#pip install snownlp 插入自然语言处理库,文本处理库 import numpy as np import pandas as pd from snownlp import SnowNLP import matplotlib.pyplot as plt
#插入文本
hotel = pd.read_csv('hotel.csv', encoding='gb18030') hotel.head()
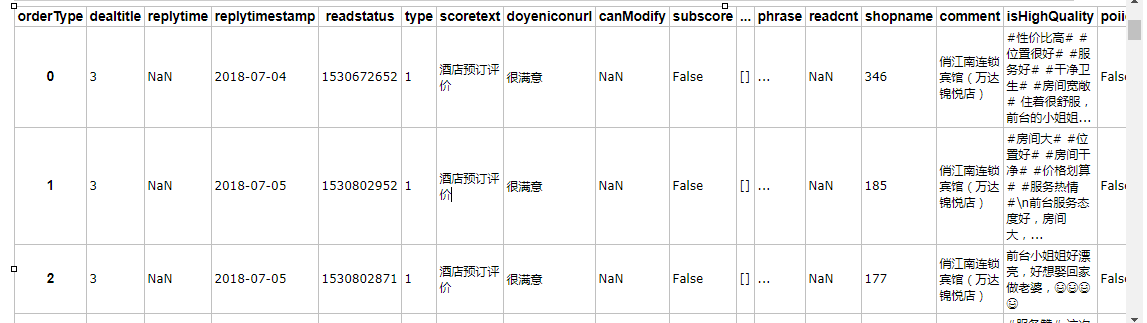
5 rows × 41 columns
#查看前五条评价
x = hotel['comment'].dropna() x.head()

x.index()是从列表中找出某个对象第一个匹配项的索引位置,如果这个对象不在列表中会报一个异常。L.index(obj[,start=0[,stop=len(L)]]),obj是查找到对象,start,可选参数,开始索引,默认为0,能单独指定;stop可选参数,结束索引,默认为列表长度,不能单独指定。
x.index

长度是小于索引的,说明可能是有缺失的
#显示第一个评价
text = x[0] text

#设置要测试的语句,
s = SnowNLP(text) for sentence in s.sentences: print(sentence)

s1 = SnowNLP(s.sentences[1]) #调用sentiments方法获取他的概率。
s1.sentiments
0.6955113989735859
#测试所有的字段
sentimentslist = [] for i in x.index: s1 = x[i] s = SnowNLP(s1) print (s.sentences) print (s.sentiments) sentimentslist.append(s.sentiments)

#将概率全部列出
sentimentslist

pd.Series(sentimentslist).mean()#求均值
0.5515285981366501
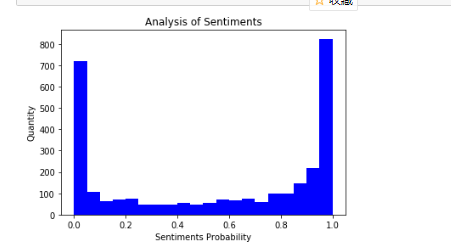
#画柱形图
plt.hist(sentimentslist, bins = 20, facecolor = 'blue') plt.xlabel('Sentiments Probability') plt.ylabel('Quantity') plt.title('Analysis of Sentiments') plt.show()
#pip install jieba #conda install wordcloud import matplotlib.pyplot as plt #词云 from scipy.misc import imread #图像处理 #from matplotlib.pyplot import imread from wordcloud import WordCloud import jieba, codecs from collections import Counter from wordcloud import WordCloud, ImageColorGenerator
import csv csv_reader = csv.reader(open('hotel.csv', encoding='gb18030')) #一般导入的时候还是需要加上编码类型,不然画图的时候就会发现标题等字段是乱码的
with open('hotel.csv','r',encoding='gb18030') as csvfile: reader = csv.reader(csvfile) column = [row[-7] for row in reader] print (column)

text = column[1:]
text

file=open('data.txt','w',encoding='utf-8') file.write(str(text)); file.close()
text = open('data.txt','r',encoding='utf-8').read()
' '.join(jieba.cut(text)) #精准匹配到.join

text = open('data.txt','r',encoding='utf-8').read() #文本数据 cut_text = ' '.join(jieba.cut(text)) print(cut_text) #color_mask = imread("tupian.png") cloud = WordCloud( font_path='C:WindowsFontsSTZHONGS.TTF', # 字体最好放在与脚本相同的目录下,而且必须设置 background_color='white', #mask=color_mask, max_words=2000, max_font_size=40 )

#画出词云
plt.figure(figsize=[20,8]) word_cloud = cloud.generate(cut_text) plt.imshow(word_cloud) plt.axis('off') plt.show()
