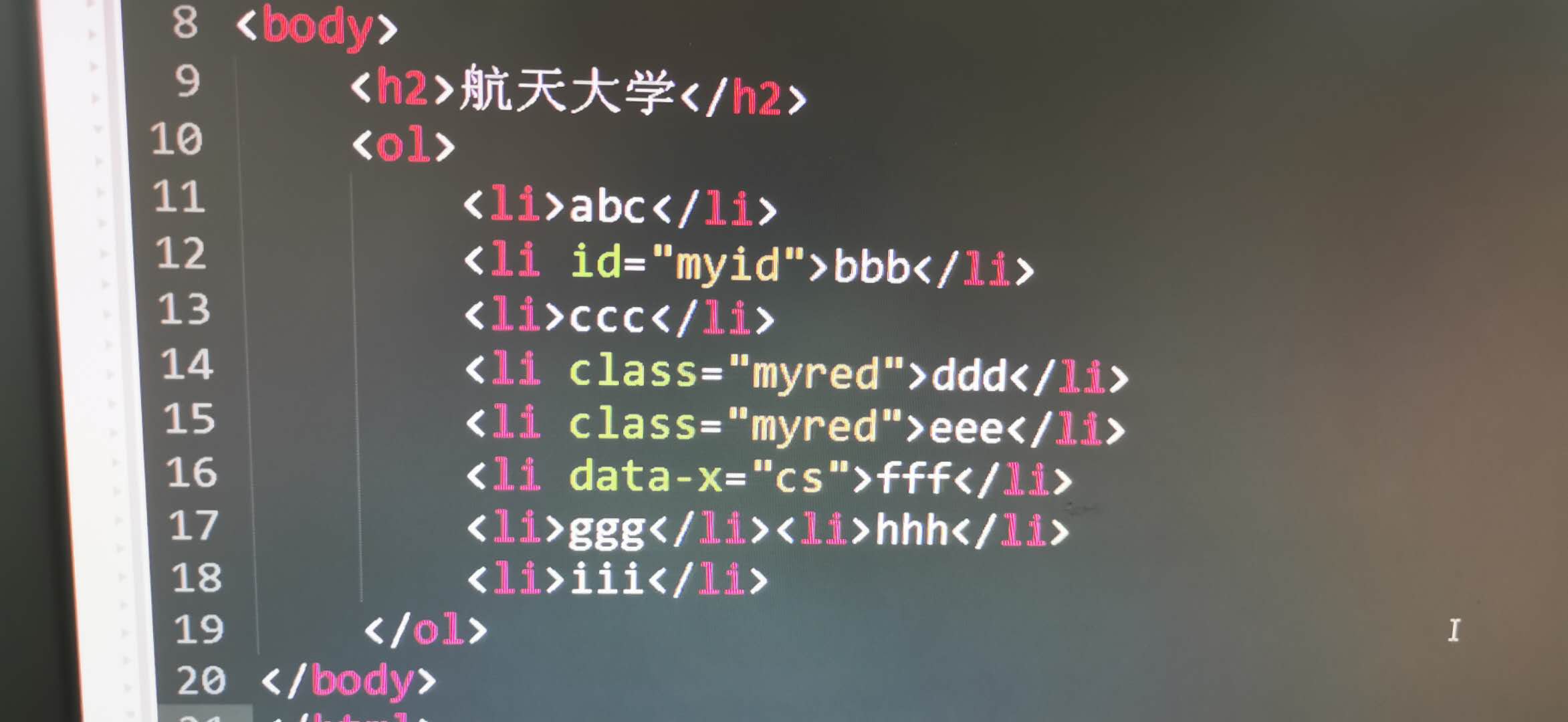
第二步:
代码如下:
import re from bs4 import BeautifulSoup htmlDoc='''<!DOCTYPE html><html><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><title>标题</title><link rel="stylesheet" href=""></head><body><h2>航天大学</h2><ol><li>abc</li><li id="myid">bbb</li><li>ccc</li><li class="myred">ddd</li><li class="myred">eee</li><li data-x="cs">fff</li><li>ggg</li><li>hhh</li><li>iii</li></ol></body></html>''' soup = BeautifulSoup(htmlDoc, "html.parser") print(soup.prettify()) print(soup.find_all(re.compile("^me"))) print(soup.find_all(attrs={"data-x":'cs'})) print(soup.find(id="myid")) print(soup.find_all(class_="myred")) print(soup.find_all(text="ccc")) lis=soup.find_all("li") for li in lis: print(li.string)