一、通过Serializer类实现序化器
1、序列化输出示例:
class Project(models.Model): """项目表""" objects = models.Manager() name =models.CharField(max_length=32,verbose_name="项目名称",null=False) desc = models.CharField(max_length=64,verbose_name="项目描述") status = models.BooleanField(verbose_name="状态",default=True) created_time = models.DateTimeField('创建日期', auto_now = True) def __str__(self): return self.name
from rest_framework import serializers class ProjectsSerializer(serializers.Serializer): name =serializers.CharField(max_length=32,label="项目名称") desc = serializers.CharField(max_length=64,label="项目描述") status = serializers.BooleanField(label="状态",default=True) created_time = serializers.DateTimeField(label='创建日期')
#序列化操作示例 class ProjcetsViews(View): def get(self,request,pk): projects = Project.objects.get(pk=pk) serializer = ProjectsSerializer(instance=projects) return JsonResponse(serializer.data) def get(self,request): projects = Project.objects.all() serializer = ProjectsSerializer(instance=projects,many=True) return JsonResponse(serializer.data,safe=False)
2、反序列化、校验前端数据:
def post(self, request): """创建项目""" data = request.body.decode("utf-8") # 接收到的是自己序列,需要反序列化成python对象 python_data = json.loads(data) # 生成序列化对象,传参给data参数 serializer = ProjectsSerializer(data=python_data) # 根据模型中定义的字段属性,用is_valid方法校验,raise_exception参数决定是否抛出异常 if serializer.is_valid(): # 校验通过后,通过validated_data属性获取校验过后的参数 param = serializer.validated_data # 创建model对象保存到数据库 obj = Project.objects.create(**param) # 将创建的对象序列化后,返回给前端 obj_serializer = ProjectsSerializer(instance=obj) return JsonResponse(obj_serializer.data) else: # 校验失败,通过errors属性获取错误信息 return JsonResponse(serializer.errors) return JsonResponse({"result": True})
校验通过、不通过示例:
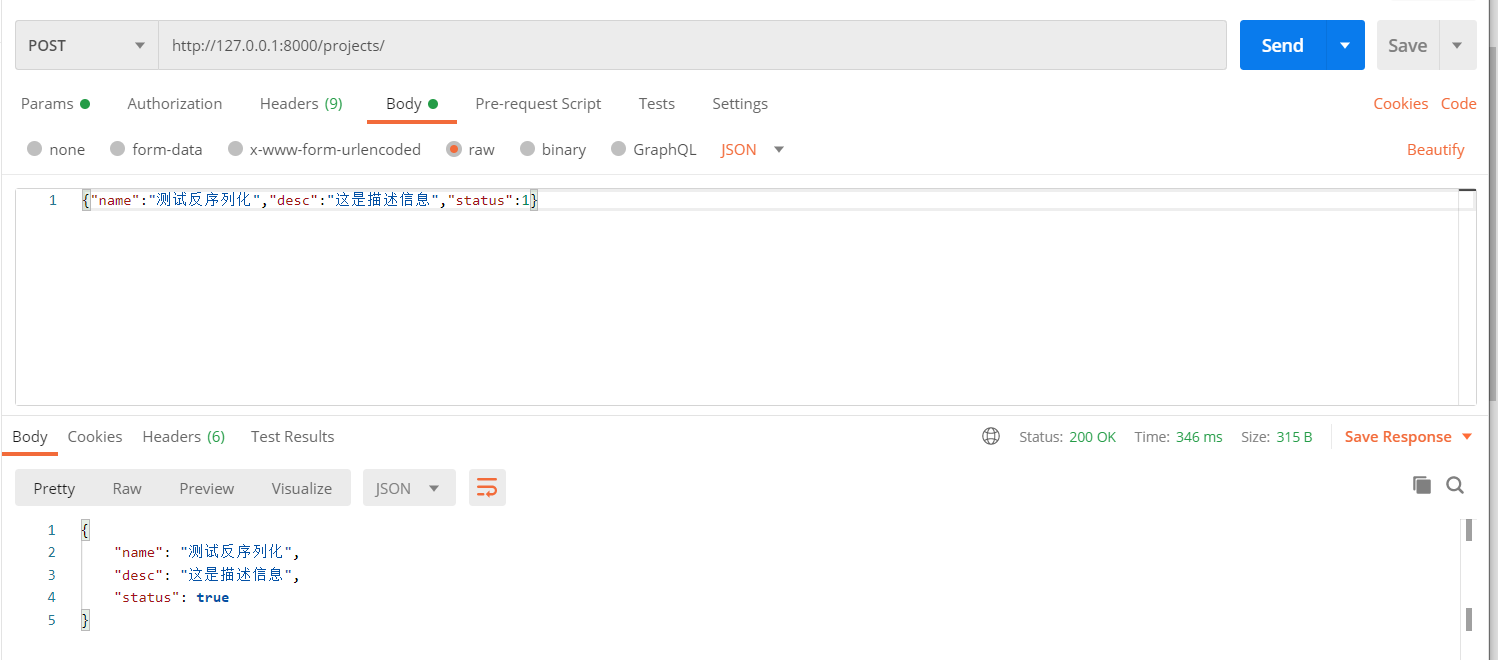
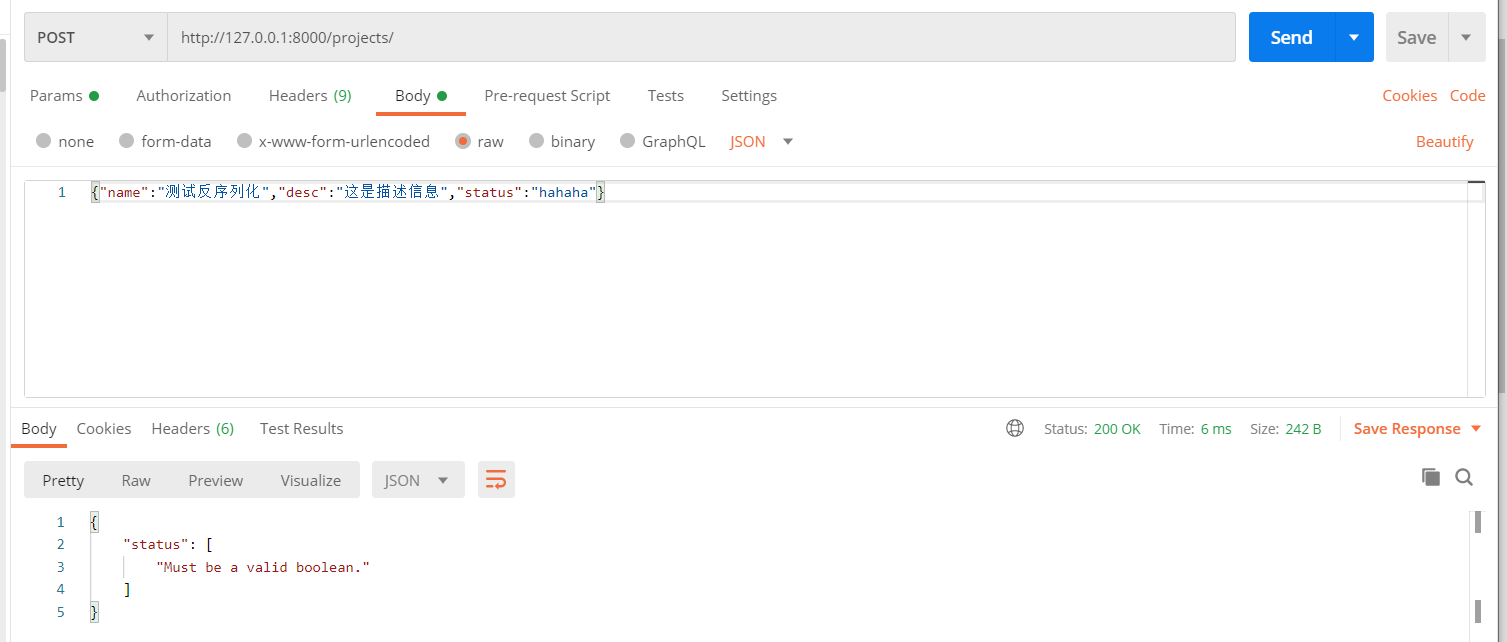
3、校验某个字段
自定义校验器:
# 自定义校验器 # 第一个参数为字段值 def project_name_is_valid(name): if "项目" not in name: raise serializers.ValidationError(detail="项目名称必须包含'项目'", code=10001) class ProjectsSerializer(serializers.Serializer): name = serializers.CharField(max_length=32, label="项目名称", validators=[UniqueValidator(queryset=Project.objects.all(), message="项目名称不能重复"), project_name_is_valid]) desc = serializers.CharField(max_length=64, label="项目描述") status = serializers.BooleanField(label="状态", default=True)

钩子函数方式定义校验器:
from rest_framework import serializers from rest_framework.validators import UniqueValidator from personal.models import Project # 自定义校验器 # 第一个参数为字段值 def project_name_is_valid(name): if "项目" not in name: raise serializers.ValidationError(detail="项目名称必须包含'项目'", code=10001) class ProjectsSerializer(serializers.Serializer): name = serializers.CharField(max_length=32, label="项目名称", validators=[UniqueValidator(queryset=Project.objects.all(), message="项目名称不能重复"), project_name_is_valid]) desc = serializers.CharField(max_length=64, label="项目描述") status = serializers.BooleanField(label="状态", default=True) # read_only=True只做序列化输出 created_time = serializers.DateTimeField(label='创建日期', read_only=True) # 单字段校验,validate_字段名称,参数为字段值 # 校验通过后,需要返回字段值 # 不需要显示调用 def validate_name(self, value): if not value.endswith("项目"): raise serializers.ValidationError("项目名称必须以'项目'结尾") return value # 多字段联合校验 # 函数名称固定为validate,attrs为包含所有字段名称和值的字典 # 校验成功后,返回attrs # 项目名称或者描述中必须包含"test" def validate(self, attrs): if 'test' not in attrs["name"] and 'test' not in attrs["desc"]: raise serializers.ValidationError("项目名称或者描述中必须包含'test'") return attrs
校验顺序:按照字段定义时从左到右的顺序:字段类型-字段长度-validators列表中的校验器-validate_name-多字段校验valitate
4、在序列化器中定义数据库操作方法
# 视图类中的POST(创建),PUT(更新操作)
# 序列化操作示例 class ProjcetsViews(View): def get(self, request, pk): projects = Project.objects.get(pk=pk) serializer = ProjectsSerializer(instance=projects) return JsonResponse(serializer.data) def get(self, request): projects = Project.objects.all() serializer = ProjectsSerializer(instance=projects, many=True) return JsonResponse(serializer.data, safe=False) def post(self, request): """创建项目""" data = request.body.decode("utf-8") # 接收到的是自己序列,需要反序列化成python对象 python_data = json.loads(data) # 生成序列化对象,传参给data参数 serializer = ProjectsSerializer(data=python_data) # 根据模型中定义的字段属性,用is_valid方法校验,raise_exception参数决定是否抛出异常 if serializer.is_valid(): # 校验通过后,通过validated_data属性获取校验过后的参数 param = serializer.validated_data # 创建model对象保存到数据库 # obj = Project.objects.create(**param) serializer.save() # 将创建的对象序列化后,返回给前端 # obj_serializer = ProjectsSerializer(instance=obj) return JsonResponse(serializer.data) else: # 校验失败,通过errors属性获取错误信息 return JsonResponse(serializer.errors) return JsonResponse({"result": True}) def put(self, request, pk): """修改项目""" project = Project.objects.get(pk=pk) param = request.body.decode("utf-8") python_data = json.loads(param) # 序列化时给data传参,调用save方法时,实际上调用的是序列化器的create方法 # 序列化时给data、instance传参,调用save方法时,实际上调用的是序列化器的update方法 serializer = ProjectsSerializer(instance=project, data=python_data) try: serializer.is_valid(raise_exception=True) except: return JsonResponse(serializer.errors) serializer.save() return JsonResponse(serializer.data)
from rest_framework import serializers from rest_framework.validators import UniqueValidator from personal.models import Project # 自定义校验器 # 第一个参数为字段值 def project_name_is_valid(name): if "项目" not in name: raise serializers.ValidationError(detail="项目名称必须包含'项目'", code=10001) class ProjectsSerializer(serializers.Serializer): name = serializers.CharField(max_length=32, label="项目名称", validators=[UniqueValidator(queryset=Project.objects.all(), message="项目名称不能重复"), project_name_is_valid]) desc = serializers.CharField(max_length=64, label="项目描述") status = serializers.BooleanField(label="状态", default=True) # read_only=True只做序列化输出 created_time = serializers.DateTimeField(label='创建日期', read_only=True) # 单字段校验,validate_字段名称,参数为字段值 # 校验通过后,需要返回字段值 # 不需要显示调用 def validate_name(self, value): if not value.endswith("项目"): raise serializers.ValidationError("项目名称必须以'项目'结尾") return value # 多字段联合校验 # 函数名称固定为validate,attrs为包含所有字段名称和值的字典 # 校验成功后,返回attrs # 项目名称或者描述中必须包含"test" def validate(self, attrs): if 'test' not in attrs["name"] and 'test' not in attrs["desc"]: raise serializers.ValidationError("项目名称或者描述中必须包含'test'") return attrs # 重写实现新增操作 # validated_data为序列器验证通过后的字典类型数据 def create(self, validated_data): return Project.objects.create(**validated_data) # 重写实现更新操作 # instance为要更新的对象,validated_data为序列器校验通过后的参数 def update(self, instance, validated_data): instance.name = validated_data["name"] instance.desc = validated_data["desc"] instance.status = validated_data["status"] instance.save() return instance
思考:为啥序列化器调用save方法的时候,能分别调用create、update方法呢
1、我们自定义的序列化器继承了序列化类:Serializer
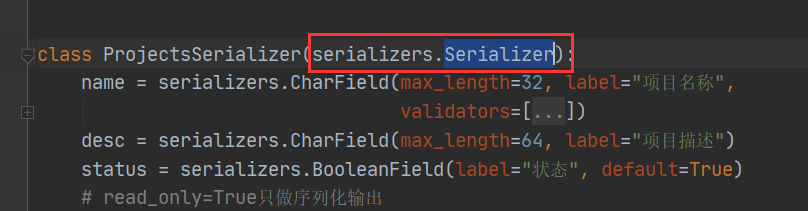
2、Serializer类继承了:BaseSerializer类
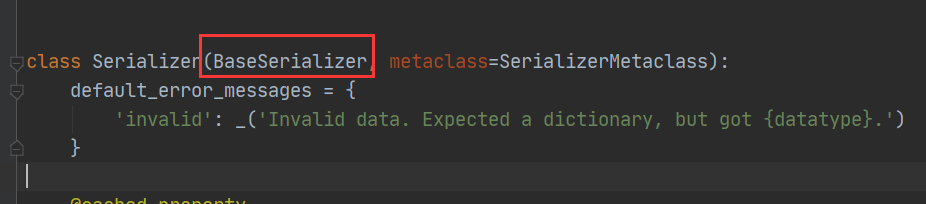
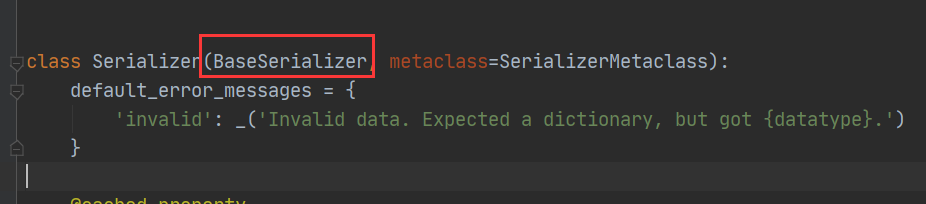
3、在BaseSerializer类中关于create、update、save的方法如下:
def update(self, instance, validated_data): raise NotImplementedError('`update()` must be implemented.') def create(self, validated_data): raise NotImplementedError('`create()` must be implemented.') def save(self, **kwargs): assert not hasattr(self, 'save_object'), ( 'Serializer `%s.%s` has old-style version 2 `.save_object()` ' 'that is no longer compatible with REST framework 3. ' 'Use the new-style `.create()` and `.update()` methods instead.' % (self.__class__.__module__, self.__class__.__name__) ) assert hasattr(self, '_errors'), ( 'You must call `.is_valid()` before calling `.save()`.' ) assert not self.errors, ( 'You cannot call `.save()` on a serializer with invalid data.' ) # Guard against incorrect use of `serializer.save(commit=False)` assert 'commit' not in kwargs, ( "'commit' is not a valid keyword argument to the 'save()' method. " "If you need to access data before committing to the database then " "inspect 'serializer.validated_data' instead. " "You can also pass additional keyword arguments to 'save()' if you " "need to set extra attributes on the saved model instance. " "For example: 'serializer.save(owner=request.user)'.'" ) assert not hasattr(self, '_data'), ( "You cannot call `.save()` after accessing `serializer.data`." "If you need to access data before committing to the database then " "inspect 'serializer.validated_data' instead. " ) validated_data = dict( list(self.validated_data.items()) + list(kwargs.items()) ) if self.instance is not None: self.instance = self.update(self.instance, validated_data) assert self.instance is not None, ( '`update()` did not return an object instance.' ) else: self.instance = self.create(validated_data) assert self.instance is not None, ( '`create()` did not return an object instance.' ) return self.instance
从上述源码中可以看出:
1、必须在自定义序列器中显示create、update方法,否则对象在调用的时候会调用父类的方法,抛出NotImplementedError异常
2、save方法解释了什么情况下调用create、update方法:
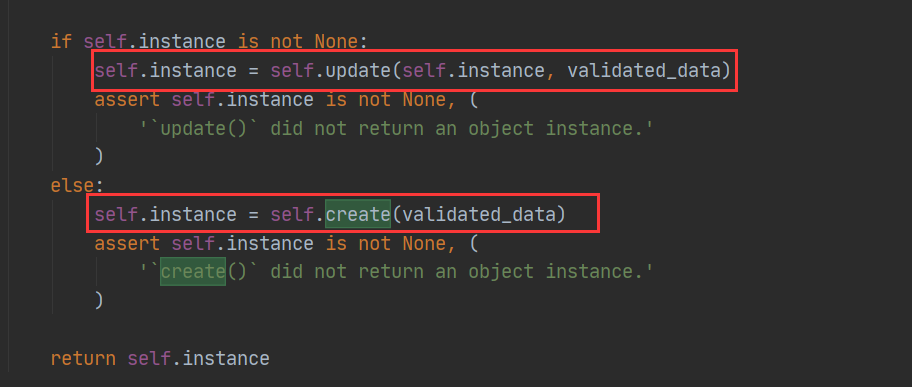
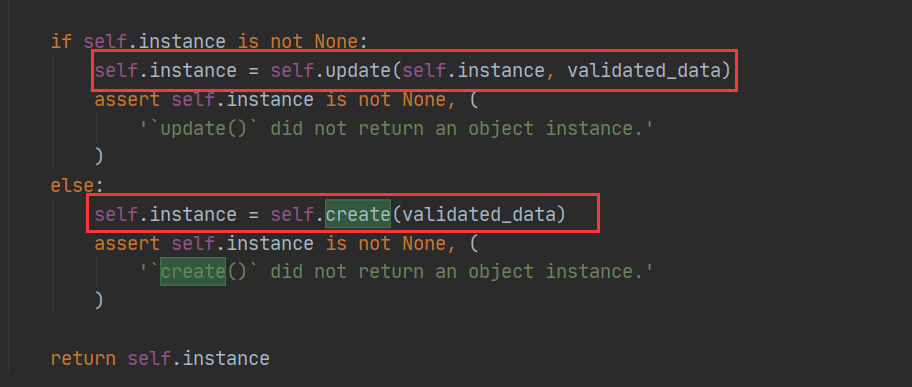
3、update、create方法都需要将创建、修改的对象返回
二、通过ModelSerializer类实现序列化器
class ProjectModelSerializer(serializers.ModelSerializer): # 重新定义字段属性,覆盖自动生成的,比如添加自定义的校验器 name = serializers.CharField(max_length=32, label="项目名称", validators=[UniqueValidator(queryset=Project.objects.all(), message="项目名称不能重复"), project_name_is_valid], error_messages={"max_length": "名称不能超过32个字节"}) # 单字段、多字段校验一样的需要手动实现 # 单字段校验,validate_字段名称,参数为字段值 # 校验通过后,需要返回字段值 # 不需要显示调用 def validate_name(self, value): if not value.endswith("项目"): raise serializers.ValidationError("项目名称必须以'项目'结尾") return value # 多字段联合校验 # 函数名称固定为validate,attrs为包含所有字段名称和值的字典 # 校验成功后,返回attrs # 项目名称或者描述中必须包含"test" def validate(self, attrs): if 'test' not in attrs["name"] and 'test' not in attrs["desc"]: raise serializers.ValidationError("项目名称或者描述中必须包含'test'") return attrs class Meta: # 指定参考哪个模型来创建序列化器 modle = Project # 指定为模型类的哪些字段来生成序列化器 # 所有字段,其中主键为加上read_only=True fields = "__all__" # 指定部分字段 # fields = ("name","desc") # 排除部分字段 # exclude = ("id") # 定义只序列化输出的、不反序列化输入的字段 # read_only_fields = ("status",) # 为字段添加额外的属性 extra_kwargs = { 'name': { 'write_only': True, "error_messages": { "max_length": "名称最大长度不能超过32个字节" } } }
基本用法见代码中注释,序列化和反序列与方式一一致,主要是对方式一的一些简化
另外,ModelSerializer类已经实现了create、update方法,不用自己写