本篇博文是我结合《深入理解OpenCV》 和 CSDN 大佬 taotao123 的博文整理所得。由于本科毕业设计要做人脸识别算法方面的研究,现在才刚开始看,很多地方尤其是公式还看不大懂。
本章所说的非刚性是指脸部特征间的相对距离会随着面部表情和人群的不同而变化,这也是它与人脸检测和跟踪的不同之处,人脸检测和跟踪只是为了找到每帧视频中人脸位置,而不是面部特征结构。
该系统涉及的内容如下:
下面的框图说明各个部分之间的关系:
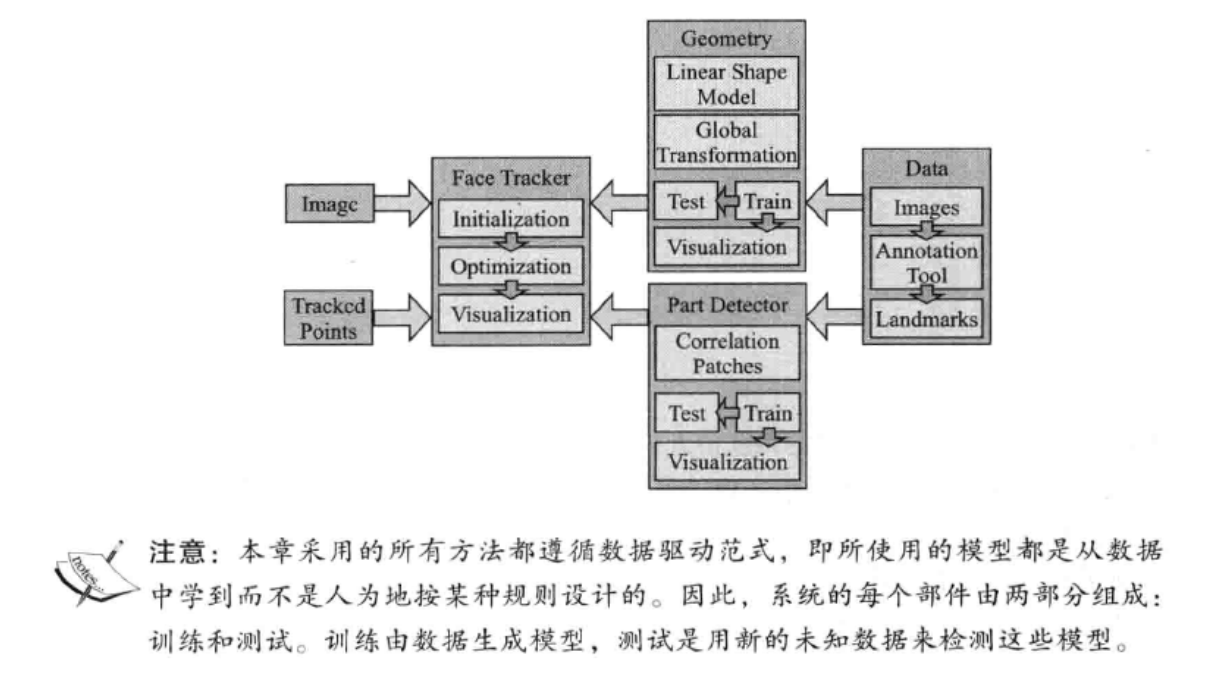
总结:
一、梳理下本章我们训练了哪些数据特征,并且训练它们的目的是什么。
1. ft_data:利用手工标注工具,获取最原始的样本训练数据,包括以下内容:
-
- 图像名称集合 imnames :表明在哪副图像上标注特征点;
- 二维坐标集合 points :手工标注点,后续更高级别特征均围绕这些特征点展开;
- 对称坐标索引集合 symmetry :标注样本图像的镜像图像上的特征点,扩大样本库;
- 连接索引集合 connections :描述手工标注的人脸特征点之间的几何约束及相对位置。
- 图像名称集合 imnames :表明在哪副图像上标注特征点;
设计主要技术:如何利用 openCV 序列化存储“类”的结构数据
2. shape_model:由于人脸的高度结构化特征对局部形变产生了极大的约束,因此我们需要提取一种特征来描述手工标注点集与人脸器官在几何空间上的对应关系。这种关系包括全局形变(人脸平移、缩放、旋转)和局部形变(描述不同人、不同表情之间脸部形状的不同)。这种特征的训练结果包含以下内容:
-
- 参数向量 p:在手工标注的特征点集被投影到人脸子空间(之前被称作联合分布空间)前,需要设置被投影点集在子空间的缩放比例、旋转角度、还有投影的范围;
- 子空间标准基 V:描述人脸模型的联合投影矩阵,包括 k 个局部形变参数(表情模型)和 4 个全局形变参数,用于将图像标注点投影到人脸特征子区间;
- 参数变化向量 e:手工标注点投影到人脸特征子空间后得到坐标集合的标准差,由于投影本身会导致人脸特征的失真,所以用该标准差作为阈值,修正失真 clamp 函数;
- 连接矩阵 C:描述之前标注的连接关系矩阵,沿用 ft_data 中的连接索引集合,并未做其他操作
- 参数向量 p:在手工标注的特征点集被投影到人脸子空间(之前被称作联合分布空间)前,需要设置被投影点集在子空间的缩放比例、旋转角度、还有投影的范围;
我们训练该特征,就是为了得到样本图像的标注点投影到人脸特征子空间的投影矩阵。另外,该投影矩阵内的 k 个局部形变参数代表 k 个表情,一次投影将产生 k 组子空间坐标。
涉及主要技术:奇异值分解、Procrustes Analysis、求施密特正交矩阵
3. patch_model:团块特征模型,即人脸每个部位的特征图像。团块特征的训练结果包含如下内容:
-
- 参考形状矩阵 reference:通过人工指定参数向量 p,在人脸子空间产生 k 种投影的坐标集合。由于图像的全局几何约束,为了提取更好的团块模型,我们需要求人工标注点到该矩阵 reference 的仿射变化矩阵(calc_simil 函数完成),从而对样本图像也进行相应的仿射变化;
- 团块矩阵 P:它是一种归一化的图像,代表当前特征点附近的图像特征
在人脸跟踪时,需要对人脸不同部位各自的描述信息,以便与对每个特征点周围的图像进行模板匹配,达到人脸精细化跟踪的目的。
涉及主要技术:随机梯度下降法、最小二乘法
4. face_detector:人脸检测器,通过学习训练使我们的系统能够学习人脸外界矩形与人脸跟踪特征之间的几何关系 detector_offset 向量,然后利用该向量对人脸参考形状矩阵 reference 进行仿射变换,获得外界矩形区域内的人脸特征点。
涉及主要技术:OpenCV 内置的级联检测器、学习外界矩形与人脸特征点之间的几何关系 detector_offset
二、打算怎么去跟踪
- 手工标注数据,获取原始训练样本(多人、多表情)
- 训练形状模型(提取这些表情模型,几何依赖关系保证后面的跟踪像人脸)
- 训练团块模型(提取每个表情所包含的团块特征,人脸跟踪全靠这个模版匹配)
- 初始化人脸检测器(怎么在第一帧或跟踪失败时,开始或继续人脸检测)
- 根据上一帧的人脸特征点,结合形状和团块信息,估计当前帧的人脸特征点集(考虑空间高斯噪声,此噪声是跟踪错误导致,不是图像噪声)