学习索引,主要是写出更快的sql,当我们写sql的时候,需要明确的知道sql为什么会走索引?为什么有些sql不走索引?sql会走那些索引,为什么会这么走?我们需要了解其原理,了解内部具体过程,这样使用起来才能更顺手,才可以写出更高效的sql。本篇我们就是搞懂这些问题。
先来回顾一些知识:
mysql采用b+树的方式存储索引信息。
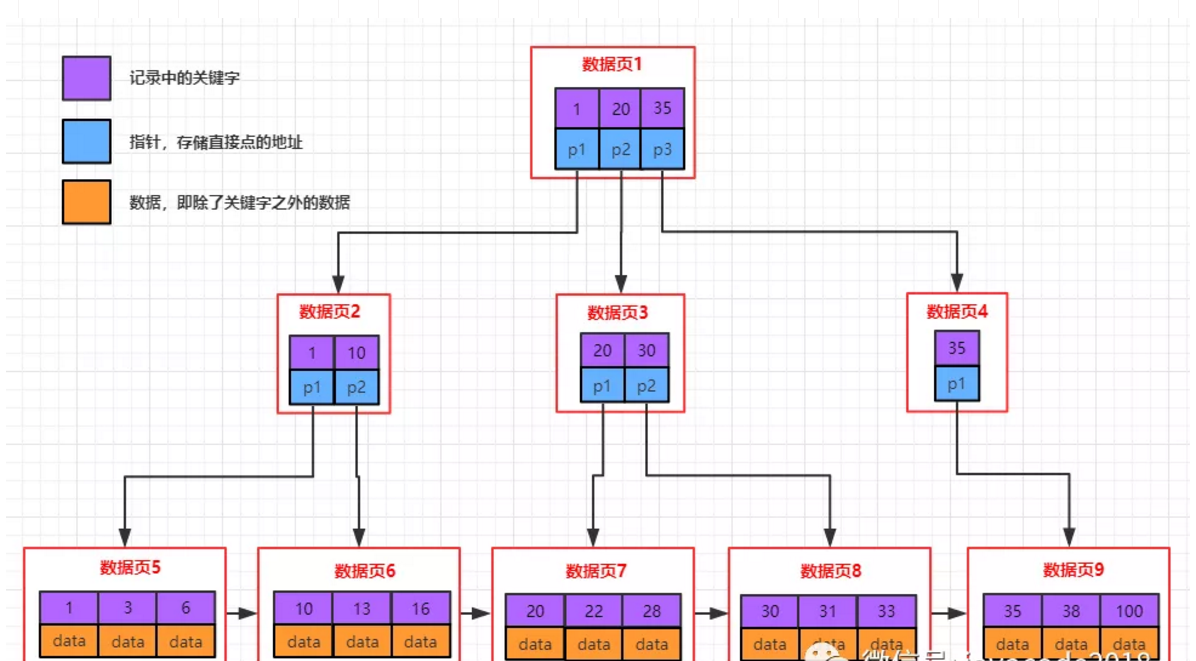
说一下b+树的几个特点:
-
叶子节点(最下面的一层)存储关键字(索引字段的值)信息及对应的data,叶子节点存储了所有记录的关键字信息
-
其他非叶子节点只存储关键字的信息及子节点的指针
-
每个叶子节点相当于mysql中的一页,同层级的叶子节点以双向链表的形式相连
-
每个节点(页)中存储了多条记录,记录之间用单链表的形式连接组成了一条有序的链表,顺序是按照索引字段排序的
-
b+树中检索数据时:每次检索都是从根节点开始,一直需要搜索到叶子节点
InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读取一条记录的时候,并不是将这个记录本身从磁盘读取出来,而是以页为单位,将整个也加载到内存中,一个页中可能有很多记录,然后在内存中对页进行检索。在innodb中,每个页的大小默认是16kb。
一、Mysql中索引分为
聚集索引(主键索引)
每个表一定会有一个聚集索引,整个表的数据存储以b+树的方式存在文件中,b+树叶子节点中的key为主键值,data为完整记录的信息;非叶子节点存储主键的值。
通过聚集索引检索数据只需要按照b+树的搜索过程,即可以检索到对应的记录。
非聚集索引
每个表可以有多个非聚集索引,b+树结构,叶子节点的key为索引字段字段的值,data为主键的值;非叶子节点只存储索引字段的值。
通过非聚集索引检索记录的时候,需要2次操作,先在非聚集索引中检索出主键,然后再到聚集索引中检索出主键对应的记录,该过程比聚集索引多了一次操作。
通常说的这个查询走索引了是什么意思?
当我们对某个字段的值进行某种检索的时候,如果这个检索过程中,我们能够快速定位到目标数据所在的页,有效的降低页的io操作,而不需要去扫描所有的数据页的时候,我们认为这种情况能够有效的利用索引,也称这个检索可以走索引,如果这个过程中不能够确定数据在那些页中,我们认为这种情况下索引对这个查询是无效的,此查询不走索引。
b+树中数据检索过程
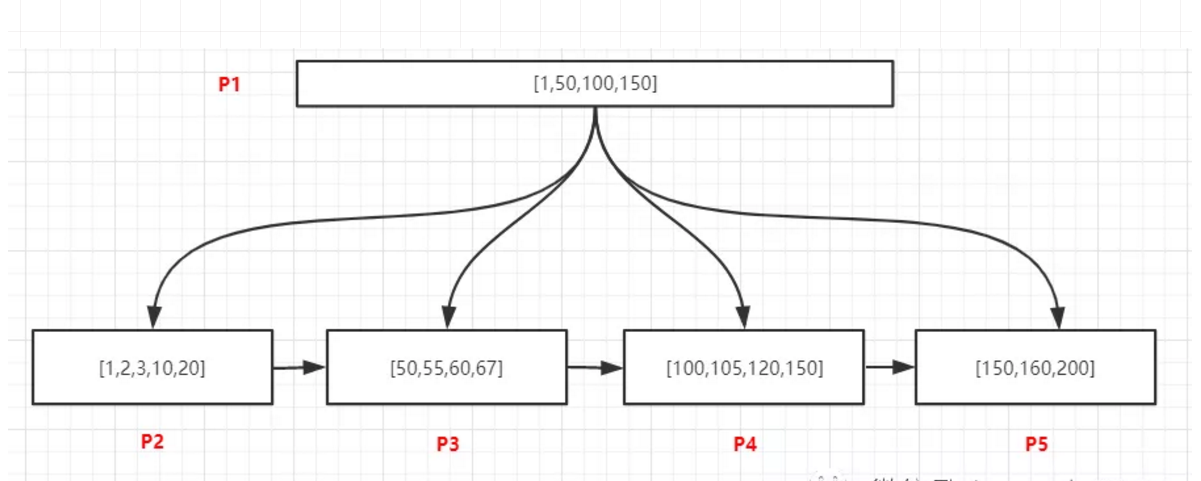
如上图,所有的数据都是唯一的,查询105的记录,过程如下:
-
将P1页加载到内存
-
在内存中采用二分法查找,可以确定105位于[100,150)中间,所以我们需要去加载100关联P4页
-
将P4加载到内存中,采用二分法找到105的记录后退出
查询某个值的所有记录
如上图,查询105的所有记录,过程如下:
-
将P1页加载到内存
-
在内存中采用二分法查找,可以确定105位于[100,150)中间,100关联P4页
-
将P4加载到内存中,采用二分法找到最有一个小于105的记录,即100,然后通过链表从100开始向后访问,找到所有的105记录,直到遇到第一个大于100的值为止
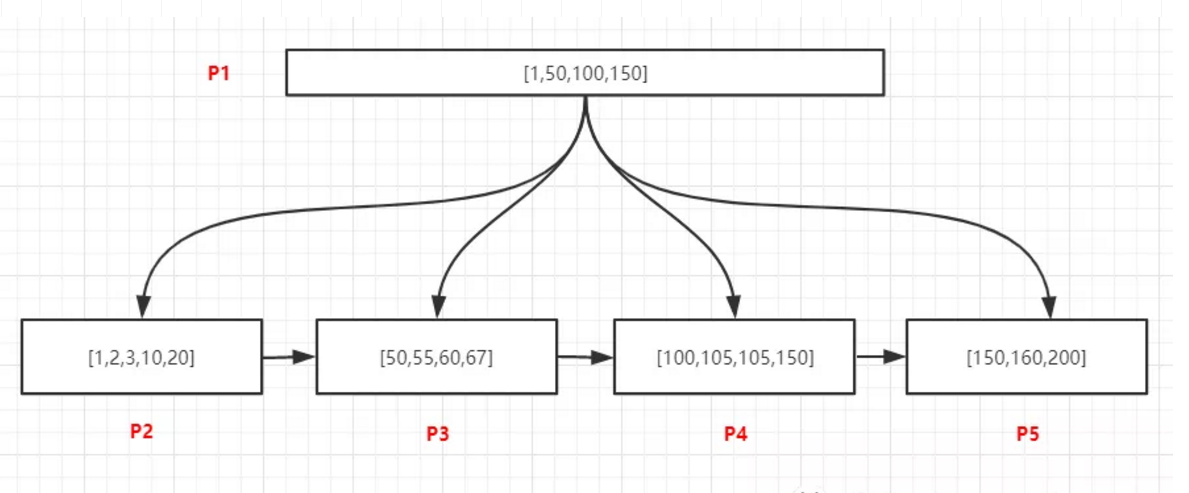
范围查找

数据如上图,查询[55,150]所有记录,由于页和页之间是双向链表升序结构,页内部的数据是单项升序链表结构,所以只用找到范围的起始值所在的位置,然后通过依靠链表访问两个位置之间所有的数据即可,过程如下:
-
将P1页加载到内存
-
内存中采用二分法找到55位于50关联的P3页中,150位于P5页中
-
将P3加载到内存中,采用二分法找到第一个55的记录,然后通过链表结构继续向后访问P3中的60、67,当P3访问完毕之后,通过P3的nextpage指针访问下一页P4中所有记录,继续遍历P4中的所有记录,直到访问到P5中所有的150为止。
模糊匹配
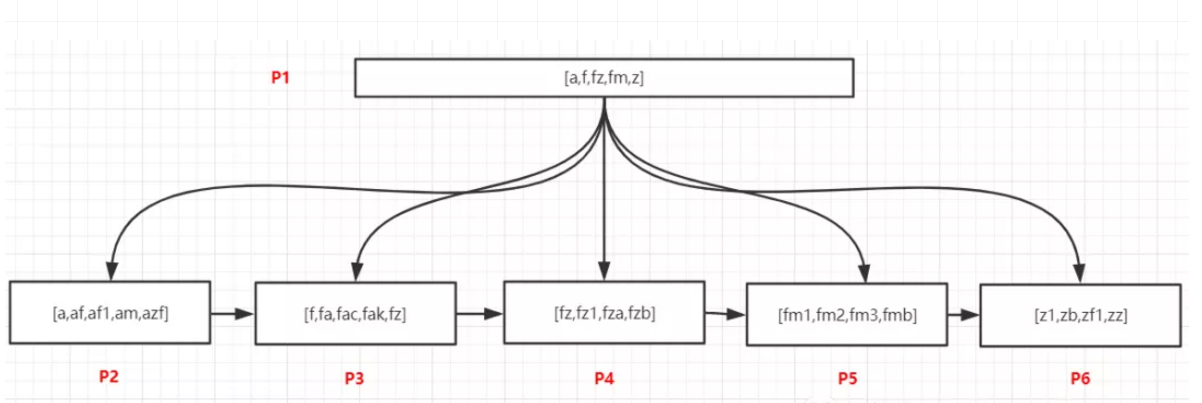
数据如上图。
查询以`f`开头的所有记录
过程如下:
-
将P1数据加载到内存中
-
在P1页的记录中采用二分法找到最后一个小于等于f的值,这个值是f,以及第一个大于f的,这个值是z,f指向叶节点P3,z指向叶节点P6,此时可以断定以f开头的记录可能存在于[P3,P6)这个范围的页内,即P3、P4、P5这三个页中
-
加载P3这个页,在内部以二分法找到第一条f开头的记录,然后以链表方式继续向后访问P4、P5中的记录,即可以找到所有已f开头的数据
查询包含`f`的记录
包含的查询在sql中的写法是%f%,通过索引我们还可以快速定位所在的页么?
可以看一下上面的数据,f在每个页中都存在,我们通过P1页中的记录是无法判断包含f的记录在那些页的,只能通过io的方式加载所有叶子节点,并且遍历所有记录进行过滤,才可以找到包含f的记录。
所以如果使用了%值%这种方式,索引对查询是无效的。
最左匹配原则
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
来一些示例我们体验一下。
下图中是3个字段(a,b,c)的联合索引,索引中数据的顺序是以a asc,b asc,c asc这种排序方式存储在节点中的,索引先以a字段升序,如果a相同的时候,以b字段升序,b相同的时候,以c字段升序,节点中每个数据认真看一下。
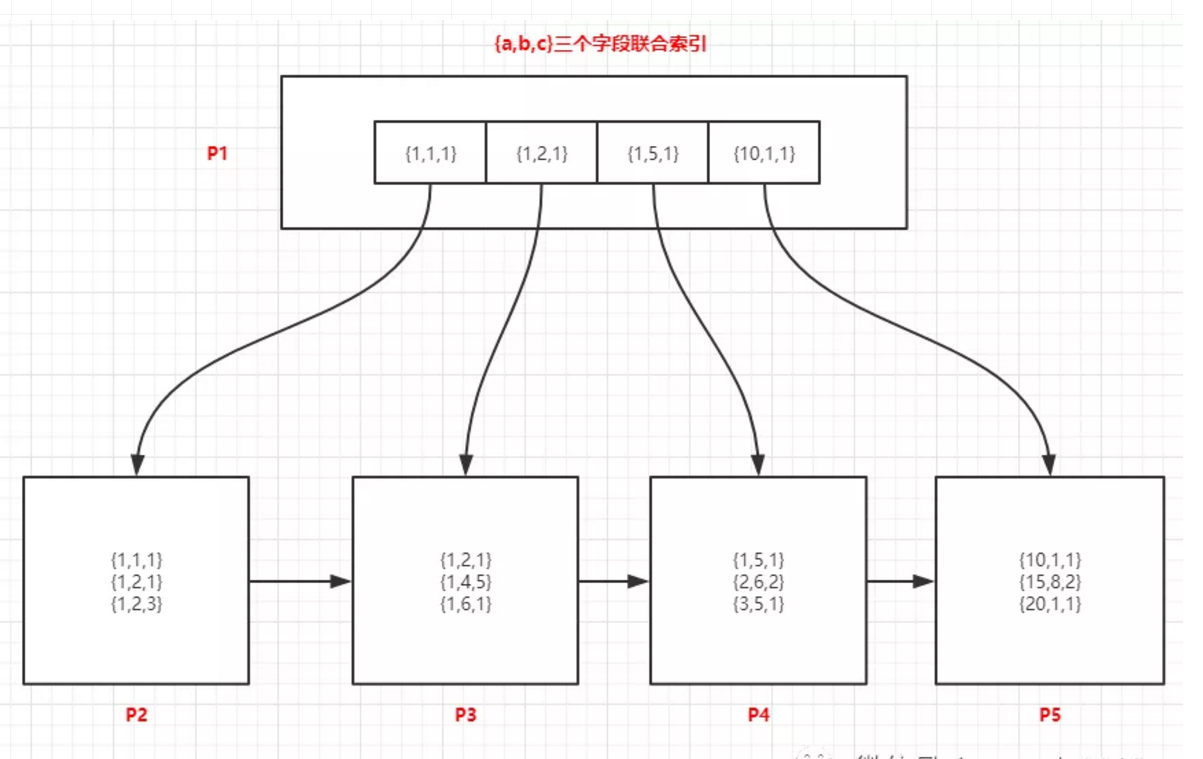
查询a=1的记录
由于页中的记录是以a asc,b asc,c asc这种排序方式存储的,所以a字段是有序的,可以通过二分法快速检索到,过程如下:
-
将P1加载到内存中
-
在内存中对P1中的记录采用二分法找,可以确定a=1的记录位于{1,1,1}和{1,5,1}关联的范围内,这两个值子节点分别是P2、P4
-
加载叶子节点P2,在P2中采用二分法快速找到第一条a=1的记录,然后通过链表向下一条及下一页开始检索,直到在P4中找到第一个不满足a=1的记录为止
查询a=1 and b=5的记录
方法和上面的一样,可以确定a=1 and b=5的记录位于{1,1,1}和{1,5,1}关联的范围内,查找过程和a=1查找步骤类似。
查询b=1的记录
这种情况通过P1页中的记录,是无法判断b=1的记录在那些页中的,只能加锁索引树所有叶子节点,对所有记录进行遍历,然后进行过滤,此时索引是无效的。
按照c的值查询
这种情况和查询b=1也一样,也只能扫描所有叶子节点,此时索引也无效了。
按照b和c一起查
这种也是无法利用索引的,也只能对所有数据进行扫描,一条条判断了,此时索引无效。
按照[a,c]两个字段查询
这种只能利用到索引中的a字段了,通过a确定索引范围,然后加载a关联的所有记录,再对c的值进行过滤。
查询a=1 and b>=0 and c=1的记录
这种情况只能先确定a=1 and b>=0所在页的范围,然后对这个范围的所有页进行遍历,c字段在这个查询的过程中,是无法确定c的数据在哪些页的,此时我们称c是不走索引的,只有a、b能够有效的确定索引页的范围。
类似这种的还有>、<、between and,多字段索引的情况下,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
上面说的各种情况,大家都多看一下图中数据,认真分析一下查询的过程,基本上都可以理解了。
上面这种查询叫做最左匹配原则。
索引区分度
我们看2个有序数组
[1,2,3,4,5,6,7,8,8,9,10]
[1,1,1,1,1,8,8,8,8,8]
上面2个数组是有序的,都是10条记录,如果我需要检索值为8的所有记录,那个更快一些?
咱们使用二分法查找包含8的所有记录过程如下:先使用二分法找到最后一个小于8的记录,然后沿着这条记录向后获取下一个记录,和8对比,知道遇到第一个大于8的数字结束,或者到达数组末尾结束。
采用上面这种方法找到8的记录,第一个数组中更快的一些。因为第二个数组中含有8的比例更多的,需要访问以及匹配的次数更多一些。
这里就涉及到数据的区分度问题:
索引区分度 = count(distint 记录) / count(记录)。
当索引区分度高的时候,检索数据更快一些,索引区分度太低,说明重复的数据比较多,检索的时候需要访问更多的记录才能够找到所有目标数据。
当索引区分度非常小的时候,基本上接近于全索引数据的扫描了,此时查询速度是比较慢的。
第一个数组索引区分度为1,第二个区分度为0.2,所以第一个检索更快的一些。
所以我们创建索引的时候,尽量选择区分度高的列作为索引。
正确使用索引
无索引检索效果
对数据进行全表扫描。
主键检索
这个速度很快,这个走的是上面介绍的`唯一记录检索`。
between and范围检索
速度也很快,id上有主键索引,这个采用的上面介绍的范围查找可以快速定位目标数据。
但是如果范围太大,跨度的page也太多,速度也会比较慢。所以使用between and的时候,区间跨度不要太大。
in的检索
in方式检索数据,我们还是经常用的。
平时我们做项目的时候,建议少用表连接,比如电商中需要查询订单的信息和订单中商品的名称,可以先查询查询订单表,然后订单表中取出商品的id列表,采用in的方式到商品表检索商品信息,由于商品id是商品表的主键,所以检索速度还是比较快的。
相当于多个分解为多个唯一记录检索,然后将记录合并。
多个索引时查询如何走?
我们在name、sex两个字段上分别建个索引
我们使用explain来看一下:
possible_keys:列出了这个查询可能会走两个索引(idx1、idx2)
实际上走的却是idx1(key列:实际走的索引)。
当多个条件中有索引的时候,并且关系是and的时候,会走索引区分度高的,显然name字段重复度很低,走name查询会更快一些。
模糊查询
name like '**%' 可以利用到name字段上面的索引
name like '%**%';下面的查询是无法确定需要查找的值所在的范围的,只能全表扫描,无法利用索引,所以速度比较慢。
回表
当需要查询的数据在索引树中不存在的时候,需要再次到聚集索引中去获取,这个过程叫做回表,如查询:
select * from test1 where name='**';
上面查询是
*,由于name列所在的索引中只有name、id两个列的值,不包含sex、email,所以上面过程如下:
走name索引检索
**对应的记录,取出id为3500000在主键索引中检索出
id=3500000的记录,获取所有字段的值
索引覆盖
查询中采用的索引树中包含了查询所需要的所有字段的值,不需要再去聚集索引检索数据,这种叫索引覆盖。
我们来看一个查询:
select id,name from test1 where name='**';
name对应idx1索引,id为主键,所以idx1索引树叶子节点中包含了name、id的值,这个查询只用走idx1这一个索引就可以了,如果select后面使用*,还需要一次回表获取sex、email的值。
所以写sql的时候,尽量避免使用*,*可能会多一次回表操作,需要看一下是否可以使用索引覆盖来实现,效率更高一些。
索引下推
简称ICP,Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式,ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
我们需要查询name以**开头的,性别为1的记录数,sql如下:
select count(id) from test1 a where name like '**%' and sex = 1;
过程:
-
走name索引检索出以**的第一条记录,得到记录的id
-
利用id去主键索引中查询出这条记录R1
-
判断R1中的sex是否为1,然后重复上面的操作,直到找到所有记录为止。
-
上面的过程中需要走name索引以及需要回表操作。
如果采用ICP的方式,我们可以这么做,创建一个(name,sex)的组合索引,查询过程如下:
-
走(name,sex)索引检索出以**的第一条记录,可以得到(name,sex,id),记做R1
-
判断R1.sex是否为1,然后重复上面的操作,知道找到所有记录为止
-
这个过程中不需要回表操作了,通过索引的数据就可以完成整个条件的过滤,速度比上面的更快一些。
数字使字符串类索引失效
select * from test1 where name = 1;
第三条用name和1比较,name上有索引,name是字符串类型,字符串和数字比较的时候,会将字符串强制转换为数字,然后进行比较,所以第二个查询变成了全表扫描,只能取出每条数据,将name转换为数字和1进行比较。
数字字段和字符串比较什么效果呢?如下:
select * from test1 where id = '4000000';
select * from test1 where id = 4000000;
id上面有主键索引,id是int类型的,可以看到,上面两个查询都非常快,都可以正常利用索引快速检索,所以如果字段是数组类型的,查询的值是字符串还是数组都会走索引。
函数使索引无效
select * from test1 a where concat(a.name,'1') = '**';
name上有索引,使用了函数之后,name所在的索引树是无法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然后对每条数据使用函数进行计算之后再进行条件判断,此时索引无效了,变成了全表数据扫描。
结论:索引字段使用函数查询使索引无效。
运算符使索引无效
select * from test1 a where id = 2 - 1;
select * from test1 a where id+1 = 2;
id上有主键索引,上面查询,第一个走索引,第二个不走索引,第二个使用运算符,id所在的索引树是无法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然后对每条数据的id进行计算之后再判断是否等于1,此时索引无效了,变成了全表数据扫描。
结论:索引字段使用了函数将使索引无效。
使用索引优化排序
我们有个订单表t_order(id,user_id,addtime,price),经常会查询某个用户的订单,并且按照addtime升序排序,应该怎么创建索引呢?我们来分析一下。
在user_id上创建索引,我们分析一下这种情况,数据检索的过程:
-
走user_id索引,找到记录的的id
-
通过id在主键索引中回表检索出整条数据
-
重复上面的操作,获取所有目标记录
-
在内存中对目标记录按照addtime进行排序
我们要知道当数据量非常大的时候,排序还是比较慢的,可能会用到磁盘中的文件,有没有一种方式,查询出来的数据刚好是排好序的。
我们再回顾一下mysql中b+树数据的结构,记录是按照索引的值排序组成的链表,如果将user_id和addtime放在一起组成联合索引(user_id,addtime),这样通过user_id检索出来的数据自然就是按照addtime排好序的,这样直接少了一步排序操作,效率更好,如果需addtime降序,只需要将结果翻转一下就可以了。
总结一下使用索引的一些建议
-
在区分度高的字段上面建立索引可以有效的使用索引,区分度太低,无法有效的利用索引,可能需要扫描所有数据页,此时和不使用索引差不多
-
联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
-
查询记录的时候,少使用*,尽量去利用索引覆盖,可以减少回表操作,提升效率
-
有些查询可以采用联合索引,进而使用到索引下推(IPC),也可以减少回表操作,提升效率
-
禁止对索引字段使用函数、运算符操作,会使索引失效
-
字符串字段和数字比较的时候会使索引无效
-
模糊查询'%值%'会使索引无效,变为全表扫描,但是'值%'这种可以有效利用索引
-
排序中尽量使用到索引字段,这样可以减少排序,提升查询效率