补充:实时流计算和离线数据流计算
(一)离线计算
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
1,hivesql 2、调度平台 3、Hadoop集群运维 4、数据清洗(脚本语言) 5、元数据管理 6、数据稽查 7、数据仓库模型架构
(二)流式计算
Flume实时采集,低延迟
Kafka消息队列,低延迟
Storm实时计算,低延迟
Redis实时存储,低延迟
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
一:storm简介
(一)简介
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
Storm是一个免费并开源的分布式实时计算系统。
利用Storm可以很容易做到可靠地处理无限的数据流,
像Hadoop批量处理大数据一样,Storm可以实时处理数据。
Storm简单,可以使用任何编程语言
它提供相应简单的编程模型就可以实现实时数据计算处理功能
它非常快速,秒级处理百万元组数据,它是一个可扩展、保证数据肯定会处理的框架

(二)storm特点
编程简单:开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程原语也很简单
高性能,低延迟:可以应用于广告搜索引擎这种要求对广告主的操作进行实时响应的场景。
分布式:可以轻松应对数据量大,单机搞不定的场景
可扩展: 随着业务发展,数据量和计算量越来越大,系统可水平扩展
容错:单个节点挂了不影响应用
消息不丢失:保证消息处理
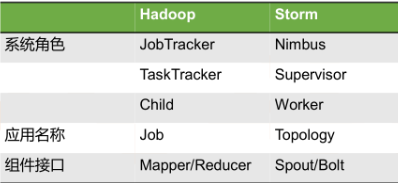
(三)storm与hadoop的比较
1.Storm用于实时计算,Hadoop用于离线计算。
2.Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
3.Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
4.Storm与Hadoop的编程模型相似
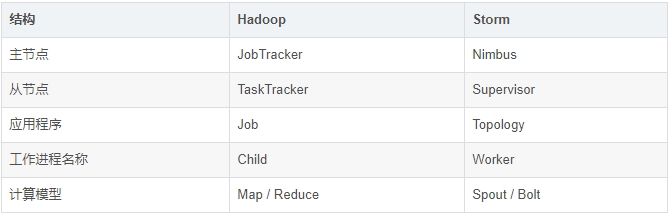
1.Hadoop
Job:任务名称
JobTracker:项目经理
TaskTracker:开发组长、产品经理
Child:负责开发的人员
Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发
2.Storm
Topology:任务名称
Nimbus:项目经理
Supervisor:开组长、产品经理
Worker:开人员
Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
5.Storm任务没有结束,Hadoop任务执行完结束
6.Storm延时更低,得益于网络直传、内存计算,省去了批处理的收集数据的时间
7.Hadoop使用磁盘作为中间交换的介质,而storm的数据是一直在内存中流转的
8.Storm的吞吐能力不及Hadoop,所以不适合批处理计算模型
1. 延时,指数据从产生到运算产生结果的时间
2. 吞吐,指系统单位时间处理的数据量
(四)storm框架模型
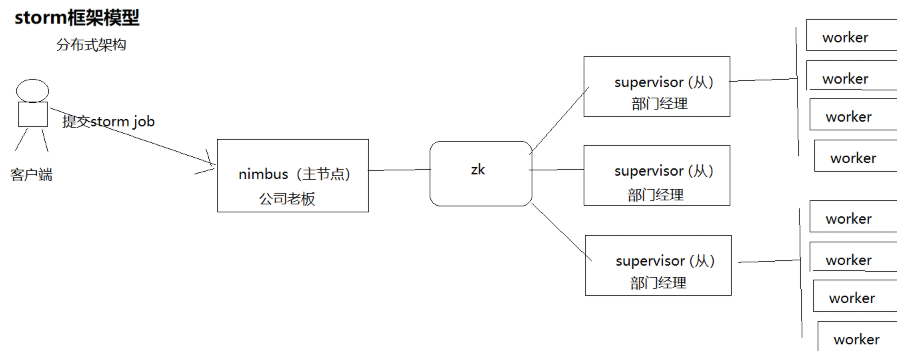
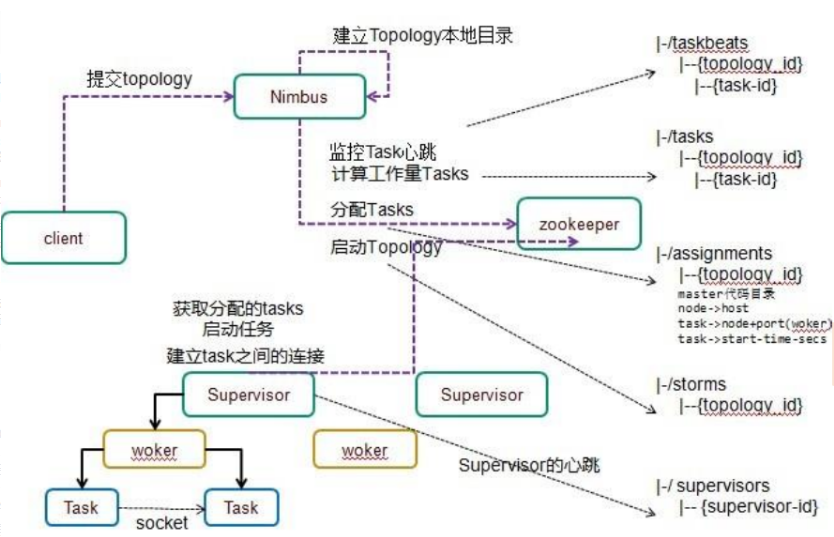
1.Nimbus:负责资源分配和任务调度。
2.Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
3.Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
4.Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
(五)Storm编程模型
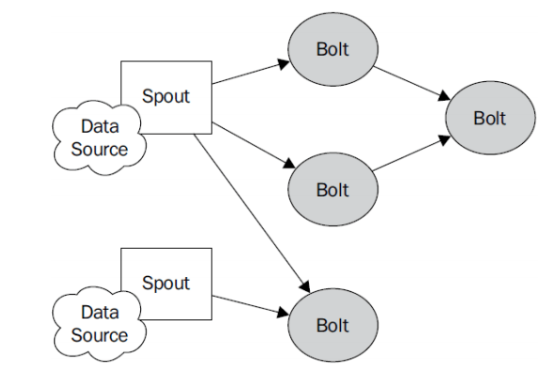
1.Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
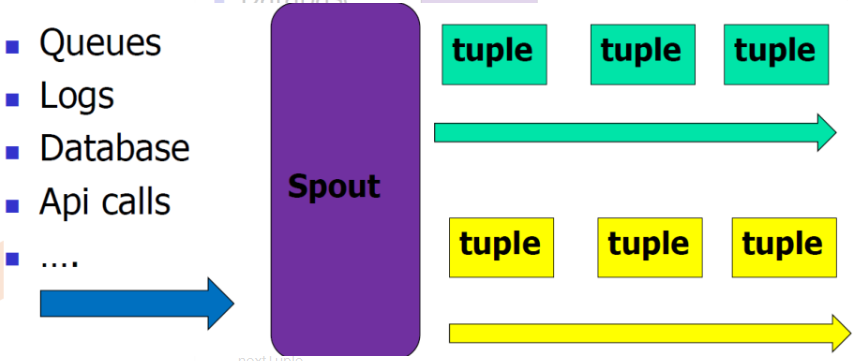
2.Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
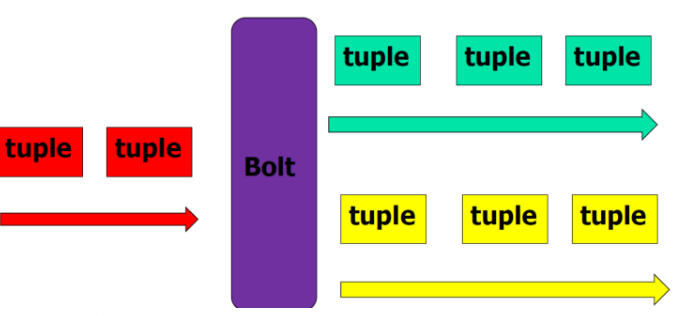
3.Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
4.Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
5.Stream:表示数据的流向。
(六)流式计算一般架构图

1.其中flume用来获取数据。
2.Kafka用来临时保存数据。
3.Strom用来计算数据。
4.Redis是个内存数据库,用来保存数据。
Flume实时采集,低延迟
Kafka消息队列,低延迟
Storm实时计算,低延迟
Redis实时存储,低延迟
二:Storm各组件的基本概念

(一)Stream
– 以Tuple为基本单位组成的一条有向无界的数据流
(二)Tuple
– Integer,long,short,byte,string,double,float,boolean和byte array,包括自定义类型
(三)Topology
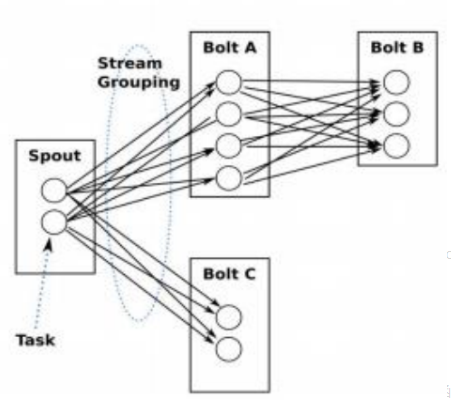
– 计算逻辑的封装
– 由spouts和bolts组成的图,通过stream grouping将图中的spouts和bolts连接起来
– 类同MapReduce中的job
• 不会结束,除非主动kill
(四)Topology任务执行
– Storm jar code.jar MyTopology arg1 arg2
• storm jar负责连接到Nimbus并且上传jar包
• 运行主类 MyTopology, 参数是arg1, arg2;这个类的main函数定义这个topology并且把它提交给Nimbus
• Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务,你可以提交由任何语言创建的topology;
(五)Spout
– 消息来源,消息生产者
– 可靠的,不可靠的
• 可靠的,如果没有被成功处理,可重新emit一个tuple
– 可指定emit多个Stream流
• OutFieldsDeclarer.declareStream定义
• SpoutOutputCollector指定
– nextTuple
(六)Bolt
– 消息处理逻辑
• 如过滤,访问数据库,聚合
– 多个bolt处理负责步骤
– 可以发射多个数据流
– 主方法为execute
• 以tuple为输入
• 处理具体的tuple
• 发射0或多个tuple
• OutputCollector的ack,确认
• IBasicBolt,会自动调节
(七)Stream Grouping

– Shuffle Grouping:随机分组
– Fields Grouping:按指定的field分组
– All Grouping:广播分组
– Global Grouping:全局分组
三:Storm常见模式
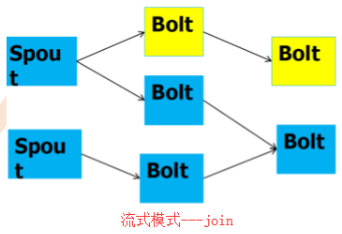
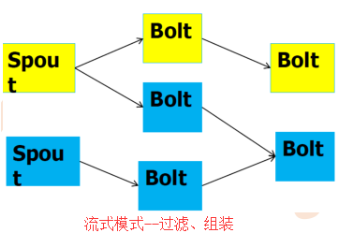
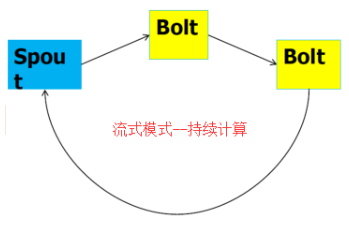
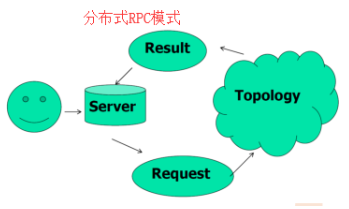
storm常见模式有3种,包括 流式计算、持续计算、分布式RPC,如图所示

(一)流式计算

(二)持续计算
(三)分布式 RPC模式
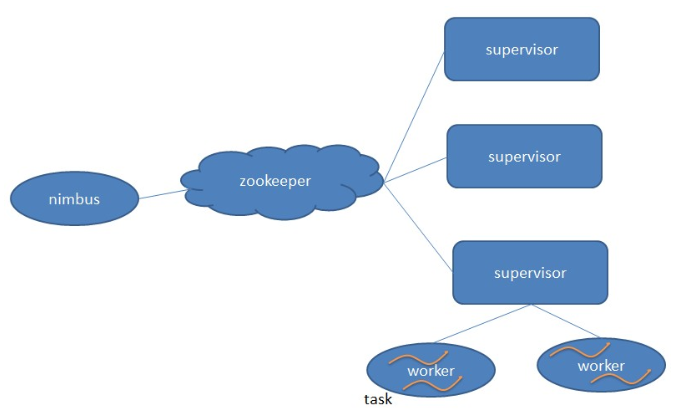
四:storm架构
(一)Nimbus
– Master Node
– 负责资源分配和任务调度
– 类似Hadoop里的JobTracker,负责在集群里面分发代码,分配计算任务给Supervisor,并且监控状态
(二)Supervisor
– Worker Node
– 负责接收nimbus分配的任务
– 每个工作节点存在一个
– 启动和停止属于自己管理的worker进程(每一个工作进程执行一个Topology的一个子集,一个Topology由运行在很多机器 上的很多worker工作进程组成)
(三)Nimbus和Supervisor关系
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成
Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有状态要么在Zookeeper里面,要么在本地磁盘上
这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
(四)Worker
– 运行具体处理组件逻辑的进程
– 一个Topology可能会在一个或者多个worker里面执行
– 每个worker是一个物理JVM并且执行整个Topology的一部分
– 采取JDK的Executor
比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks,Storm会尽量均匀的工作分配给所有的worker
(五)Task
– Worker中的每一个spout/bolt的线程称为一个task
– 每一个spout和bolt会被当作很多task在整个集群里执行
– 每一个executor对应到一个线程,在这个线程上运行多个task
– stream grouping则是定义怎么从一堆task发射tuple到另外一堆task
– 可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)
(六)Worker和Task关系

1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。
1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。
因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。
每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。
topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。
这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
相关伪代码:
Config conf = new Config(); //设置Worker数量 conf.setNumWorkers(2); // 设置Executor数量 topolopyBuilder.setSpout("BlueSpout", new BlueSpout(), 2); topolopyBuilder.setBolt("GreenBolt", new GreenBolt(), 2) .setNumTasks(4) // 设置Task数量 .shuffleGrouping("BlueSpout"); topolopyBuilder.setBolt("YellowBolt", new YellowBolt(), 6) .shuffleGrouping("GreenBolt");
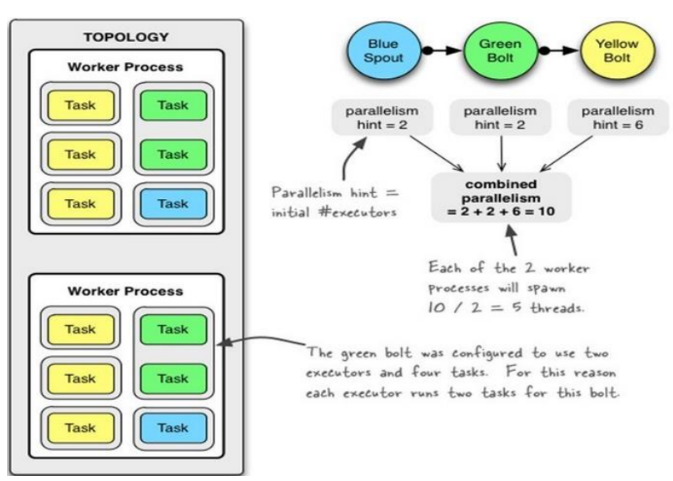

补充:重新配置Topology "myTopology"使用5个Workers、BlueSpout使用3个Executors、YellowSpout使用10个Executors
storm rebalance myTopology -n 5 -e BlueSpout=3 -e YellowSpout=10
(七)总结
一个topology可以通过setNumWorkers来设置worker的数量,通过设置parallelism来规定executor的数量(一个component(spout/bolt)可以由多个executor来执行),通过setNumTasks来设置每个executor跑多少个task(默认为一对一)。task是spout和bolt执行的最小单元。
五:Storm容错
(一)架构容错
1.Zookeeper
– 存储Nimbus与Supervisor数据
2.节点宕机
– Heartbeat
– Nimbus
3.Nimbus/Supervisor宕机
– Worker继续工作
– Worker失败,任务失败
4.Worker出错
– Supervisor重启Worker
(二)数据容错
Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间(timeout)内被完全处理。
• Ack机制(Storm中的每一个Topology中都包含有一个Acker组件)
• 所有的节点ack成功,任务成功
• 特殊的Task(Acker Bolt)
– Acker,跟踪每一个spout发出的tuple树
– 一个tuple树完成时,发送消息给tuple的创造者
– Acker的数量, 默认值是1
• 如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率会高一点。
• Acker实现消息完整性机制
– 内存超级大
• Acker Task并不显式的跟踪tuple树。 对于那些有成千上万个节点的tuple树,把这么多的tuple信息都跟踪起来会耗费太多的内存
– 保证消息肯定能被处理一次,但不保证会不会重复。因为假设发出的是一个values被切割后其中一个被发送失败了,那么这一组values都得重新发送。
– spout发送的时候同时带上message_id,这样这个tuple发送失败后,就能知道哪一个tuplele.
– 通过消息的亦或状态确保消息是否发送完整。
– acker默认为每一个spout,bolt分别启动一个线程。
• 真实实现
– 内存量是恒定的(20bytes)
– 对于100万tuple,也才20M 左右
– Taskid:ackval
– Ackval所有创建的tupleid/ack的tuple一起异或
• 一个acker task存储了一个spout-tuple-id到一对值的一个mapping。这个对子的第一个值是创建这个tuple的taskid, 这个是用来在完成处理tuple的时候发送消息用的。 第二个值是一个64位的数字称作:ack val , ack val是整个tuple树的状态的一个表示,不管这棵树多大。它只是简单地把这棵树上的所有创建的tupleid/ack的tupleid一起异或(XOR)。
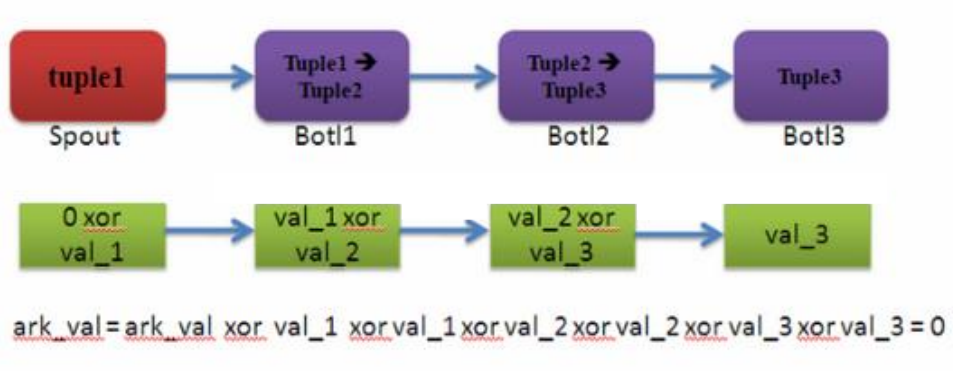
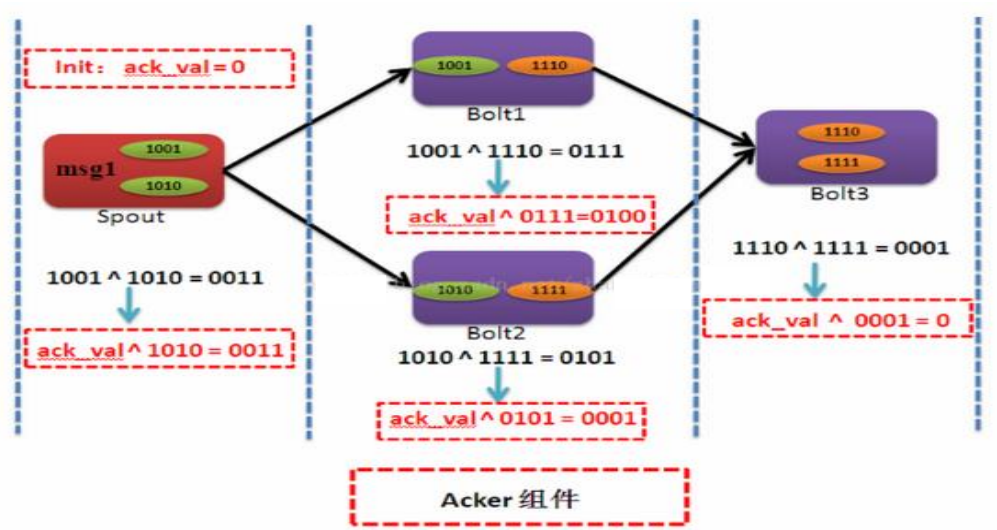
• 一个tuple没有ack
– 处理的task挂掉了,超时,重新处理
• Ack挂掉了
– 一致性hash
– 全挂了,超时,重新处理
• Spout挂掉了
– 重新处理
• Bolt
– Anchoring
• 将tuple作为一个锚点添加到原tuple上
– Multi-anchoring
• 如果tuple有两个原tuple,则为每个tuple添加一个锚点
– Ack
• 通知ack task,该tuple已被当前bolt成功消费
– Fail
• 通知ack task,该tuple已被消费失败