前面爬取了拉勾网的信息,然后想继续类别拓展试着去爬取别的网址,于是选择了爬取去哪儿的自由行
首先是进行网页的分析
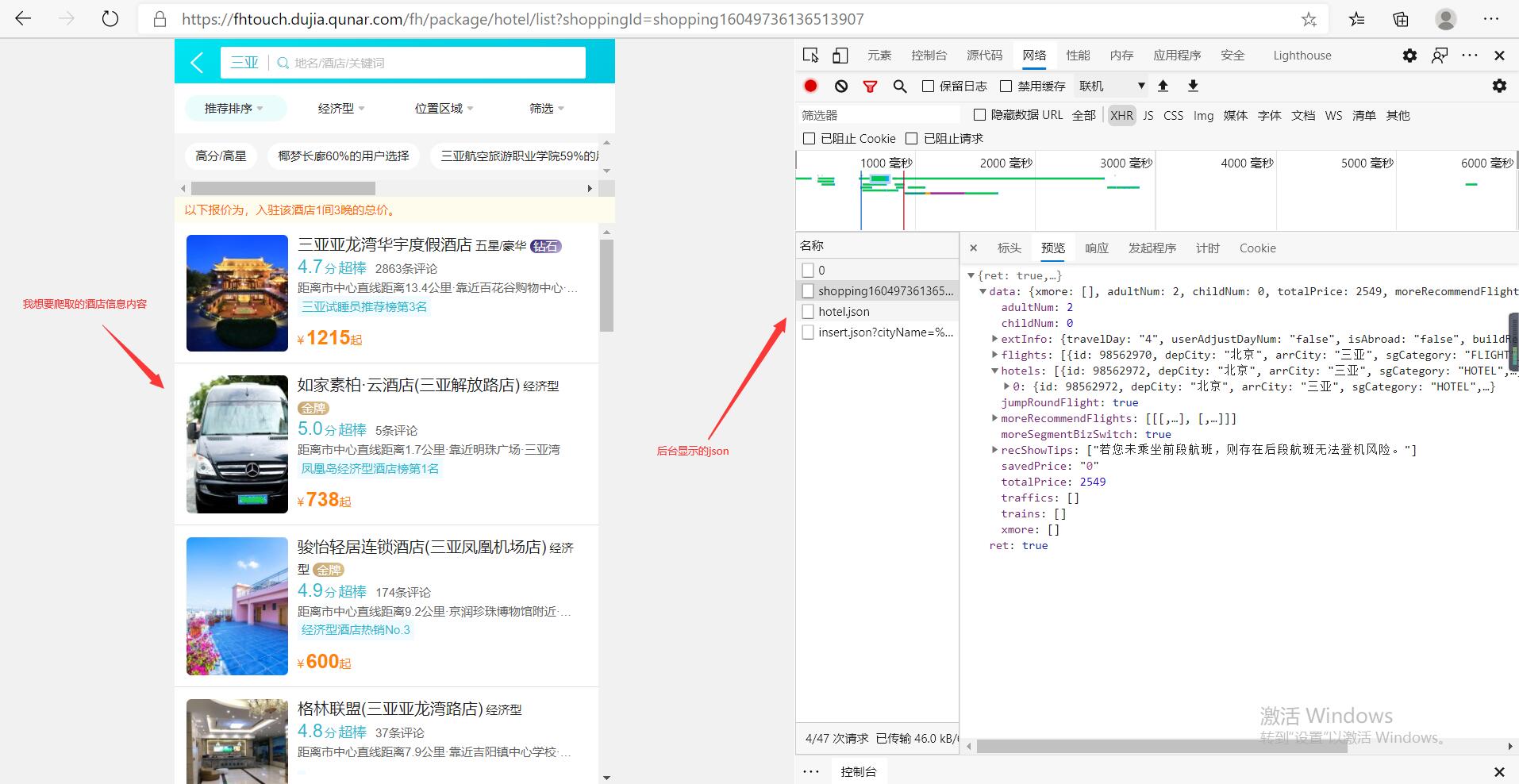

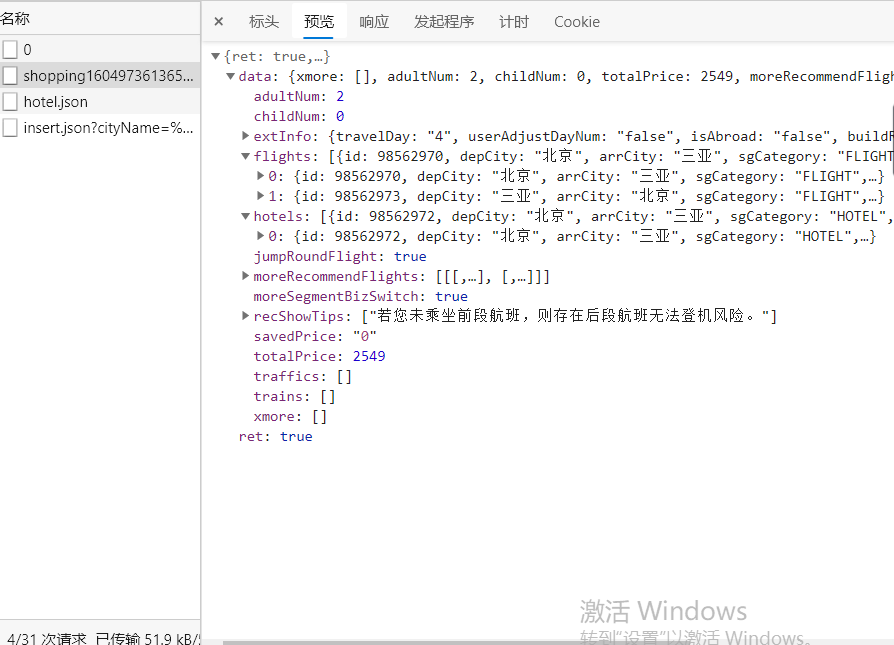
经过对比hotel.json包含了页面的20个酒店信息,而shopping16049736136513907.json只有列表中第一个酒店的信息,可知我们要爬取的是hotel.json
但是按照我们前面爬取拉勾网的方法爬取hotel.json时出现了以下错误:
import requests url = 'https://fhtouch.dujia.qunar.com/fh/hotel.json' def get_json(url, num): """ 从指定的url中通过requests请求携带请求头和请求体获取网页中的信息, :return: """ url1 = 'https://fhtouch.dujia.qunar.com/fh/package/hotel/list?flag=0&origin=dujia&tm=fh_tuijian&tf=fhh_gt&shoppingId=shopping16049301663893712' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63', 'Host': 'fhtouch.dujia.qunar.com', 'Referer': 'https://fhtouch.dujia.qunar.com/fh/package/hotel/list?flag=0&origin=dujia&tm=fh_tuijian&tf=fhh_gt&shoppingId=shopping16049301663893712', 'content-type': 'application/json', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'origin': 'https://fhtouch.dujia.qunar.com', } data = { } s = requests.Session() print('建立session:', s, ' ') s.get(url=url1, headers=headers, timeout=3) cookie = s.cookies print('获取cookie:', cookie, ' ') res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=6) res.raise_for_status() res.encoding = 'utf-8' page_data = res.json() print('请求响应结果:', page_data, ' ') return page_data print(get_json(url, 1))
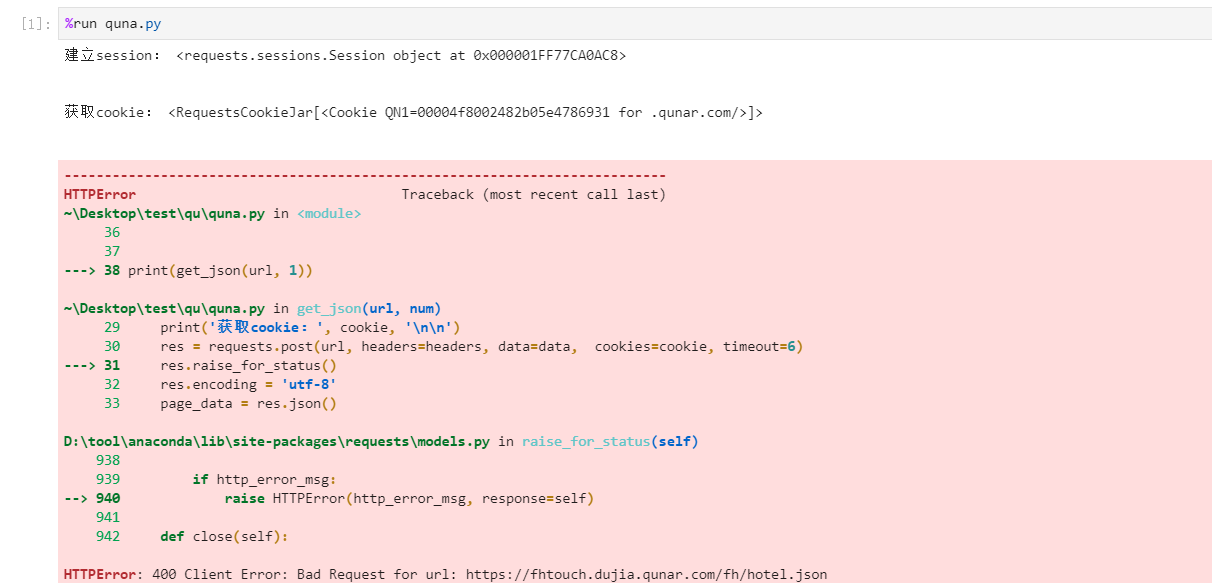
我才可能是由反爬的东西,但是目前我初学还解决不了
但是我爬取shopping16049736136513907.json却成功了
import requests import math import time import pandas as pd import json def get_json(url): """ 从指定的url中通过requests请求携带请求头和请求体获取网页中的信息, :return: """ url1 = 'https://fhtouch.dujia.qunar.com/fh/package/hotel/list?shoppingId=shopping16049736136513907&flag=0&origin=fhhome' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63', 'Host': 'fhtouch.dujia.qunar.com', 'Referer': 'https://fhtouch.dujia.qunar.com/fh/package/hotel/list?shoppingId=shopping16049736136513907&flag=0&origin=fhhome', 'content-type': 'application/json' } data = { } s = requests.Session() print('建立session:', s, ' ') s.get(url=url1, headers=headers, timeout=3) cookie = s.cookies print('获取cookie:', cookie, ' ') res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3) res.raise_for_status() res.encoding = 'utf-8' page_data = res.json() return page_data def get_page_info(jobs_list): """ 获取职位 :param jobs_list: :return: """ page_info_list = [] for i in jobs_list: job_info = [] job_info.append(i['depCity']) for j in i['resList']: job_info.append(j['name']) job_info.append(j['grade']) job_info.append(j['address']+j['locationInfo']) job_info.append(j['in']) job_info.append(j['out']) job_info.append(j['room_type']) for k in j['rooms']: job_info.append(k['finalPrice']) page_info_list.append(job_info) return page_info_list def main(): url = ' https://fhtouch.dujia.qunar.com/fh/detail/shopping16049736136513907.json' # 获取每一页的职位相关的信息 page_data = get_json(url) # 获取响应json total_page_count = page_data['data']['totalPrice'] jobs_list = page_data['data']['hotels'] page_info = get_page_info(jobs_list) num=30 print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num)) print("每一页python相关的职位信息:%s" % page_info, ' ') if __name__ == '__main__': main()
