上一篇随笔说了,需要清除bss段,我们现在定义main函数如下:
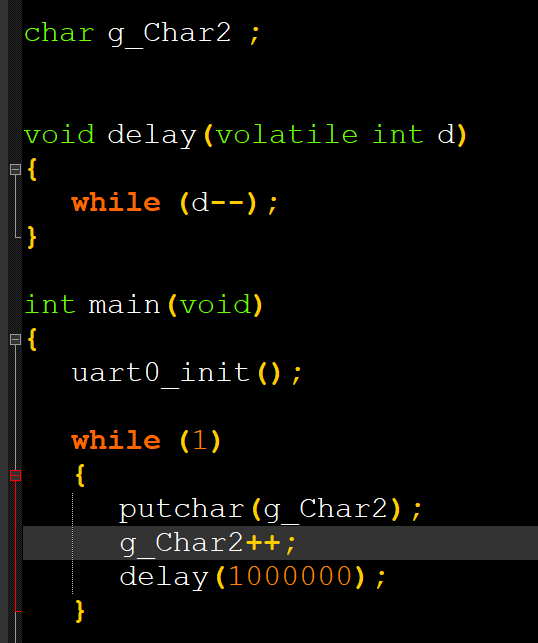
注意这个全局变量是没有初始值的,即存放在bss段中,如果我们的启动文件没有清除bss段,串口的输出将是你想不到情况。比如,现在程序运行执行了++操作20次,你下次快速断电再上电的时候,g_Char2的值是接着之前的值增加的,而增加了清除bss段之后,每次重新上电,都是从0开始的。到这里我是觉得纳闷的,我们程序是重定位到了sdram的,既然是ram中,掉电不就应该是马上丢失数据了吗?然后查询了一下资料,发现:

然后我就多等了一些时间,果然,可以看到sdram数据在慢慢丢失,又涨知识了~
现在我们在start.S中增加清除bss段的代码:
/* 清除BSS段 */ ldr r1, =bss_start ldr r2, =bss_end mov r3, #0 clean: strb r3, [r1] add r1, r1, #1 cmp r1, r2 bne clean
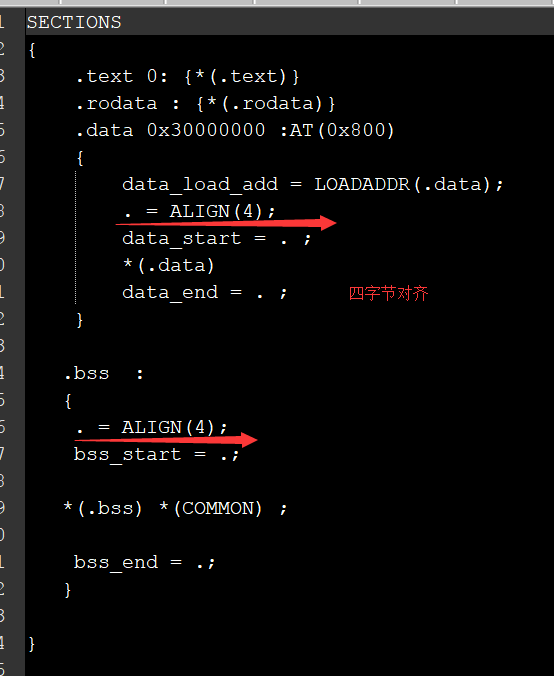
连接脚本也需要更改:
SECTIONS { .text 0: {*(.text)} .rodata : {*(.rodata)} .data 0x30000000 :AT(0x800) { data_load_add = LOADADDR(.data); data_start = . ; *(.data) data_end = . ; } .bss : { bss_start = .; *(.bss) *(COMMON) ; bss_end = .; } }
这样(上面链接脚本中bss段中.bss *(COMMEN)后那个分号仅仅为了美观,会被连接器忽略的,这个在ld连接器那篇文章中有讲到)就可以看到串口输出了,是从ascii码0开始打印的。
回到本文的重点,拷贝代码和连接脚本的改进
我们的sdram是32位的,nor falsh是16位的。
我们的copy和clean采用的b(字节)操作,这样是很费时的,因为sdram每次操作的最小单位是32位的,即四字节,如果采取一个字节的方式,sdram需要发送3个数据屏蔽信号DQM,这样才能只写一个字节,可见效率之低。现在采取4字节方式,改进如下:
/* 重定位data段 */ ldr r1, =data_load_addr /* data段在bin文件中的地址, 加载地址 */ ldr r2, =data_start /* data段在重定位地址, 运行时的地址 */ ldr r3, =data_end /* data段结束地址 */ cpy: ldr r4, [r1] str r4, [r2] add r1, r1, #4 add r2, r2, #4 cmp r2, r3 ble cpy /* 清除BSS段 */ ldr r1, =bss_start ldr r2, =bss_end mov r3, #0 clean: str r3, [r1] add r1, r1, #4 cmp r1, r2 ble clean
这里说明一下 ble汇编指令:

cmp r1, r2
ble clean
比较 r1和r2,如果r1小于等于r2,就跳转到clean。
为什么之前都是用的 bne,而现在要用 ble 了呢?之前是一个字节一个字节的移动,每次都是加一,所以一定会有 r1和r2相等的时候,不相等就复制,相等了就不再执行,可是现在转换成4字节移动的时候,比如我们data段数据只有2个字节,只用一次赋值4个字节,就复制完毕了,但是现在起始地址需要加4,这样就会出现起始地址加4之后大于结束地址,那么就应该不再复制了,这也就是为什么使用ble的原因。可是,使用ble虽然很好的解决了上面所说的问题,也依旧存在一个潜在的浪费,比如我的data段刚好是4个字节,那样执行一次复制之后,其实地址加4刚好就等于结束地址,可是ble是小于等于都要执行,这样的话,就会再次执行拷贝,而其实拷贝在第一次的时候就已经完成了,这样就会多做一次加载地址到运行地址的拷贝,综上,选择使用 BLO或BCC【查看反汇编,使用BLO此时编译器也是转换成BCC执行的】(地址是无符号的,blt是有符号运算)更合适,这也是韦老大的没有注意的地方吧。
下面是可获得的条件代码的列表:
EQ: Equal 等于,(Z = 1)
NE: Not Equal 不等于 (Z = 0)
CS: Carry Set 有进位 (C = 1)
HS: (unsigned Higher Or Same) 同CS (C = 1)
CC: (Carry Clear) 没有进位 (C = 0)
LO: (unsigned Lower) 同CC (C = 0)
MI: (Minus) 结果小于0 (N = 1)
PL: (Plus) 结果大于等于0 (N = 0)
VS: (oVerflow Set) 溢出 (V = 1)
VC: (oVerflow Clear) 无溢出 (V = 0)
HI : (unsigned Higher) 无符号比较,大于 (C = 1 & Z = 0)
LS: (unsigned Lower or Same) 无符号比较,小于等于 (C = 0 & Z = 1)
GE: (signed Greater than or Equal) 有符号比较,大于等于 (N = V)
LT: (signed Less Than) 有符号比较,小于 (N != V)
GT: (signed Greater Than) 有符号比较,大于 (Z = 0 & N = V)
LE: (signed Less Than or Equal) 有符号比较,小于等于 (Z = 1 | N != V)
AL: (Always) 无条件,默认值
NV: (Never) 从不执行
不过很遗憾,我们上面的代码并不能正常工作!
首先说明,我定义了两个全局变量,类型为char,一个字节,共计两个字节,我们的sdram地址是0x30000000,两个字节后,应该从0x30000002开始存储,由于我们清零操作使用str,四字节操作,需要对4的整数倍取地址,所以,这里清零操作会从0x30000000开始,就会使清零bss段的代码也把全局变量给清除了。你或许会问,为什么不是从0x30000004开始,都是4的整数倍,为什么是向下呢(编译器以最节约内存的方式,指定了对齐方式就不同了)?因为我们没有指定对齐的字节数目,向4取整,不足4的倍数,往下计算,而当我们指定对齐4字节时,虽然此时是0x30000002地址,由于规定了对齐字节,会变成0x30000004地址处,为什么这里是向上了?这个C语言中结构体内存对齐的原理一致,前面0x30000002有了存储内容,后面新开始存储的,就需要往后延伸至4的倍数。
所以,改进代码如下:
#include "s3c2440_soc.h" #include "uart.h" #include "init.h" char g_Char = 'A'; char g_Char2 ; int g_A = 0; int g_B; void delay(volatile int d) { while (d--); } int main(void) { uart0_init(); while (1) { putchar(g_Char2); g_Char2++; delay(1000000); putchar(g_Char); g_Char++; delay(1000000); } return 0; }

这样之后,正常运行的同时也没有做多余的操作,经过分析反汇编之后,发现和我理解的一致,韦老大那个代码做了多余的copy操作,反汇编可以清楚的看到data段的起始地址和结束地址,当起始地址累加到等于结束地址的时候,就不该再执行复制操作了,所以不应该使用ble这个有符号的还是条件小于等于的指令。