前言
Mongodb是一个非常有名的缓存数据库,和它名气相当的还有redis和hbase。笔者之前使用过redis,memcache和elasticsearch,借着工作机会,正好可以好好学习一下mongodb。
安装,部署
笔者在百度搜索下的mongodb官网上没有看到直接的下载链接,反而还要注册,比较麻烦。最后是在一篇博文里找到了直接的下载地址。直接选择一个较新的以msi为后缀的下载地址下载即可(笔者的环境是windows7 64位环境)。php的mongodb扩展也可搜索下载即可。在windows下每次启动mongodb需要在cmd进入对应目录启动,比较繁琐。按照这篇博文的做法,可以将mongodb注册为windows的一个服务,使用起来就非常的方便了。
笔者使用的ide是netbean8.2,在里面插件管理搜索mongodb可以找到一款小型的mongodb可视化插件,对于简单的mongodb管理已经足够了。
定义
MongoDB 是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。(来源:百度百科)
让我们来仔细分析下定义:
1)分布式文件存储。 这个名词听着就很厉害。顾名思义,就是存储的内容不在一台主机上,而是可以有多个节点主机,数据分散存在上面。 通过进一步查资料了解到, 对于客户端来说,无需知道数据被拆分了,也无需知道服务端哪个分片对应哪些数据。数据在分片之前需要运行一个路由进程,进程名为mongos。这个路由器知道所有数据的存放位置,知道数据和片的对应关系。好吧,的确很神奇。具体可以参考《浅谈MongoDB数据库分布式存储管理》。对于redis,也有类似的集群和分布式解决方案,比如Redis Sharding(应用时间较长)和Redis Cluster(redis3.0推出的官方解决方案),参考知乎的这个回答。
2)介于关系数据库和非关系数据库。
关系型数据库是指mongodb有着类似于传统关系型数据库的组织结构。参考下面的对比:
RDBMS: 数据库(DATABASE) ==》 表(TABLE) ==》 行(ROW) ==> 列(COLUMN)==》 表联合(TABLE JOI) ==>主键(PRIMARYKEY)
MONGODB:数据库(DATABASE) ==》 集合(COLLECTION) ==》 文档(DOCUMENT) ==> 字段(FIELD) ==》内嵌文档(embeded docment) ==>主键.key为_id(PRIMARYKEY)
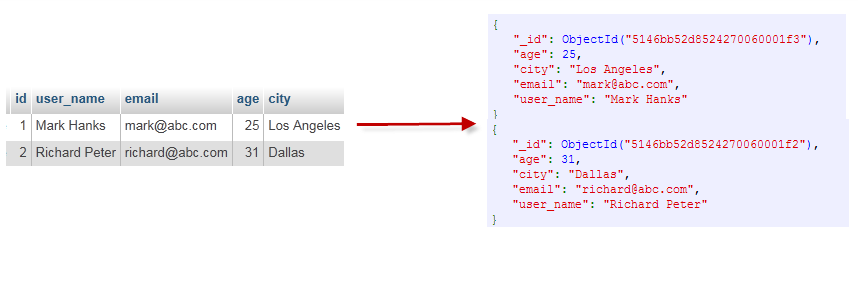
我们可以用类似于sql语句中的增删改查的语句去操作mongodb,虽然有些麻烦,但还是可以很快上手的。
另一方面。mongodb也是一个非关系型数据库。mongodb其实没有严格意义的行和列,而是将数据存储成文档。数据结构由键值(key=>value)对组成,MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
结构
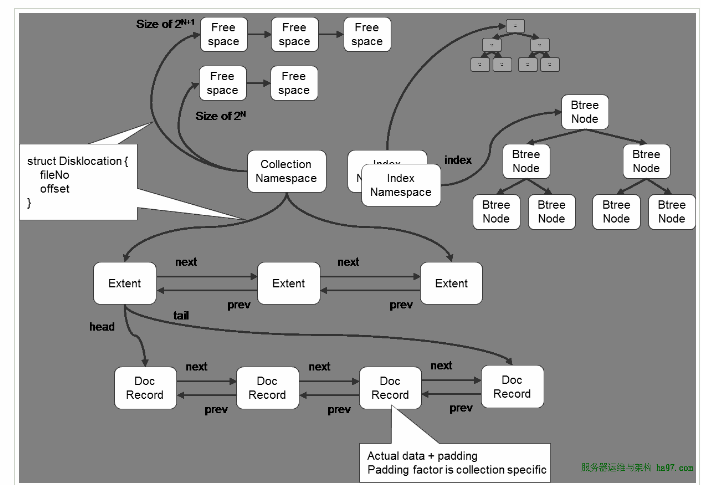
- MongoDB在数据存储上按命名空间来划分,一个collection是一个命名空间,一个索引也是一个命名空间
- 同一个命名空间的数据被分成很多个Extent,Extent之间使用双向链表连接
- 在每一个Extent中,保存了具体每一行的数据,这些数据也是通过双向链接连接的
- 每一行数据存储空间不仅包括数据占用空间,还可能包含一部分附加空间,这使得在数据update变大后可以不移动位置
- 索引以BTree结构实现
存储策略
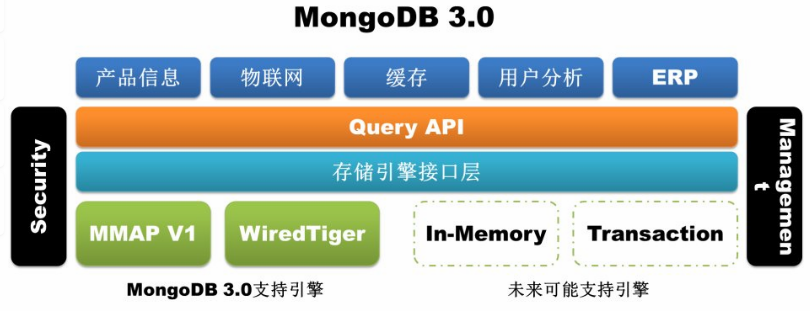
以上是mongodb3.0的数据存储模型。mongodb3.0开始支持WiredTiger存储引擎,In-Memory引擎也支持不过是企业级别需要收费。以下图标做个对比:
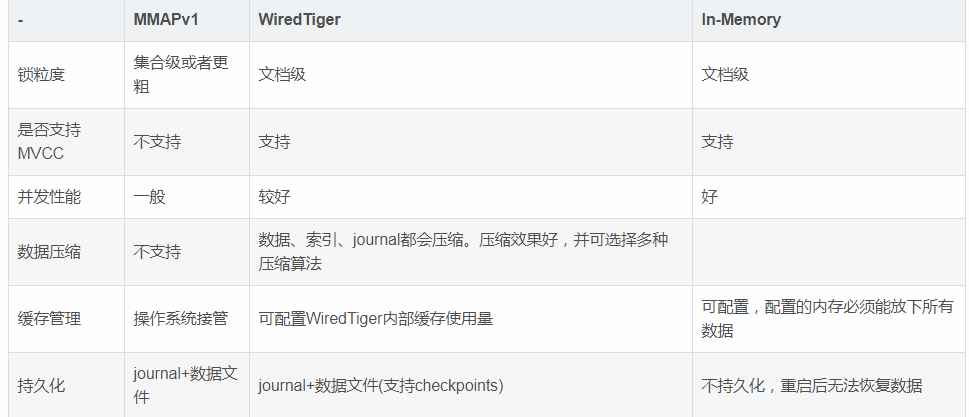
可以看到WiredTiger数据引擎,支持文档级锁(多个客户端可以并发的修改一个集合中多个不同的文档),提高了并发性。
对于持久化,WiredTiger的做法是:在一个操作开始时,WiredTiger会拷贝该时间点的事务数据快照(snapshot)。快照表示的是内存中数据的一份一致性的视图。WiredTiger也会以数据一致的方式将快照中的所有数据写到磁盘所有数据文件中,并且记录一个检查点(checkpoint),这个检查点还可以扮演恢复点(recovery points)的角色,当MongoDB崩溃重启后,MongoDB可以从最后有效的检查点进行恢复。
众所周知,mongodb的一大优势就是可以使用磁盘来存储数据。那么mongodb和操作系统,磁盘的数据交换机制是怎样的呢?参考这篇文章得到答案。虽然介绍的是MMAP存储引擎的机制。但也大同小异。利用操作系统的内存映射,映射到一个虚拟内存的区域。虚拟内存再对应物理内存,如果访问的数据不在物理内存中,则将数据从磁盘加载到物理内存中。
- 有了内存映射文件,要访问的数据就好像都在内存里面,简单化了MongoDB访问和修改数据的逻辑
- MongoDB读写都只是和虚拟内存打交道,剩下都交给OS打理
- MongoDB占用内存比redis高,一般适合大数据量存储
优缺点
优点:
- 类似于传统数据库的数据访问方式,支持索引,数据组织更加灵活;
- 官方提供了分片和主从复制的相关解决方案,使得在设置集群服务器方面更有优势;
- 适合大数据量存储,依赖系统虚拟内存,采用镜像文件存储;内存占用率比较高;
- 内置数据分析功能(mapreduce)
缺点:
- 访问的QPS不及redis;
- 不支持事务;
- 3.0版本以下,不要长时间占用写锁,会导致锁表。(3.0以上版本采用WiredTiger存储引擎,据说是document锁,不知道性能如何)。
总结
以上,只是我初次使用mongodb的一点学习总结,很多地方不完善,原理也不是很透彻,甚至不少是直接引用网上别人的文章语句。但我觉得,这也是一个自己学习思考的过程,有必要记录下来。毕竟信息爆炸的时代,不是每个人都有时间和有必要去重读官方文档和深入了解细节,毕竟自己的理解还没有到达那个高度,容易掉入纸上谈兵的陷阱。在以后具体项目用到的时候再进行学习和总结也会更加的深刻一些。
参考文档: