1. mysql主从复制
(1) 为什么要做主从复制?
1、在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
2、做数据的热备
3、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
(2) 什么是mysql的主从复制
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
(3) 主从复制原理
1. master服务器将数据的改变记录在二进制binlog日志上,当master上的数据发生改变时,将其写入二进制文件中;
2. slave服务器会在一定时间间隔内对master二进制日志进行探测是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件
3. 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制时间,并保存至 从节点 本地的中继日志中,从节点 将启动sql线程从中继日志中读取二进制日志,在本地释放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒。
简单说:
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
(4) 需要注意的事
1) Master将操作语句记录到binlog日志中,然后授予slave远程连接的权限(master一定要开启binlog二进制日志功能,通常为了数据安全考虑,salve也开启binlog功能)
2) Slave开始俩个线程:IO线程和sql线程,其中:IO线程负责读取master的binlog内容到中继日志relay log里,sql线程负责从中继日志里读取binlog内容,并更新到slave的数据库,这样就能保持slave数据和master数据保持一致了
3) 至少有俩个Mysql的服务
4) 最好确保master和slave服务器上的Mysql版本相同,或者主服务器小于子服务器
5) Master和slave 俩节点时间需同步
(5) 主从复制延迟问题
原因:
mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高,
slave的sql thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随机的,不是顺序,所以成本要高很多,
另一方面,由于sql thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL thread所能处理的速度,
或者当slave中有大型query语句产生了锁等待,那么延时就产生了。
解决方案:
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
4.不同业务的mysql物理上放在不同机器,分散压力。
5.使用比主库更好的硬件设备作为slave,mysql压力小,延迟自然会变小。
6.使用更加强劲的硬件设备。
redis的主从复制
流程
1.全量复制
发生节点: 在slave 从服务器初始化阶段,需要将master主服务器上的所有数据都复制一份,流程如下:
-
从服务器连接主服务器,并发送sycn命令
-
主服务器接收到sycn命令后,执行bgsave命令生成RDB文件,并且在缓冲区中记录之后所有的操作记录
-
master执行完bgsave后,master将RDB文件发送给slave,并在此阶段内继续在缓冲区内写操作
-
slave在接收到RDB文件前 ,会将自身的数据全部丢弃,载入RDB
-
master发送完毕,会向slave 的缓冲区发 写入执行命令
-
slave 完成对RDB的载入,开始接受命令请求,并执行缓冲区的命令
2.增量复制
发生节点: 在slave完成初始化且开始正常工作后,master发生的写操作会同步到slave上
redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
操作
slave 执行以下命令
SLAVEOF 127.0.0.1 6379 【ip port】 使slave成为master 的从节点
特点
-
采用异步复制
-
一个master可以有多个slave,且一个slave下也可以有slave
-
在主从复制的过程中,master是非阻塞的,一直对外提供读写服务,slave只能对外提供读服务(可配置),不支持事务
-
当master宕机之后,整个服务停掉,只能提供读服务
-
当slave宕机重启之后,会向master发送sync指令进行全量同步,当有多个从服务器重启,会导致master IO剧增宕机
-
全量复制代价很大,所以尽力只在第一次初始化的时候做一次,在redis 2.8之后引入了部分复制
部分复制
部分复制是Redis 2.8以后出现的,用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制
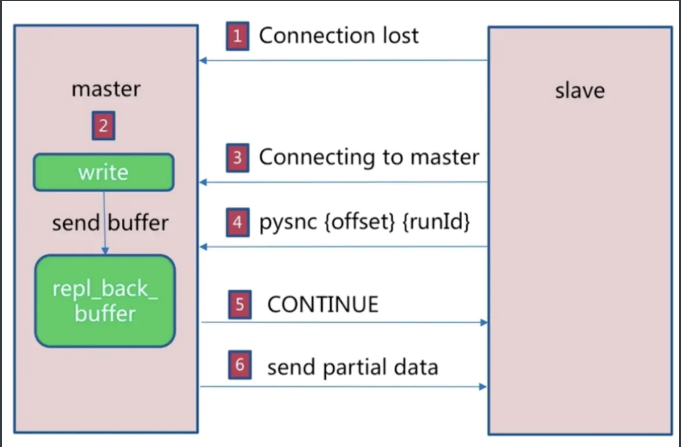
过程:
-
主机master 还是会写 repl_back_buffer(复制缓冲区)
-
从机slave 会继续尝试连接主机
-
从机slave 会把自己当前 run_id 和偏移量传输给主机 master,并且执行 pysnc 命令同步
-
如果master发现你的偏移量是在缓冲区的范围内,就会返回 continue命令
-
同步了offset的部分数据,所以部分复制的基础就是偏移量 offset。