本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自【qq_33872191】的博客,感谢分享!以下为全文:
分两步:
第一步:实现hankcs.hanlp/corpus.io.IIOAdapter
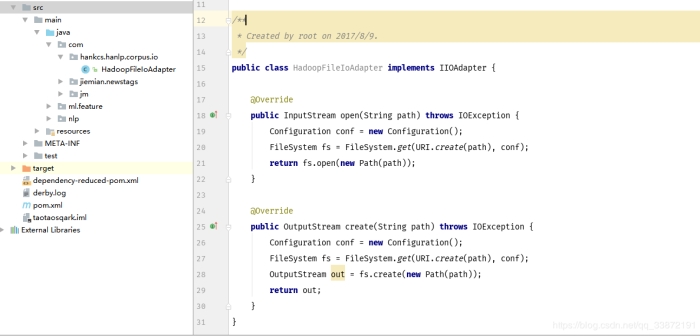
1.public class HadoopFileIoAdapter implements IIOAdapter {
2.
3. @Override
4. public InputStream open(String path) throws IOException {
5. Configuration conf = new Configuration();
6. FileSystem fs = FileSystem.get(URI.create(path), conf);
7. return fs.open(new Path(path));
8. }
9.
10. @Override
11. public OutputStream create(String path) throws IOException {
12. Configuration conf = new Configuration();
13. FileSystem fs = FileSystem.get(URI.create(path), conf);
14. OutputStream out = fs.create(new Path(path));
15. return out;
16. }
17. }
第二步:修改配置文件。root为hdfs上的数据包,把IOAdapter改为咱们上面实现的类


ok,这样你就能在分布式集群上使用hanlp进行分词了。
整个步骤比较简单,欢迎各位大神交流探讨!