sorted_set 类型
- 新的存储需求:数据排序有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
- 需要的存储结构:新的存储模型,可以保存可排序的数据
- sorted_set类型:在set的存储结构基础上添加可排序字段
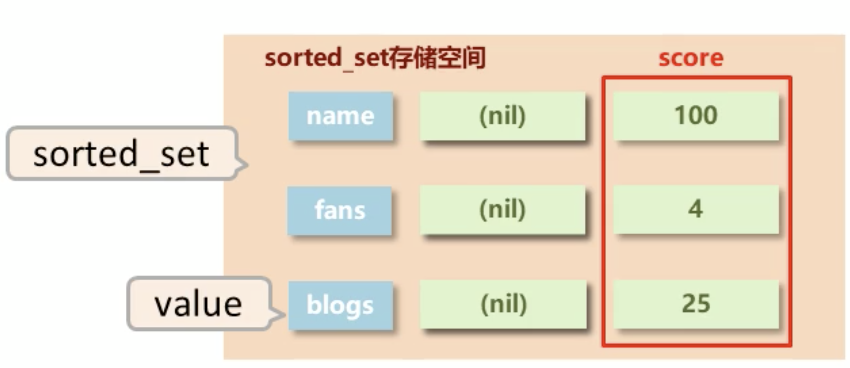
sorted_set 类型数据的基本操作
添加数据
命令:
zadd key score1 member1 [score2 member2]
例:
zadd scores 90 ls
zadd scores 100 zs
获取全部数据
zrange key start stop [WITHSCORES]
zrevrange key start stop [WITHSCORES]
删除数据
zrem key member [member ...]
按条件获取数据
zrangebyscore key min max [WITHSCORES] [LIMIT]
zrevrangebyscore key max min [WITHSCORES]
条件删除数据
zremrangebyrank key start stop
zremrangebyscore key min max
注意:
- min与max用于限定搜索查询的条件
- start与stop用于限定查询范围,作用于索引,表示开始和结束索引
- offset与count用于限定查询范围,作用于查询结果,表示开始位置和数据总量
获取集合数据总量
zcard key
zcount key min max
集合交、并操作
zinterstore destination numkeys key [key ...]
zunionstore destination numkeys key [key ...]
sorted_set 类型数据的扩展操作
业务场景
票选广东十大杰出青年,各类综艺选秀海选投票 各类资源网站TOP10(电影,歌曲,文档,电商,游戏等) 聊天室活跃度统计
游戏好友亲密度
业务分析
- 为所有参与排名的资源建立排序依据
解决方案
获取数据对应的索引(排名)
zrank key member
zrevrank key member
score值获取与修改
zscore key member
zincrby key increment member(原值上加)
Tips 13:
- redis 应用于计数器组合排序功能对应的排名
sorted_set 类型数据操作的注意事项
- score保存的数据存储空间是64位,如果是整数范围是-9007199254740992~9007199254740992
- score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时候要慎重
- sorted_set 底层存储还是基于set结构的,因此数据不能重复,如果重复添加相同的数据,score值将被反 复覆盖,保留最后一次修改的结果
业务场景
基础服务+增值服务类网站会设定各位会员的试用,让用户充分体验会员优势。例如观影试用VIP、游戏VIP体验、云盘下载体验VIP、数据查看体验VIP。当VIP体验到期后,如果有效管理此类信息。即便对于正式VIP用户也存在对应的管理方式。
网站会定期开启投票、讨论,限时进行,逾期作废。如何有效管理此类过期信息。
解决方案
-
对于基于时间线限定的任务处理,将处理时间记录为score值,利用排序功能区分处理的先后顺序
-
记录下一个要处理的时间,当到期后处理对应任务,移除redis中的记录,并记录下一个要处理的时间
-
当新任务加入时,判定并更新当前下一个要处理的任务时间
-
为提升sorted_set的性能,通常将任务根据特征存储成若干个sorted_set。例如1小时内,1天内,周内,月内,季内,年度等,操作时逐级提升,将即将操作的若干个任务纳入到1小时内处理的队列中
-
获取当前系统时间
timeTips 14:
redis 应用于定时任务执行顺序管理或任务过期管理