KMP算法主要用于解决包含问题,即存在两个字符串str1和str2,判断str1字符串中是否包含字符串str2,包含则返回str2对应在str1中的字符串的首字符的位置,否则返回-1;
例如:str1="abc123def" str2="123d" ,str1的长度为N, str2的长度为M,则返回3;
那么如何解决这类问题呢?正常的解法所用时间复杂度为O(N*M),即一个一个字符进行匹配,匹配不成功,则str1索引向后移动一位,str2重新从首字符进行匹配。
使用KMP算法解决这个问题的时间复杂度为O(N),默认M<N,如M>N,则不用匹配。
介绍KMP算法之前,我们来先介绍最长前缀和最长后缀:
例如 str="abcabcd" 求字符‘d’ 的最长前缀和最长后缀的匹配长度,先求字符'd'的前缀数组和后缀数组
d的前缀数组:“a”,"ab","abc","abca","abcab" 前缀数组中的字符串中不包含最后一个字符(即‘d’的前一个字符'c')
d的后缀数组:"c", "bc","abc","cabc","bcabc" 后缀数组中的字符串中不包含第一个字符(即首字符‘a’)
从上面可以看出字符‘d’ 的最长前缀和最长后缀的匹配长度为3,即均为"abc",则我们定义'd'字符上的位置(属于位置6)的next[6]=3;
依次我们来求next[0],next[1],next[2],next[3],next[4],next[5].
0位置和1位置上不存在前缀和后缀,因此我们人为定义next[0]=-1,next[1]=0;
针对位置2(字符‘c’),我们可以看出,前缀数组为:"a",后缀数组为:"b",显然最长前缀和最长后缀的匹配长度为0,故next[2]=0;
针对位置3(字符‘a’) ,我们可以看出,前缀数组为:"a","ab",后缀数组为:"c","bc",显然最长前缀和最长后缀的匹配长度为0,故next[3]=0;
针对位置4(字符‘b’) ,我们可以看出,前缀数组为:"a","ab","abc",后缀数组为:"a","ca","bca",显然最长前缀和最长后缀的匹配长度为1,故next[4]=1;
针对位置5(字符‘c’) ,我们可以看出,前缀数组为:"a","ab","abc","abca",后缀数组为:"b","ab","cab","bcab",显然最长前缀和最长后缀的匹配长度为2,故next[5]=2;
上面解释的KMP算法中next数组的来源,那么我们怎么用比较优秀的算法来求这个next数组呢?
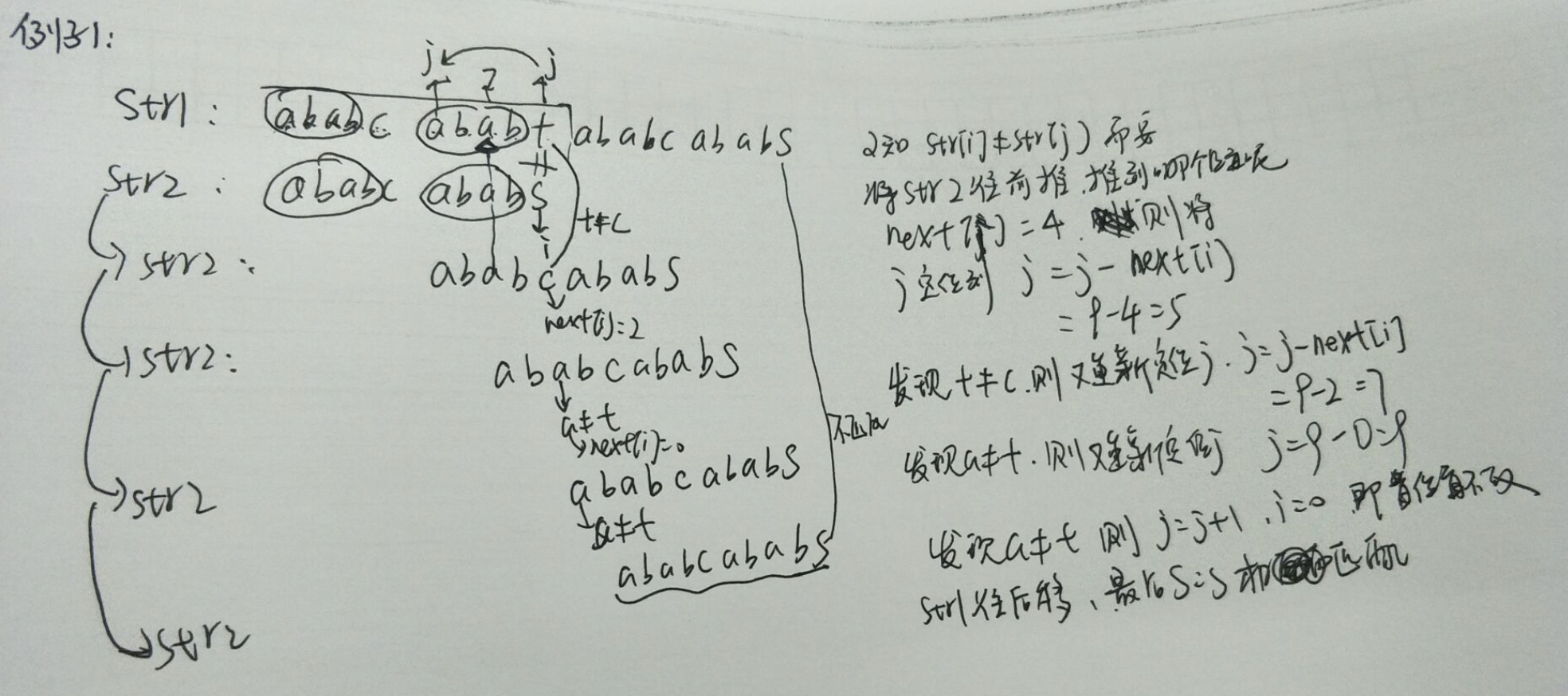
1)求next[i],需要根据next[i-1]来求,首先,定义cn = next[i-1],判断str[i-1]是否与str[cn]相等,
如例子1:str[i-1]==str[cn]=‘c’,则next[i]=cn+1=3,此处cn=next[i-1]=2
如例子2和3:str[i-1]!=str[cn],即'c'!='t' , 'c'!='a',此处cn =next[i-1]=4,此时将cn前跳,即cn = next[4]=2
继续比较str[i-1]是否等于str[cn],如例子2和3所示,例子3显示‘a’=='a',故针对例子3,next[i]=cn+1=3,
例子2显示‘a’!=t,故cn继续前跳,cn=next[cn]=next[2]=0;
例子2继续比较str[i-1]是否等于str[cn],此时‘a’!='t',cn继续前跳,发现已不能往前跳,故next[i]=0

求next数组代码如下所示:
//构造str2的next数组,规定next[0]=-1,next[1]=0; //ababcababtk ==> ababc ababtk,经过验证,以下代码为正确 public static int[] getNextArrays(String str) { char[] strs = str.toCharArray(); int[] next = new int[str.length()]; int cn = 0;//为前跳位置 next[0] = -1; next[1] = 0; int i = 2; while (i < next.length) { if (strs[i - 1] == strs[cn]) { next[i] = cn+1; i++; cn++; } else if (cn > 0) { cn = next[cn];//往前跳 } else { next[i] = 0; i++; } } return next; }
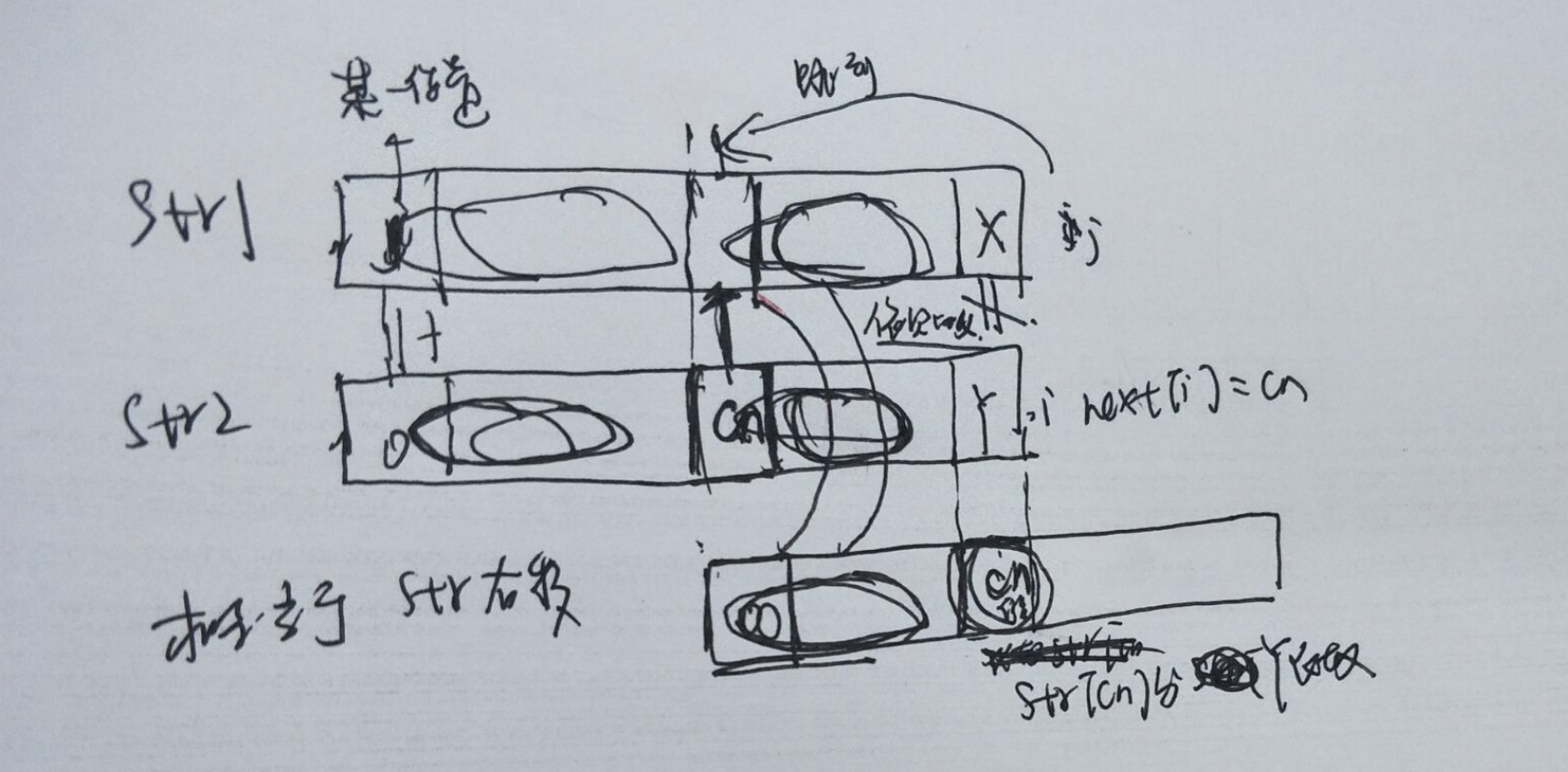
求完str2的next数组后,如何求的str2在str1字符串中所在的位置呢?此处是如何利用next数组进行加速处理的呢?
public static int getIndexOfString(String str1, String str2) { int next[] = getNextArrays(str2); char[] str1s = str1.toCharArray(); char[] str2s = str2.toCharArray(); int j = 0;//代表str1的索引 int i = 0;//代表str2的索引 while (i < str2.length() && j < str1.length()) { if (str2s[i] != str1s[j]&&j>-1) {//满足j>=0的要求 //当next[i]=0时,即i前面并没有最长前缀与最长后缀的匹配长度,此时从当前j位置开始比较起 //此处当next[i]=-1,j=0时,自动满足j=j+1。 j = j - next[i];//后退next[i]个字符,, i = 0;//重新开始比较 } else { i++; j++; } } if (i == str2.length()) {//说明全部比较完,且在str1中找到str2的字符串 return j - i; } else { return -1; } }